 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning
May 01, 2025



Representation learning, a task of learning latent vectors to represent entities, is a key task in improving search and recommender systems in web applications. Various representation learning methods have been developed, including graph-based approaches for relationships among entities, sequence-based methods for capturing the temporal evolution of user activities, and content-based models for leveraging text and visual content. However, the development of a unifying framework that integrates these diverse techniques to support multiple applications remains a significant challenge. This paper presents OmniSage, a large-scale representation framework that learns universal representations for a variety of applications at Pinterest. OmniSage integrates graph neural networks with content-based models and user sequence models by employing multiple contrastive learning tasks to effectively process graph data, user sequence data, and content signals. To support the training and inference of OmniSage, we developed an efficient infrastructure capable of supporting Pinterest graphs with billions of nodes. The universal representations generated by OmniSage have significantly enhanced user experiences on Pinterest, leading to an approximate 2.5% increase in sitewide repins (saves) across five applications. This paper highlights the impact of unifying representation learning methods, and we will open source the OmniSage code by the time of publication.
PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems
Apr 09, 2025Generative retrieval methods utilize generative sequential modeling techniques, such as transformers, to generate candidate items for recommender systems. These methods have demonstrated promising results in academic benchmarks, surpassing traditional retrieval models like two-tower architectures. However, current generative retrieval methods lack the scalability required for industrial recommender systems, and they are insufficiently flexible to satisfy the multiple metric requirements of modern systems. This paper introduces PinRec, a novel generative retrieval model developed for applications at Pinterest. PinRec utilizes outcome-conditioned generation, enabling modelers to specify how to balance various outcome metrics, such as the number of saves and clicks, to effectively align with business goals and user exploration. Additionally, PinRec incorporates multi-token generation to enhance output diversity while optimizing generation. Our experiments demonstrate that PinRec can successfully balance performance, diversity, and efficiency, delivering a significant positive impact to users using generative models. This paper marks a significant milestone in generative retrieval, as it presents, to our knowledge, the first rigorous study on implementing generative retrieval at the scale of Pinterest.
Hybrid Preference Optimization: Augmenting Direct Preference Optimization with Auxiliary Objectives
May 29, 2024



For aligning large language models (LLMs), prior work has leveraged reinforcement learning via human feedback (RLHF) or variations of direct preference optimization (DPO). While DPO offers a simpler framework based on maximum likelihood estimation, it compromises on the ability to tune language models to easily maximize non-differentiable and non-binary objectives according to the LLM designer's preferences (e.g., using simpler language or minimizing specific kinds of harmful content). These may neither align with user preferences nor even be able to be captured tractably by binary preference data. To leverage the simplicity and performance of DPO with the generalizability of RL, we propose a hybrid approach between DPO and RLHF. With a simple augmentation to the implicit reward decomposition of DPO, we allow for tuning LLMs to maximize a set of arbitrary auxiliary rewards using offline RL. The proposed method, Hybrid Preference Optimization (HPO), shows the ability to effectively generalize to both user preferences and auxiliary designer objectives, while preserving alignment performance across a range of challenging benchmarks and model sizes.
OPERA: Automatic Offline Policy Evaluation with Re-weighted Aggregates of Multiple Estimators
May 27, 2024



Offline policy evaluation (OPE) allows us to evaluate and estimate a new sequential decision-making policy's performance by leveraging historical interaction data collected from other policies. Evaluating a new policy online without a confident estimate of its performance can lead to costly, unsafe, or hazardous outcomes, especially in education and healthcare. Several OPE estimators have been proposed in the last decade, many of which have hyperparameters and require training. Unfortunately, choosing the best OPE algorithm for each task and domain is still unclear. In this paper, we propose a new algorithm that adaptively blends a set of OPE estimators given a dataset without relying on an explicit selection using a statistical procedure. We prove that our estimator is consistent and satisfies several desirable properties for policy evaluation. Additionally, we demonstrate that when compared to alternative approaches, our estimator can be used to select higher-performing policies in healthcare and robotics. Our work contributes to improving ease of use for a general-purpose, estimator-agnostic, off-policy evaluation framework for offline RL.
Waypoint Transformer: Reinforcement Learning via Supervised Learning with Intermediate Targets
Jun 24, 2023



Despite the recent advancements in offline reinforcement learning via supervised learning (RvS) and the success of the decision transformer (DT) architecture in various domains, DTs have fallen short in several challenging benchmarks. The root cause of this underperformance lies in their inability to seamlessly connect segments of suboptimal trajectories. To overcome this limitation, we present a novel approach to enhance RvS methods by integrating intermediate targets. We introduce the Waypoint Transformer (WT), using an architecture that builds upon the DT framework and conditioned on automatically-generated waypoints. The results show a significant increase in the final return compared to existing RvS methods, with performance on par or greater than existing state-of-the-art temporal difference learning-based methods. Additionally, the performance and stability improvements are largest in the most challenging environments and data configurations, including AntMaze Large Play/Diverse and Kitchen Mixed/Partial.
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models
May 29, 2021
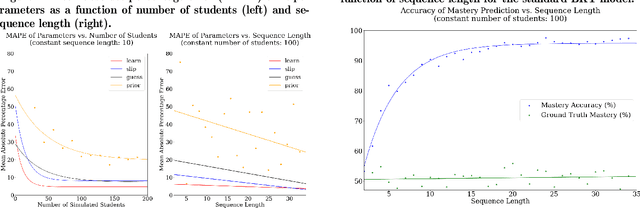
Bayesian Knowledge Tracing, a model used for cognitive mastery estimation, has been a hallmark of adaptive learning research and an integral component of deployed intelligent tutoring systems (ITS). In this paper, we provide a brief history of knowledge tracing model research and introduce pyBKT, an accessible and computationally efficient library of model extensions from the literature. The library provides data generation, fitting, prediction, and cross-validation routines, as well as a simple to use data helper interface to ingest typical tutor log dataset formats. We evaluate the runtime with various dataset sizes and compare to past implementations. Additionally, we conduct sanity checks of the model using experiments with simulated data to evaluate the accuracy of its EM parameter learning and use real-world data to validate its predictions, comparing pyBKT's supported model variants with results from the papers in which they were originally introduced. The library is open source and open license for the purpose of making knowledge tracing more accessible to communities of research and practice and to facilitate progress in the field through easier replication of past approaches.