 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022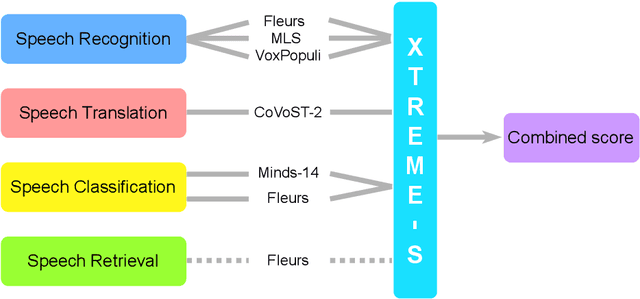
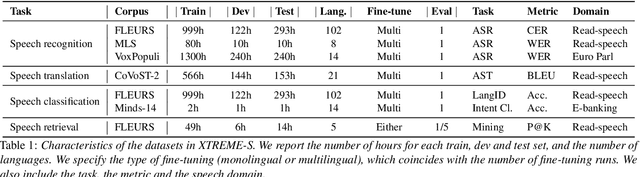
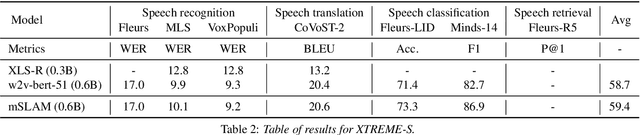
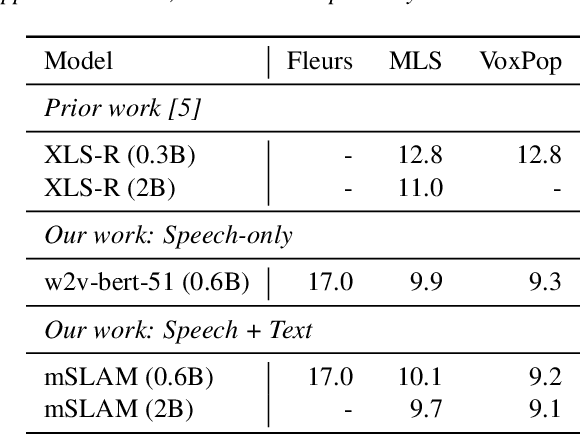
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
mSLAM: Massively multilingual joint pre-training for speech and text
Feb 03, 2022



We present mSLAM, a multilingual Speech and LAnguage Model that learns cross-lingual cross-modal representations of speech and text by pre-training jointly on large amounts of unlabeled speech and text in multiple languages. mSLAM combines w2v-BERT pre-training on speech with SpanBERT pre-training on character-level text, along with Connectionist Temporal Classification (CTC) losses on paired speech and transcript data, to learn a single model capable of learning from and representing both speech and text signals in a shared representation space. We evaluate mSLAM on several downstream speech understanding tasks and find that joint pre-training with text improves quality on speech translation, speech intent classification and speech language-ID while being competitive on multilingual ASR, when compared against speech-only pre-training. Our speech translation model demonstrates zero-shot text translation without seeing any text translation data, providing evidence for cross-modal alignment of representations. mSLAM also benefits from multi-modal fine-tuning, further improving the quality of speech translation by directly leveraging text translation data during the fine-tuning process. Our empirical analysis highlights several opportunities and challenges arising from large-scale multimodal pre-training, suggesting directions for future research.
SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021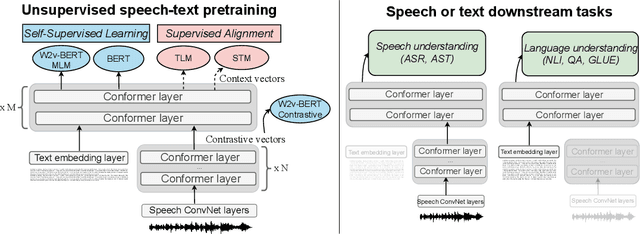
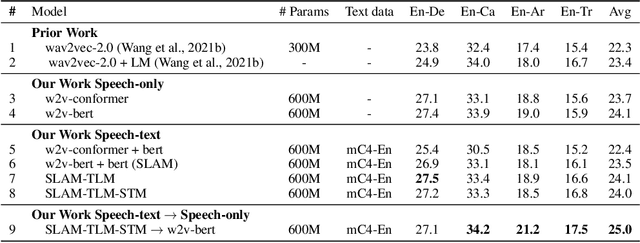
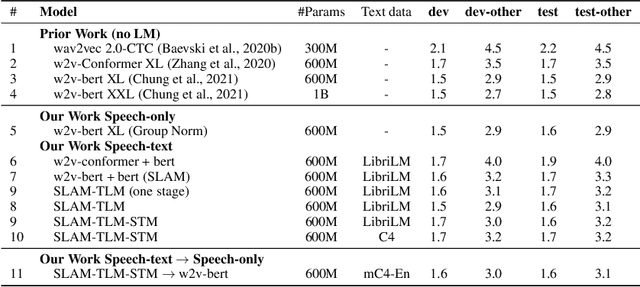
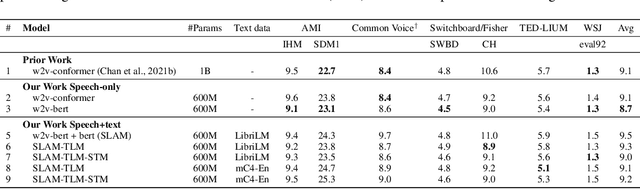
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.
Improving Multilingual Models with Language-Clustered Vocabularies
Oct 24, 2020
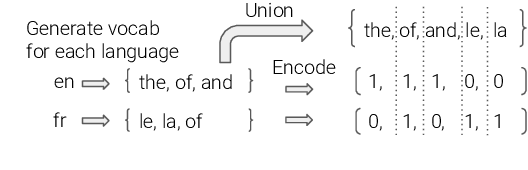
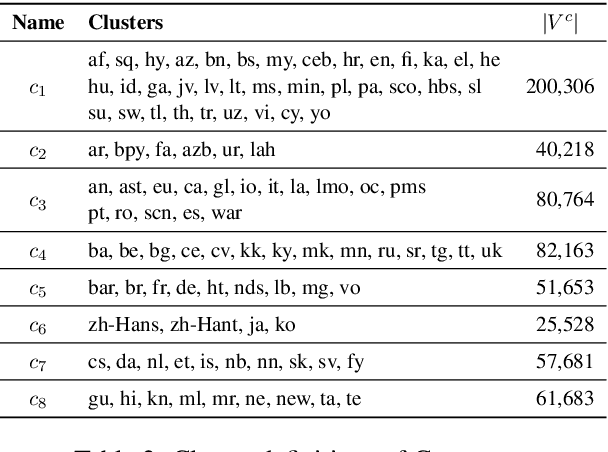
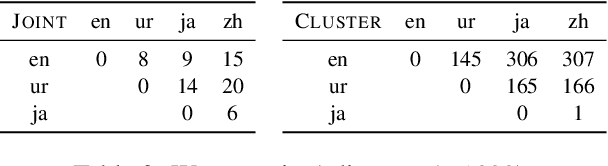
State-of-the-art multilingual models depend on vocabularies that cover all of the languages the model will expect to see at inference time, but the standard methods for generating those vocabularies are not ideal for massively multilingual applications. In this work, we introduce a novel procedure for multilingual vocabulary generation that combines the separately trained vocabularies of several automatically derived language clusters, thus balancing the trade-off between cross-lingual subword sharing and language-specific vocabularies. Our experiments show improvements across languages on key multilingual benchmark tasks TyDi QA (+2.9 F1), XNLI (+2.1\%), and WikiAnn NER (+2.8 F1) and factor of 8 reduction in out-of-vocabulary rate, all without increasing the size of the model or data.
Finding Fast Transformers: One-Shot Neural Architecture Search by Component Composition
Aug 15, 2020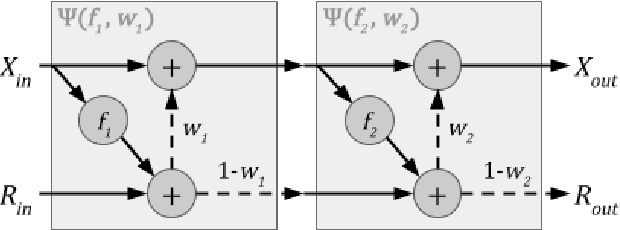
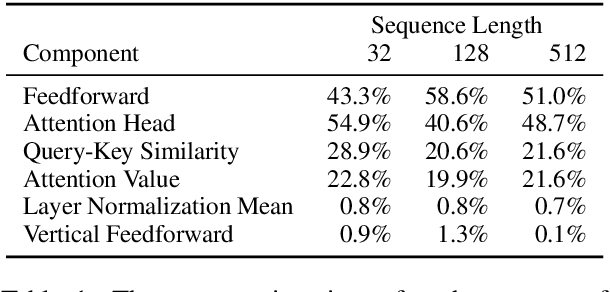
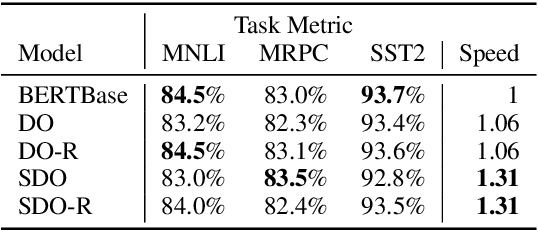
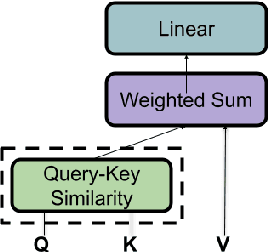
Transformer-based models have achieved stateof-the-art results in many tasks in natural language processing. However, such models are usually slow at inference time, making deployment difficult. In this paper, we develop an efficient algorithm to search for fast models while maintaining model quality. We describe a novel approach to decompose the Transformer architecture into smaller components, and propose a sampling-based one-shot architecture search method to find an optimal model for inference. The model search process is more efficient than alternatives, adding only a small overhead to training time. By applying our methods to BERT-base architectures, we achieve 10% to 30% speedup for pre-trained BERT and 70% speedup on top of a previous state-of-the-art distilled BERT model on Cloud TPU-v2 with a generally acceptable drop in performance.
Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation
Sep 01, 2019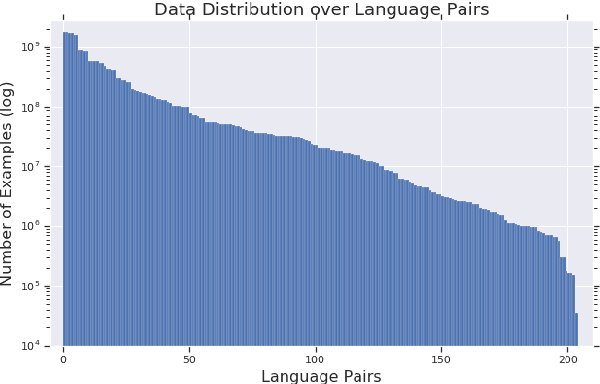
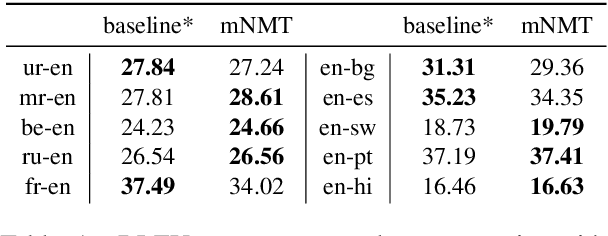
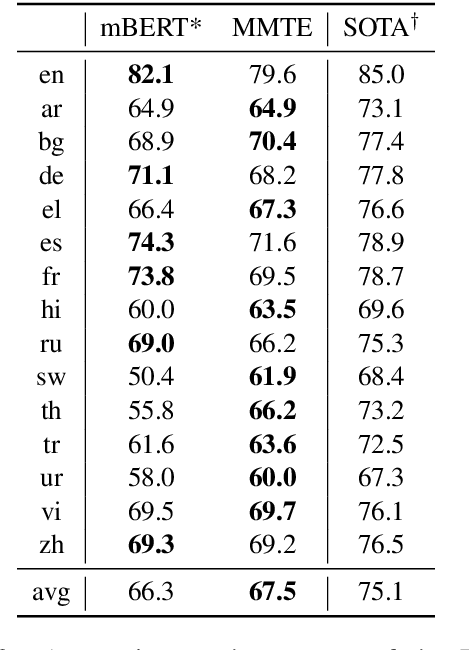
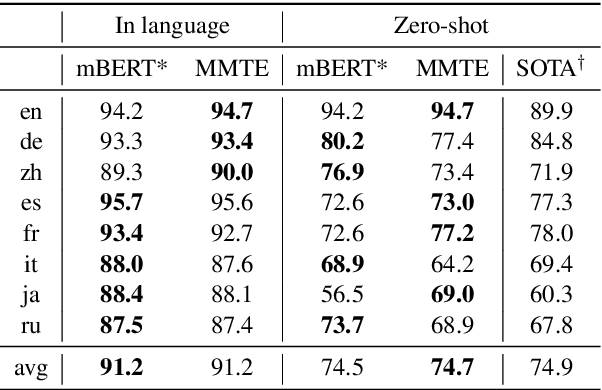
The recently proposed massively multilingual neural machine translation (NMT) system has been shown to be capable of translating over 100 languages to and from English within a single model. Its improved translation performance on low resource languages hints at potential cross-lingual transfer capability for downstream tasks. In this paper, we evaluate the cross-lingual effectiveness of representations from the encoder of a massively multilingual NMT model on 5 downstream classification and sequence labeling tasks covering a diverse set of over 50 languages. We compare against a strong baseline, multilingual BERT (mBERT), in different cross-lingual transfer learning scenarios and show gains in zero-shot transfer in 4 out of these 5 tasks.
Small and Practical BERT Models for Sequence Labeling
Aug 31, 2019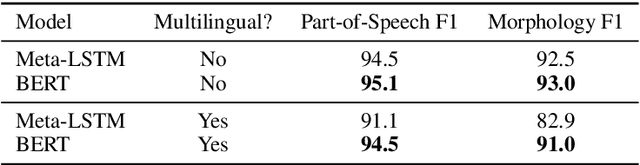
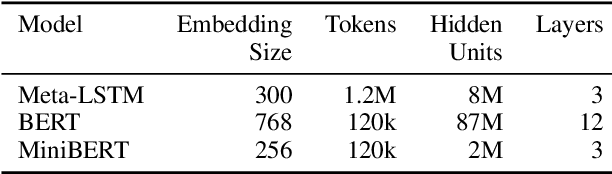


We propose a practical scheme to train a single multilingual sequence labeling model that yields state of the art results and is small and fast enough to run on a single CPU. Starting from a public multilingual BERT checkpoint, our final model is 6x smaller and 27x faster, and has higher accuracy than a state-of-the-art multilingual baseline. We show that our model especially outperforms on low-resource languages, and works on codemixed input text without being explicitly trained on codemixed examples. We showcase the effectiveness of our method by reporting on part-of-speech tagging and morphological prediction on 70 treebanks and 48 languages.
A Fast, Compact, Accurate Model for Language Identification of Codemixed Text
Oct 09, 2018
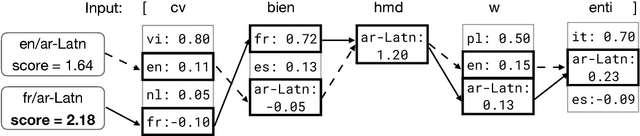
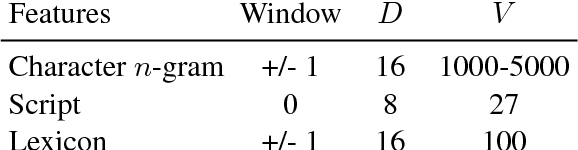
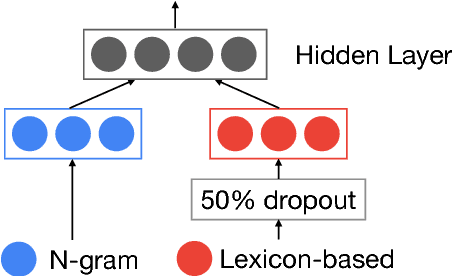
We address fine-grained multilingual language identification: providing a language code for every token in a sentence, including codemixed text containing multiple languages. Such text is prevalent online, in documents, social media, and message boards. We show that a feed-forward network with a simple globally constrained decoder can accurately and rapidly label both codemixed and monolingual text in 100 languages and 100 language pairs. This model outperforms previously published multilingual approaches in terms of both accuracy and speed, yielding an 800x speed-up and a 19.5% averaged absolute gain on three codemixed datasets. It furthermore outperforms several benchmark systems on monolingual language identification.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Oct 08, 2016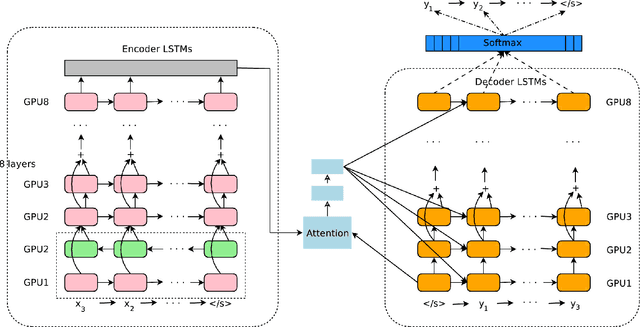

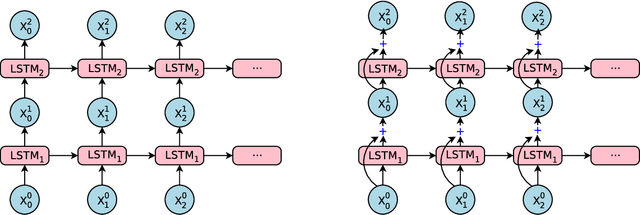
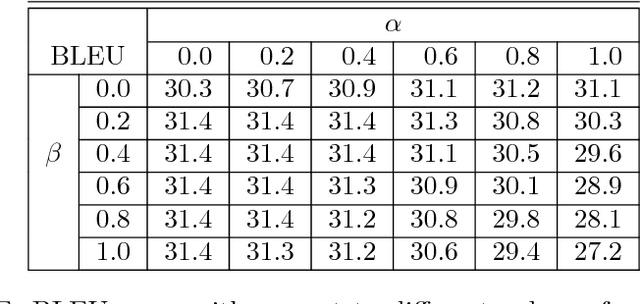
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system.