 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of the Hidden World with Large Language Models
Feb 06, 2024Science originates with discovering new causal knowledge from a combination of known facts and observations. Traditional causal discovery approaches mainly rely on high-quality measured variables, usually given by human experts, to find causal relations. However, the causal variables are usually unavailable in a wide range of real-world applications. The rise of large language models (LLMs) that are trained to learn rich knowledge from the massive observations of the world, provides a new opportunity to assist with discovering high-level hidden variables from the raw observational data. Therefore, we introduce COAT: Causal representatiOn AssistanT. COAT incorporates LLMs as a factor proposer that extracts the potential causal factors from unstructured data. Moreover, LLMs can also be instructed to provide additional information used to collect data values (e.g., annotation criteria) and to further parse the raw unstructured data into structured data. The annotated data will be fed to a causal learning module (e.g., the FCI algorithm) that provides both rigorous explanations of the data, as well as useful feedback to further improve the extraction of causal factors by LLMs. We verify the effectiveness of COAT in uncovering the underlying causal system with two case studies of review rating analysis and neuropathic diagnosis.
Enhancing Neural Subset Selection: Integrating Background Information into Set Representations
Feb 05, 2024Learning neural subset selection tasks, such as compound selection in AI-aided drug discovery, have become increasingly pivotal across diverse applications. The existing methodologies in the field primarily concentrate on constructing models that capture the relationship between utility function values and subsets within their respective supersets. However, these approaches tend to overlook the valuable information contained within the superset when utilizing neural networks to model set functions. In this work, we address this oversight by adopting a probabilistic perspective. Our theoretical findings demonstrate that when the target value is conditioned on both the input set and subset, it is essential to incorporate an \textit{invariant sufficient statistic} of the superset into the subset of interest for effective learning. This ensures that the output value remains invariant to permutations of the subset and its corresponding superset, enabling identification of the specific superset from which the subset originated. Motivated by these insights, we propose a simple yet effective information aggregation module designed to merge the representations of subsets and supersets from a permutation invariance perspective. Comprehensive empirical evaluations across diverse tasks and datasets validate the enhanced efficacy of our approach over conventional methods, underscoring the practicality and potency of our proposed strategies in real-world contexts.
Enhancing Evolving Domain Generalization through Dynamic Latent Representations
Jan 16, 2024Domain generalization is a critical challenge for machine learning systems. Prior domain generalization methods focus on extracting domain-invariant features across several stationary domains to enable generalization to new domains. However, in non-stationary tasks where new domains evolve in an underlying continuous structure, such as time, merely extracting the invariant features is insufficient for generalization to the evolving new domains. Nevertheless, it is non-trivial to learn both evolving and invariant features within a single model due to their conflicts. To bridge this gap, we build causal models to characterize the distribution shifts concerning the two patterns, and propose to learn both dynamic and invariant features via a new framework called Mutual Information-Based Sequential Autoencoders (MISTS). MISTS adopts information theoretic constraints onto sequential autoencoders to disentangle the dynamic and invariant features, and leverage a domain adaptive classifier to make predictions based on both evolving and invariant information. Our experimental results on both synthetic and real-world datasets demonstrate that MISTS succeeds in capturing both evolving and invariant information, and present promising results in evolving domain generalization tasks.
SPT: Fine-Tuning Transformer-based Language Models Efficiently with Sparsification
Dec 16, 2023Transformer-based large language models (e.g., BERT and GPT) achieve great success, and fine-tuning, which tunes a pre-trained model on a task-specific dataset, is the standard practice to utilize these models for downstream tasks. However, Transformer fine-tuning has long running time and high memory consumption due to the large size of the models. We propose the SPT system to fine-tune Transformer-based models efficiently by introducing sparsity. We observe that the memory consumption of Transformer mainly comes from storing attention weights for multi-head attention (MHA), and the majority of running time is spent on feed-forward network (FFN). Thus, we design the sparse MHA module, which computes and stores only large attention weights to reduce memory consumption, and the routed FFN module, which dynamically activates a subset of model parameters for each token to reduce computation cost. We implement SPT on PyTorch and customize CUDA kernels to run sparse MHA and routed FFN efficiently. Specifically, we use product quantization to identify the large attention weights and compute attention via sparse matrix multiplication for sparse MHA. For routed FFN, we batch the tokens according to their activated model parameters for efficient computation. We conduct extensive experiments to evaluate SPT on various model configurations. The results show that SPT consistently outperforms well-optimized baselines, reducing the peak memory consumption by up to 50% and accelerating fine-tuning by up to 2.2x.
Positional Information Matters for Invariant In-Context Learning: A Case Study of Simple Function Classes
Nov 30, 2023In-context learning (ICL) refers to the ability of a model to condition on a few in-context demonstrations (input-output examples of the underlying task) to generate the answer for a new query input, without updating parameters. Despite the impressive ICL ability of LLMs, it has also been found that ICL in LLMs is sensitive to input demonstrations and limited to short context lengths. To understand the limitations and principles for successful ICL, we conduct an investigation with ICL linear regression of transformers. We characterize several Out-of-Distribution (OOD) cases for ICL inspired by realistic LLM ICL failures and compare transformers with DeepSet, a simple yet powerful architecture for ICL. Surprisingly, DeepSet outperforms transformers across a variety of distribution shifts, implying that preserving permutation invariance symmetry to input demonstrations is crucial for OOD ICL. The phenomenon specifies a fundamental requirement by ICL, which we termed as ICL invariance. Nevertheless, the positional encodings in LLMs will break ICL invariance. To this end, we further evaluate transformers with identical positional encodings and find preserving ICL invariance in transformers achieves state-of-the-art performance across various ICL distribution shifts
Does Invariant Graph Learning via Environment Augmentation Learn Invariance?
Oct 29, 2023



Invariant graph representation learning aims to learn the invariance among data from different environments for out-of-distribution generalization on graphs. As the graph environment partitions are usually expensive to obtain, augmenting the environment information has become the de facto approach. However, the usefulness of the augmented environment information has never been verified. In this work, we find that it is fundamentally impossible to learn invariant graph representations via environment augmentation without additional assumptions. Therefore, we develop a set of minimal assumptions, including variation sufficiency and variation consistency, for feasible invariant graph learning. We then propose a new framework Graph invAriant Learning Assistant (GALA). GALA incorporates an assistant model that needs to be sensitive to graph environment changes or distribution shifts. The correctness of the proxy predictions by the assistant model hence can differentiate the variations in spurious subgraphs. We show that extracting the maximally invariant subgraph to the proxy predictions provably identifies the underlying invariant subgraph for successful OOD generalization under the established minimal assumptions. Extensive experiments on datasets including DrugOOD with various graph distribution shifts confirm the effectiveness of GALA.
Towards out-of-distribution generalizable predictions of chemical kinetics properties
Oct 04, 2023



Machine Learning (ML) techniques have found applications in estimating chemical kinetics properties. With the accumulated drug molecules identified through "AI4drug discovery", the next imperative lies in AI-driven design for high-throughput chemical synthesis processes, with the estimation of properties of unseen reactions with unexplored molecules. To this end, the existing ML approaches for kinetics property prediction are required to be Out-Of-Distribution (OOD) generalizable. In this paper, we categorize the OOD kinetic property prediction into three levels (structure, condition, and mechanism), revealing unique aspects of such problems. Under this framework, we create comprehensive datasets to benchmark (1) the state-of-the-art ML approaches for reaction prediction in the OOD setting and (2) the state-of-the-art graph OOD methods in kinetics property prediction problems. Our results demonstrated the challenges and opportunities in OOD kinetics property prediction. Our datasets and benchmarks can further support research in this direction.
Towards Understanding Feature Learning in Out-of-Distribution Generalization
Apr 22, 2023



A common explanation for the failure of out-of-distribution (OOD) generalization is that the model trained with empirical risk minimization (ERM) learns spurious features instead of the desired invariant features. However, several recent studies challenged this explanation and found that deep networks may have already learned sufficiently good features for OOD generalization. The debate extends to the in-distribution and OOD performance correlations along with training or fine-tuning neural nets across a variety of OOD generalization tasks. To understand these seemingly contradicting phenomena, we conduct a theoretical investigation and find that ERM essentially learns both spurious features and invariant features. On the other hand, the quality of learned features during ERM pre-training significantly affects the final OOD performance, as OOD objectives rarely learn new features. Failing to capture all the underlying useful features during pre-training will further limit the final OOD performance. To remedy the issue, we propose Feature Augmented Training (FAT ), to enforce the model to learn all useful features by retaining the already learned features and augmenting new ones by multiple rounds. In each round, the retention and augmentation operations are performed on different subsets of the training data that capture distinct features. Extensive experiments show that FAT effectively learns richer features and consistently improves the OOD performance when applied to various objectives.
DGI: Easy and Efficient Inference for GNNs
Nov 28, 2022While many systems have been developed to train Graph Neural Networks (GNNs), efficient model inference and evaluation remain to be addressed. For instance, using the widely adopted node-wise approach, model evaluation can account for up to 94% of the time in the end-to-end training process due to neighbor explosion, which means that a node accesses its multi-hop neighbors. On the other hand, layer-wise inference avoids the neighbor explosion problem by conducting inference layer by layer such that the nodes only need their one-hop neighbors in each layer. However, implementing layer-wise inference requires substantial engineering efforts because users need to manually decompose a GNN model into layers for computation and split workload into batches to fit into device memory. In this paper, we develop Deep Graph Inference (DGI) -- a system for easy and efficient GNN model inference, which automatically translates the training code of a GNN model for layer-wise execution. DGI is general for various GNN models and different kinds of inference requests, and supports out-of-core execution on large graphs that cannot fit in CPU memory. Experimental results show that DGI consistently outperforms layer-wise inference across different datasets and hardware settings, and the speedup can be over 1,000x.
A Representation Learning Framework for Property Graphs
Jun 27, 2022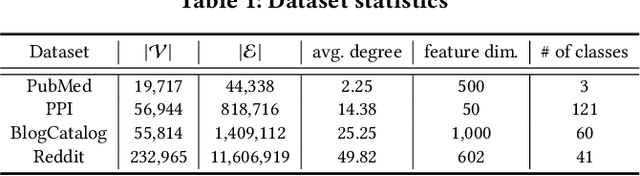
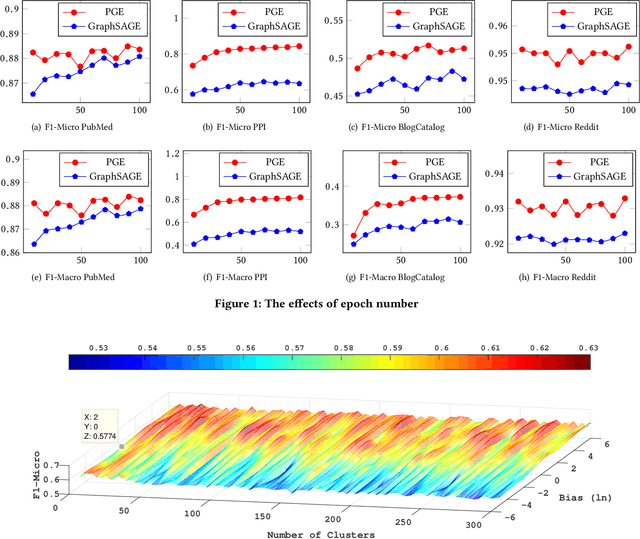

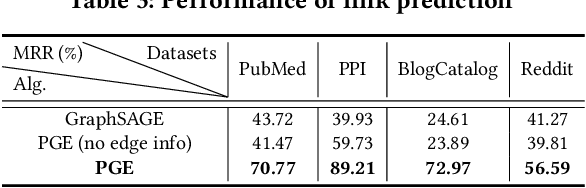
Representation learning on graphs, also called graph embedding, has demonstrated its significant impact on a series of machine learning applications such as classification, prediction and recommendation. However, existing work has largely ignored the rich information contained in the properties (or attributes) of both nodes and edges of graphs in modern applications, e.g., those represented by property graphs. To date, most existing graph embedding methods either focus on plain graphs with only the graph topology, or consider properties on nodes only. We propose PGE, a graph representation learning framework that incorporates both node and edge properties into the graph embedding procedure. PGE uses node clustering to assign biases to differentiate neighbors of a node and leverages multiple data-driven matrices to aggregate the property information of neighbors sampled based on a biased strategy. PGE adopts the popular inductive model for neighborhood aggregation. We provide detailed analyses on the efficacy of our method and validate the performance of PGE by showing how PGE achieves better embedding results than the state-of-the-art graph embedding methods on benchmark applications such as node classification and link prediction over real-world datasets.