 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Need Encoders for Semantic IDs Too
May 29, 2026Multimodal LLMs use dedicated encoders to bridge non-language modalities (vision encoders for images, depth models for audio codec tokens) because raw token embeddings alone cannot capture modality-specific structure. We argue that Semantic IDs (SIDs), the hierarchical codes used in generative recommendation, constitute another such modality: a SID level token's meaning depends on its prefix context, yet current systems simply add SID tokens to the vocabulary and rely on training to learn these context-dependent meanings from scratch. We propose PrefixMem, a lightweight SID encoder based on prefix n-gram memory tables that provides the LLM with structured, prefix-conditioned representations at SID token positions. Like vision encoders in multimodal LLMs, PrefixMem can be pre-trained independently and then attached to any LLM for joint training. We evaluate on large-scale data from Pinterest across multiple LLM families and show that PrefixMem improves deepest-level SID accuracy by up to 46% relative and full-SID retrieval recall by up to 22% relative at matched training compute. The encoder's benefit concentrates on hard examples where greedy decoding fails, with up to 77% relative accuracy gains, confirming that SID tokens benefit from a dedicated encoder just as other non-language modalities do.
Translating Math Formula Images to LaTeX Sequences Using Deep Neural Networks with Sequence-level Training
Sep 09, 2019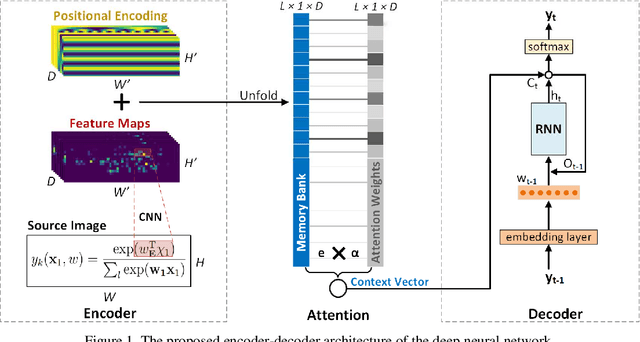
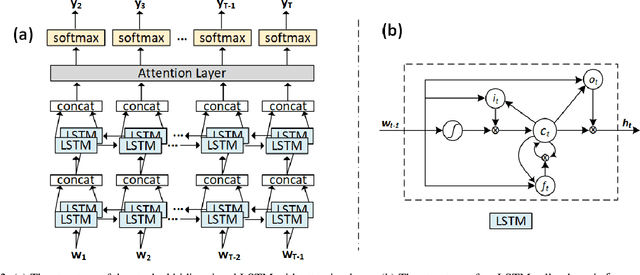
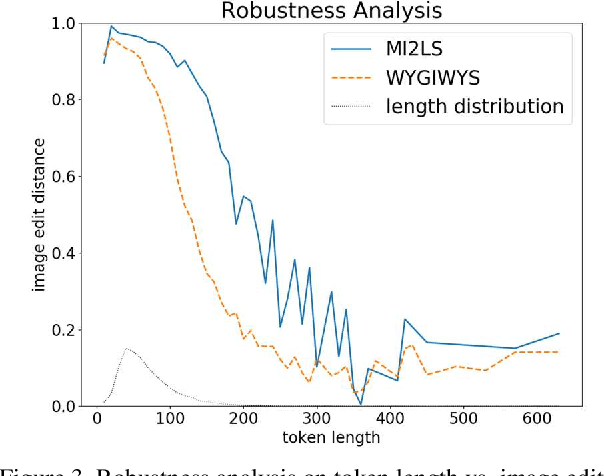

In this paper we propose a deep neural network model with an encoder-decoder architecture that translates images of math formulas into their LaTeX markup sequences. The encoder is a convolutional neural network (CNN) that transforms images into a group of feature maps. To better capture the spatial relationships of math symbols, the feature maps are augmented with 2D positional encoding before being unfolded into a vector. The decoder is a stacked bidirectional long short-term memory (LSTM) model integrated with the soft attention mechanism, which works as a language model to translate the encoder output into a sequence of LaTeX tokens. The neural network is trained in two steps. The first step is token-level training using the Maximum-Likelihood Estimation (MLE) as the objective function. At completion of the token-level training, the sequence-level training objective function is employed to optimize the overall model based on the policy gradient algorithm from reinforcement learning. Our design also overcomes the exposure bias problem by closing the feedback loop in the decoder during sequence-level training, i.e., feeding in the predicted token instead of the ground truth token at every time step. The model is trained and evaluated on the IM2LATEX-100K dataset and shows state-of-the-art performance on both sequence-based and image-based evaluation metrics.