 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for Acyclic Weighted Finite-State Automata with Failure Arcs
Jan 17, 2023Weighted finite-state automata (WSFAs) are commonly used in NLP. Failure transitions are a useful extension for compactly representing backoffs or interpolation in $n$-gram models and CRFs, which are special cases of WFSAs. The pathsum in ordinary acyclic WFSAs is efficiently computed by the backward algorithm in time $O(|E|)$, where $E$ is the set of transitions. However, this does not allow failure transitions, and preprocessing the WFSA to eliminate failure transitions could greatly increase $|E|$. We extend the backward algorithm to handle failure transitions directly. Our approach is efficient when the average state has outgoing arcs for only a small fraction $s \ll 1$ of the alphabet $\Sigma$. We propose an algorithm for general acyclic WFSAs which runs in $O{\left(|E| + s |\Sigma| |Q| T_\text{max} \log{|\Sigma|}\right)}$, where $Q$ is the set of states and $T_\text{max}$ is the size of the largest connected component of failure transitions. When the failure transition topology satisfies a condition exemplified by CRFs, the $T_\text{max}$ factor can be dropped, and when the weight semiring is a ring, the $\log{|\Sigma|}$ factor can be dropped. In the latter case (ring-weighted acyclic WFSAs), we also give an alternative algorithm with complexity $\displaystyle O{\left(|E| + |\Sigma| |Q| \min(1,s\pi_\text{max}) \right)}$, where $\pi_\text{max}$ is the size of the longest failure path.
Privacy-Preserving Domain Adaptation of Semantic Parsers
Dec 20, 2022



Task-oriented dialogue systems often assist users with personal or confidential matters. For this reason, the developers of such a system are generally prohibited from observing actual usage. So how can they know where the system is failing and needs more training data or new functionality? In this work, we study ways in which realistic user utterances can be generated synthetically, to help increase the linguistic and functional coverage of the system, without compromising the privacy of actual users. To this end, we propose a two-stage Differentially Private (DP) generation method which first generates latent semantic parses, and then generates utterances based on the parses. Our proposed approach improves MAUVE by 3.8$\times$ and parse tree node-type overlap by 1.4$\times$ relative to current approaches for private synthetic data generation, improving both on fluency and semantic coverage. We further validate our approach on a realistic domain adaptation task of adding new functionality from private user data to a semantic parser, and show gains of 1.3$\times$ on its accuracy with the new feature.
A Measure-Theoretic Characterization of Tight Language Models
Dec 20, 2022
Language modeling, a central task in natural language processing, involves estimating a probability distribution over strings. In most cases, the estimated distribution sums to 1 over all finite strings. However, in some pathological cases, probability mass can ``leak'' onto the set of infinite sequences. In order to characterize the notion of leakage more precisely, this paper offers a measure-theoretic treatment of language modeling. We prove that many popular language model families are in fact tight, meaning that they will not leak in this sense. We also generalize characterizations of tightness proposed in previous works.
Contrastive Decoding: Open-ended Text Generation as Optimization
Oct 27, 2022Likelihood, although useful as a training loss, is a poor search objective for guiding open-ended generation from language models (LMs). Existing generation algorithms must avoid both unlikely strings, which are incoherent, and highly likely ones, which are short and repetitive. We propose contrastive decoding (CD), a more reliable search objective that returns the difference between likelihood under a large LM (called the expert, e.g. OPT-13b) and a small LM (called the amateur, e.g. OPT-125m). CD is inspired by the fact that the failures of larger LMs are even more prevalent in smaller LMs, and that this difference signals exactly which texts should be preferred. CD requires zero training, and produces higher quality text than decoding from the larger LM alone. It also generalizes across model types (OPT and GPT2) and significantly outperforms four strong decoding algorithms in automatic and human evaluations.
The Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding
Sep 16, 2022
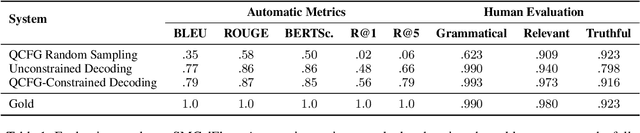
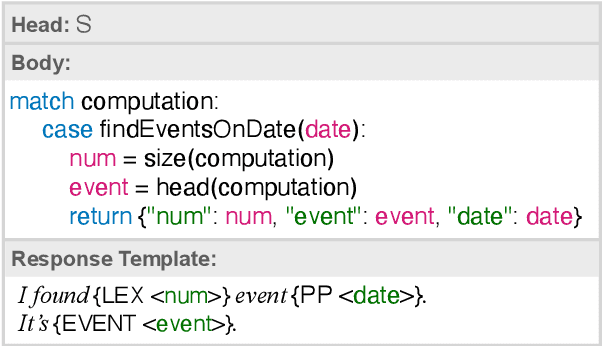
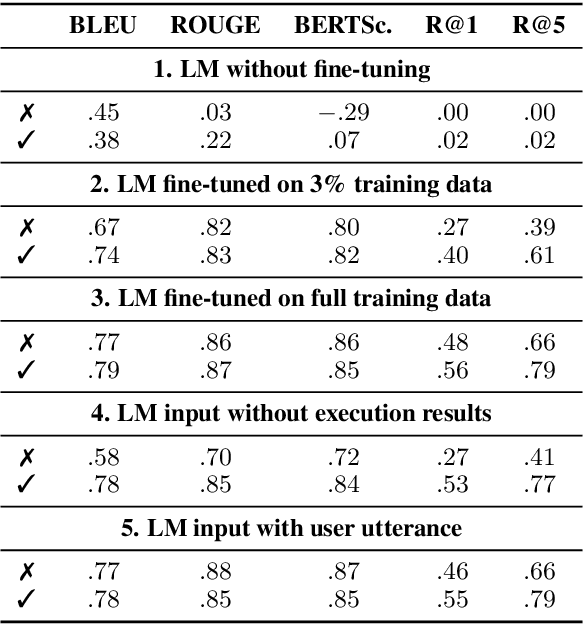
In a real-world dialogue system, generated responses must satisfy several interlocking constraints: being informative, truthful, and easy to control. The two predominant paradigms in language generation -- neural language modeling and rule-based generation -- both struggle to satisfy these constraints. Even the best neural models are prone to hallucination and omission of information, while existing formalisms for rule-based generation make it difficult to write grammars that are both flexible and fluent. We describe a hybrid architecture for dialogue response generation that combines the strengths of both approaches. This architecture has two components. First, a rule-based content selection model defined using a new formal framework called dataflow transduction, which uses declarative rules to transduce a dialogue agent's computations (represented as dataflow graphs) into context-free grammars representing the space of contextually acceptable responses. Second, a constrained decoding procedure that uses these grammars to constrain the output of a neural language model, which selects fluent utterances. The resulting system outperforms both rule-based and learned approaches in human evaluations of fluency, relevance, and truthfulness.
On the Intersection of Context-Free and Regular Languages
Sep 14, 2022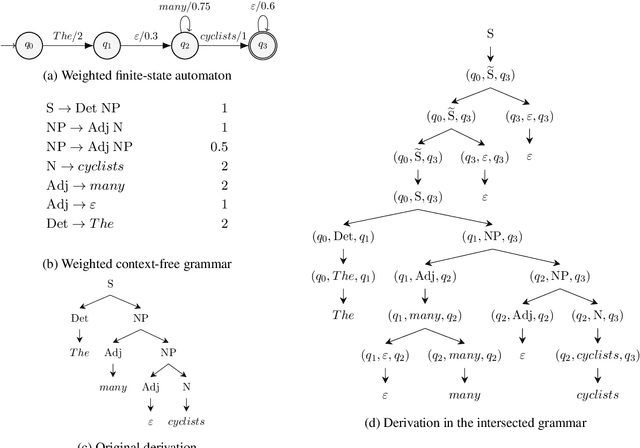
The Bar-Hillel construction is a classic result in formal language theory. It shows, by construction, that the intersection between a context-free language and a regular language is itself context-free. However, neither its original formulation (Bar-Hillel et al., 1961) nor its weighted extension (Nederhof and Satta, 2003) can handle automata with $\epsilon$-arcs. In this short note, we generalize the Bar-Hillel construction to correctly compute the intersection even when the automaton contains $\epsilon$-arcs. We further prove that our generalized construction leads to a grammar that encodes the structure of both the input automaton and grammar while retaining the asymptotic size of the original construction.
BenchCLAMP: A Benchmark for Evaluating Language Models on Semantic Parsing
Jun 21, 2022
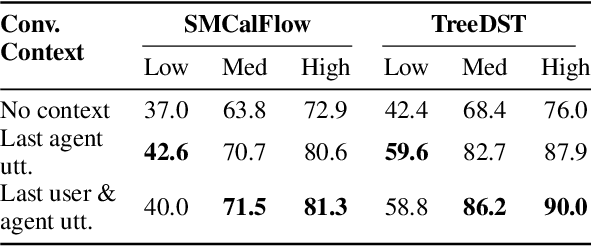
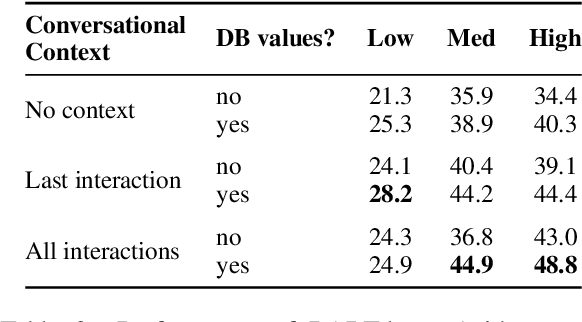

We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, which produces semantic outputs based on the analysis of input text through constrained decoding of a prompted or fine-tuned language model. Developers of pretrained language models currently benchmark on classification, span extraction and free-text generation tasks. Semantic parsing is neglected in language model evaluation because of the complexity of handling task-specific architectures and representations. Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. BenchCLAMP includes context-free grammars for six semantic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports both prompt-based learning as well as fine-tuning, and provides an easy-to-use toolkit for language model developers to evaluate on semantic parsing.
Active Programming by Example with a Natural Language Prior
May 25, 2022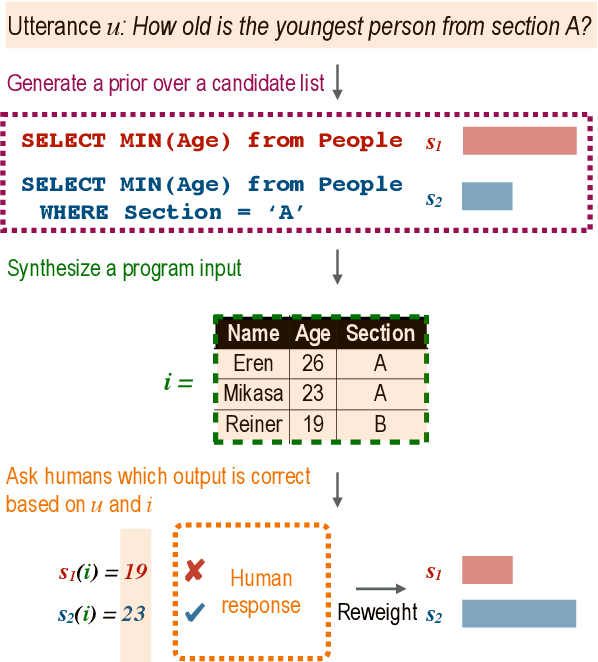
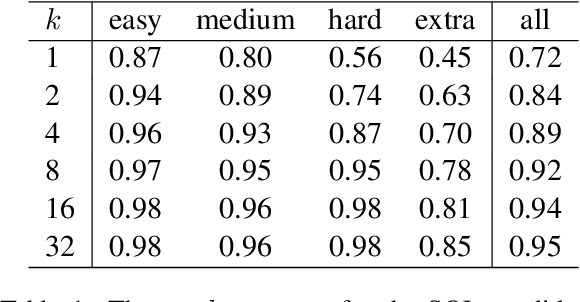

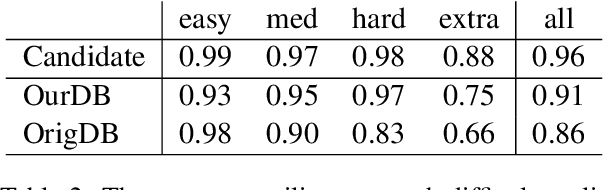
We introduce APEL, a new framework that enables non-programmers to indirectly annotate natural language utterances with executable meaning representations, such as SQL programs. Based on a natural language utterance, we first run a seed semantic parser to generate a prior over a list of candidate programs. To obtain information about which candidate is correct, we synthesize an input on which the more likely programs tend to produce different outputs, and ask an annotator which output is appropriate for the utterance. Hence, the annotator does not have to directly inspect the programs. To further reduce effort required from annotators, we aim to synthesize simple input databases that nonetheless have high information gain. With human annotators and Bayesian inference to handle annotation errors, we outperform Codex's top-1 performance (59%) and achieve the same accuracy as the original expert annotators (75%), by soliciting answers for each utterance on only 2 databases with an average of 9 records each. In contrast, it would be impractical to solicit outputs on the original 30K-record databases provided by SPIDER
When More Data Hurts: A Troubling Quirk in Developing Broad-Coverage Natural Language Understanding Systems
May 24, 2022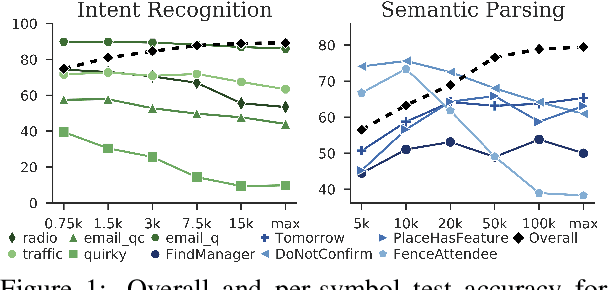


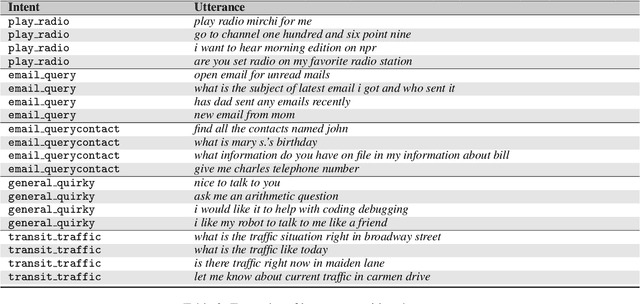
In natural language understanding (NLU) production systems, users' evolving needs necessitate the addition of new features over time, indexed by new symbols added to the meaning representation space. This requires additional training data and results in ever-growing datasets. We present the first systematic investigation into this incremental symbol learning scenario. Our analyses reveal a troubling quirk in building (broad-coverage) NLU systems: as the training dataset grows, more data is needed to learn new symbols, forming a vicious cycle. We show that this trend holds for multiple mainstream models on two common NLU tasks: intent recognition and semantic parsing. Rejecting class imbalance as the sole culprit, we reveal that the trend is closely associated with an effect we call source signal dilution, where strong lexical cues for the new symbol become diluted as the training dataset grows. Selectively dropping training examples to prevent dilution often reverses the trend, showing the over-reliance of mainstream neural NLU models on simple lexical cues and their lack of contextual understanding.
Transformer Embeddings of Irregularly Spaced Events and Their Participants
Dec 31, 2021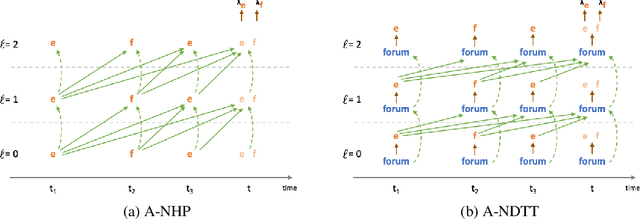

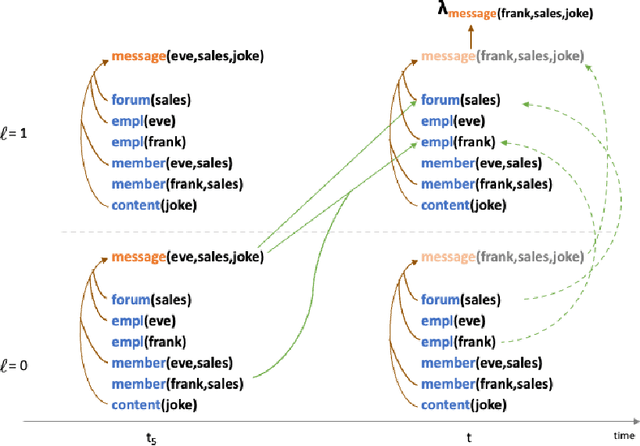

We propose an approach to modeling irregularly spaced sequences of discrete events. We begin with a continuous-time variant of the Transformer, which was originally formulated (Vaswani et al., 2017) for sequences without timestamps. We embed a possible event (or other boolean fact) at time $t$ by using attention over the events that occurred at times $< t$ (and the facts that were true when they occurred). We control this attention using pattern-matching logic rules that relate events and facts that share participants. These rules determine which previous events will be attended to, as well as how to transform the embeddings of the events and facts into the attentional queries, keys, and values. Other logic rules describe how to change the set of facts in response to events. Our approach closely follows Mei et al. (2020a), and adopts their Datalog Through Time formalism for logic rules. As in that work, a domain expert first writes a set of logic rules that establishes the set of possible events and other facts at each time $t$. Each possible event or other fact is embedded using a neural architecture that is derived from the rules that established it. Our only difference from Mei et al. (2020a) is that we derive a flatter, attention-based neural architecture whereas they used a more serial LSTM architecture. We find that our attention-based approach performs about equally well on the RoboCup dataset, where the logic rules play an important role in improving performance. We also compared these two methods with two previous attention-based methods (Zuo et al., 2020; Zhang et al., 2020a) on simpler synthetic and real domains without logic rules, and found our proposed approach to be at least as good, and sometimes better, than each of the other three methods.