 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
LLMs Need Encoders for Semantic IDs Too
May 29, 2026Multimodal LLMs use dedicated encoders to bridge non-language modalities (vision encoders for images, depth models for audio codec tokens) because raw token embeddings alone cannot capture modality-specific structure. We argue that Semantic IDs (SIDs), the hierarchical codes used in generative recommendation, constitute another such modality: a SID level token's meaning depends on its prefix context, yet current systems simply add SID tokens to the vocabulary and rely on training to learn these context-dependent meanings from scratch. We propose PrefixMem, a lightweight SID encoder based on prefix n-gram memory tables that provides the LLM with structured, prefix-conditioned representations at SID token positions. Like vision encoders in multimodal LLMs, PrefixMem can be pre-trained independently and then attached to any LLM for joint training. We evaluate on large-scale data from Pinterest across multiple LLM families and show that PrefixMem improves deepest-level SID accuracy by up to 46% relative and full-SID retrieval recall by up to 22% relative at matched training compute. The encoder's benefit concentrates on hard examples where greedy decoding fails, with up to 77% relative accuracy gains, confirming that SID tokens benefit from a dedicated encoder just as other non-language modalities do.
Warmer for Less: A Cost-Efficient Strategy for Cold-Start Recommendations at Pinterest
Dec 19, 2025Pinterest is a leading visual discovery platform where recommender systems (RecSys) are key to delivering relevant, engaging, and fresh content to our users. In this paper, we study the problem of improving RecSys model predictions for cold-start (CS) items, which appear infrequently in the training data. Although this problem is well-studied in academia, few studies have addressed its root causes effectively at the scale of a platform like Pinterest. By investigating live traffic data, we identified several challenges of the CS problem and developed a corresponding solution for each: First, industrial-scale RecSys models must operate under tight computational constraints. Since CS items are a minority, any related improvements must be highly cost-efficient. To address this, our solutions were designed to be lightweight, collectively increasing the total parameters by only 5%. Second, CS items are represented only by non-historical (e.g., content or attribute) features, which models often treat as less important. To elevate their significance, we introduce a residual connection for the non-historical features. Third, CS items tend to receive lower prediction scores compared to non-CS items, reducing their likelihood of being surfaced. We mitigate this by incorporating a score regularization term into the model. Fourth, the labels associated with CS items are sparse, making it difficult for the model to learn from them. We apply the manifold mixup technique to address this data sparsity. Implemented together, our methods increased fresh content engagement at Pinterest by 10% without negatively impacting overall engagement and cost, and have been deployed to serve over 570 million users on Pinterest.
OmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning
May 01, 2025



Representation learning, a task of learning latent vectors to represent entities, is a key task in improving search and recommender systems in web applications. Various representation learning methods have been developed, including graph-based approaches for relationships among entities, sequence-based methods for capturing the temporal evolution of user activities, and content-based models for leveraging text and visual content. However, the development of a unifying framework that integrates these diverse techniques to support multiple applications remains a significant challenge. This paper presents OmniSage, a large-scale representation framework that learns universal representations for a variety of applications at Pinterest. OmniSage integrates graph neural networks with content-based models and user sequence models by employing multiple contrastive learning tasks to effectively process graph data, user sequence data, and content signals. To support the training and inference of OmniSage, we developed an efficient infrastructure capable of supporting Pinterest graphs with billions of nodes. The universal representations generated by OmniSage have significantly enhanced user experiences on Pinterest, leading to an approximate 2.5% increase in sitewide repins (saves) across five applications. This paper highlights the impact of unifying representation learning methods, and we will open source the OmniSage code by the time of publication.
PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems
Apr 09, 2025Generative retrieval methods utilize generative sequential modeling techniques, such as transformers, to generate candidate items for recommender systems. These methods have demonstrated promising results in academic benchmarks, surpassing traditional retrieval models like two-tower architectures. However, current generative retrieval methods lack the scalability required for industrial recommender systems, and they are insufficiently flexible to satisfy the multiple metric requirements of modern systems. This paper introduces PinRec, a novel generative retrieval model developed for applications at Pinterest. PinRec utilizes outcome-conditioned generation, enabling modelers to specify how to balance various outcome metrics, such as the number of saves and clicks, to effectively align with business goals and user exploration. Additionally, PinRec incorporates multi-token generation to enhance output diversity while optimizing generation. Our experiments demonstrate that PinRec can successfully balance performance, diversity, and efficiency, delivering a significant positive impact to users using generative models. This paper marks a significant milestone in generative retrieval, as it presents, to our knowledge, the first rigorous study on implementing generative retrieval at the scale of Pinterest.
InteractRank: Personalized Web-Scale Search Pre-Ranking with Cross Interaction Features
Apr 09, 2025



Modern search systems use a multi-stage architecture to deliver personalized results efficiently. Key stages include retrieval, pre-ranking, full ranking, and blending, which refine billions of items to top selections. The pre-ranking stage, vital for scoring and filtering hundreds of thousands of items down to a few thousand, typically relies on two tower models due to their computational efficiency, despite often lacking in capturing complex interactions. While query-item cross interaction features are paramount for full ranking, integrating them into pre-ranking models presents efficiency-related challenges. In this paper, we introduce InteractRank, a novel two tower pre-ranking model with robust cross interaction features used at Pinterest. By incorporating historical user engagement-based query-item interactions in the scoring function along with the two tower dot product, InteractRank significantly boosts pre-ranking performance with minimal latency and computation costs. In real-world A/B experiments at Pinterest, InteractRank improves the online engagement metric by 6.5% over a BM25 baseline and by 3.7% over a vanilla two tower baseline. We also highlight other components of InteractRank, like real-time user-sequence modeling, and analyze their contributions through offline ablation studies. The code for InteractRank is available at https://github.com/pinterest/atg-research/tree/main/InteractRank.
FairSample: Training Fair and Accurate Graph Convolutional Neural Networks Efficiently
Jan 26, 2024



Fairness in Graph Convolutional Neural Networks (GCNs) becomes a more and more important concern as GCNs are adopted in many crucial applications. Societal biases against sensitive groups may exist in many real world graphs. GCNs trained on those graphs may be vulnerable to being affected by such biases. In this paper, we adopt the well-known fairness notion of demographic parity and tackle the challenge of training fair and accurate GCNs efficiently. We present an in-depth analysis on how graph structure bias, node attribute bias, and model parameters may affect the demographic parity of GCNs. Our insights lead to FairSample, a framework that jointly mitigates the three types of biases. We employ two intuitive strategies to rectify graph structures. First, we inject edges across nodes that are in different sensitive groups but similar in node features. Second, to enhance model fairness and retain model quality, we develop a learnable neighbor sampling policy using reinforcement learning. To address the bias in node features and model parameters, FairSample is complemented by a regularization objective to optimize fairness.
Large Language Models for Social Networks: Applications, Challenges, and Solutions
Jan 04, 2024Large Language Models (LLMs) are transforming the way people generate, explore, and engage with content. We study how we can develop LLM applications for online social networks. Despite LLMs' successes in other domains, it is challenging to develop LLM-based products for social networks for numerous reasons, and it has been relatively under-reported in the research community. We categorize LLM applications for social networks into three categories. First is knowledge tasks where users want to find new knowledge and information, such as search and question-answering. Second is entertainment tasks where users want to consume interesting content, such as getting entertaining notification content. Third is foundational tasks that need to be done to moderate and operate the social networks, such as content annotation and LLM monitoring. For each task, we share the challenges we found, solutions we developed, and lessons we learned. To the best of our knowledge, this is the first comprehensive paper about developing LLM applications for social networks.
Let AI Entertain You: Increasing User Engagement with Generative AI and Rejection Sampling
Dec 16, 2023While generative AI excels in content generation, it does not always increase user engagement. This can be attributed to two main factors. First, generative AI generates content without incorporating explicit or implicit feedback about user interactions. Even if the generated content seems to be more informative or well-written, it does not necessarily lead to an increase in user activities, such as clicks. Second, there is a concern with the quality of the content generative AI produces, which often lacks the distinctiveness and authenticity that human-created content possesses. These two factors can lead to content that fails to meet specific needs and preferences of users, ultimately reducing its potential to be engaging. This paper presents a generic framework of how to improve user engagement with generative AI by leveraging user feedback. Our solutions employ rejection sampling, a technique used in reinforcement learning, to boost engagement metrics. We leveraged the framework in the context of email notification subject lines generation for an online social network, and achieved significant engagement metric lift including +1% Session and +0.4% Weekly Active Users. We believe our work offers a universal framework that enhances user engagement with generative AI, particularly when standard generative AI reaches its limits in terms of enhancing content to be more captivating. To the best of our knowledge, this represents an early milestone in the industry's successful use of generative AI to enhance user engagement.
Deep Job Understanding at LinkedIn
May 29, 2020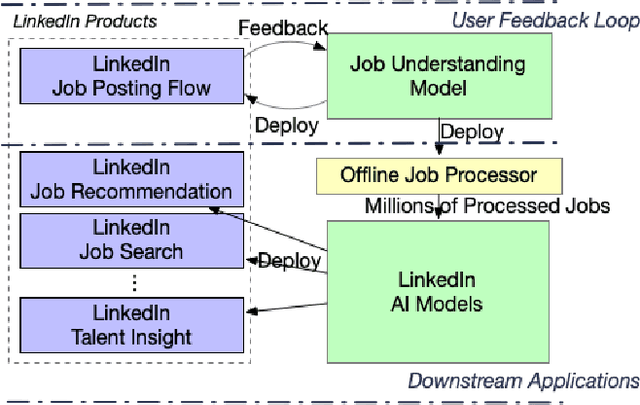
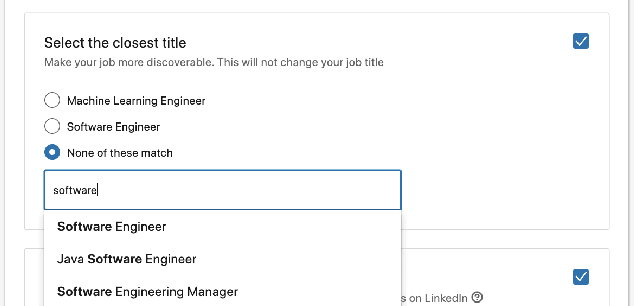
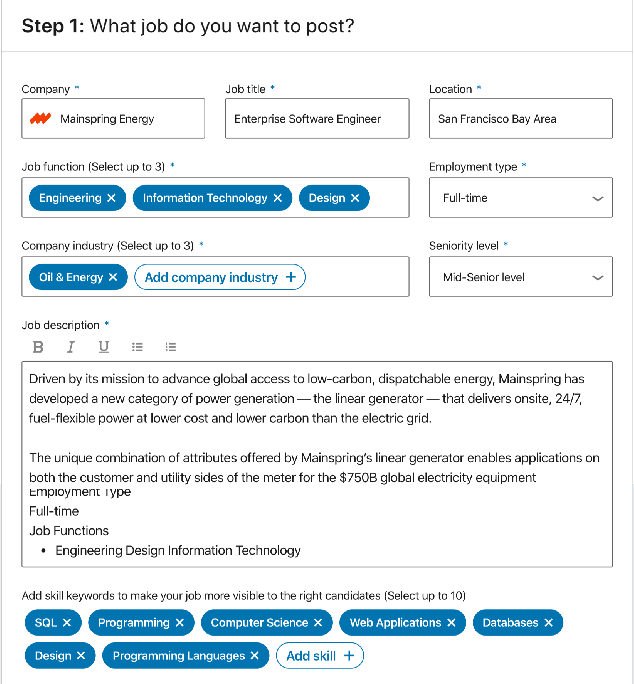
As the world's largest professional network, LinkedIn wants to create economic opportunity for everyone in the global workforce. One of its most critical missions is matching jobs with processionals. Improving job targeting accuracy and hire efficiency align with LinkedIn's Member First Motto. To achieve those goals, we need to understand unstructured job postings with noisy information. We applied deep transfer learning to create domain-specific job understanding models. After this, jobs are represented by professional entities, including titles, skills, companies, and assessment questions. To continuously improve LinkedIn's job understanding ability, we designed an expert feedback loop where we integrated job understanding models into LinkedIn's products to collect job posters' feedback. In this demonstration, we present LinkedIn's job posting flow and demonstrate how the integrated deep job understanding work improves job posters' satisfaction and provides significant metric lifts in LinkedIn's job recommendation system.