 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Self-Supervised Learning of General Audio Representations
Paper and Code
Apr 28, 2021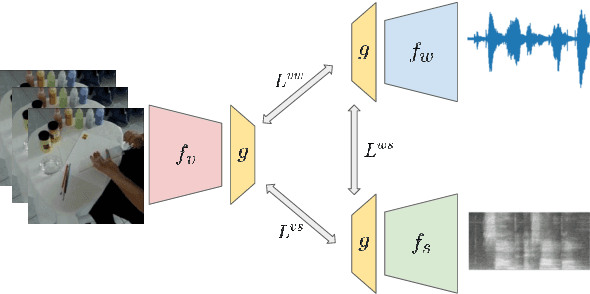

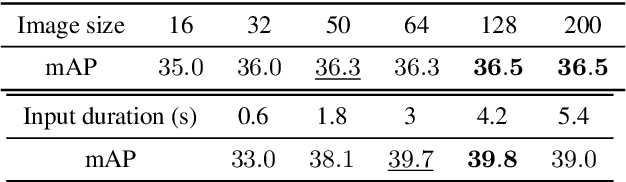

We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.