 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Domain Gap: A Simple Domain Matching Method for Reference-based Image Super-Resolution in Remote Sensing
Jan 29, 2024



Recently, reference-based image super-resolution (RefSR) has shown excellent performance in image super-resolution (SR) tasks. The main idea of RefSR is to utilize additional information from the reference (Ref) image to recover the high-frequency components in low-resolution (LR) images. By transferring relevant textures through feature matching, RefSR models outperform existing single image super-resolution (SISR) models. However, their performance significantly declines when a domain gap between Ref and LR images exists, which often occurs in real-world scenarios, such as satellite imaging. In this letter, we introduce a Domain Matching (DM) module that can be seamlessly integrated with existing RefSR models to enhance their performance in a plug-and-play manner. To the best of our knowledge, we are the first to explore Domain Matching-based RefSR in remote sensing image processing. Our analysis reveals that their domain gaps often occur in different satellites, and our model effectively addresses these challenges, whereas existing models struggle. Our experiments demonstrate that the proposed DM module improves SR performance both qualitatively and quantitatively for remote sensing super-resolution tasks.
* Accepted to IEEE GRSL 2023
RADIO: Reference-Agnostic Dubbing Video Synthesis
Sep 05, 2023



One of the most challenging problems in audio-driven talking head generation is achieving high-fidelity detail while ensuring precise synchronization. Given only a single reference image, extracting meaningful identity attributes becomes even more challenging, often causing the network to mirror the facial and lip structures too closely. To address these issues, we introduce RADIO, a framework engineered to yield high-quality dubbed videos regardless of the pose or expression in reference images. The key is to modulate the decoder layers using latent space composed of audio and reference features. Additionally, we incorporate ViT blocks into the decoder to emphasize high-fidelity details, especially in the lip region. Our experimental results demonstrate that RADIO displays high synchronization without the loss of fidelity. Especially in harsh scenarios where the reference frame deviates significantly from the ground truth, our method outperforms state-of-the-art methods, highlighting its robustness. Pre-trained model and codes will be made public after the review.
TopP&R: Robust Support Estimation Approach for Evaluating Fidelity and Diversity in Generative Models
Jun 21, 2023



We propose a robust and reliable evaluation metric for generative models by introducing topological and statistical treatments for rigorous support estimation. Existing metrics, such as Inception Score (IS), Frechet Inception Distance (FID), and the variants of Precision and Recall (P&R), heavily rely on supports that are estimated from sample features. However, the reliability of their estimation has not been seriously discussed (and overlooked) even though the quality of the evaluation entirely depends on it. In this paper, we propose Topological Precision and Recall (TopP&R, pronounced 'topper'), which provides a systematic approach to estimating supports, retaining only topologically and statistically important features with a certain level of confidence. This not only makes TopP&R strong for noisy features, but also provides statistical consistency. Our theoretical and experimental results show that TopP&R is robust to outliers and non-independent and identically distributed (Non-IID) perturbations, while accurately capturing the true trend of change in samples. To the best of our knowledge, this is the first evaluation metric focused on the robust estimation of the support and provides its statistical consistency under noise.
Efficient Storage of Fine-Tuned Models via Low-Rank Approximation of Weight Residuals
May 28, 2023



In this paper, we present an efficient method for storing fine-tuned models by leveraging the low-rank properties of weight residuals. Our key observation is that weight residuals in large overparameterized models exhibit even stronger low-rank characteristics. Based on this insight, we propose Efficient Residual Encoding (ERE), a novel approach that achieves efficient storage of fine-tuned model weights by approximating the low-rank weight residuals. Furthermore, we analyze the robustness of weight residuals and push the limit of storage efficiency by utilizing additional quantization and layer-wise rank allocation. Our experimental results demonstrate that our method significantly reduces memory footprint while preserving performance in various tasks and modalities. We release our code.
Fix the Noise: Disentangling Source Feature for Controllable Domain Translation
Mar 21, 2023Recent studies show strong generative performance in domain translation especially by using transfer learning techniques on the unconditional generator. However, the control between different domain features using a single model is still challenging. Existing methods often require additional models, which is computationally demanding and leads to unsatisfactory visual quality. In addition, they have restricted control steps, which prevents a smooth transition. In this paper, we propose a new approach for high-quality domain translation with better controllability. The key idea is to preserve source features within a disentangled subspace of a target feature space. This allows our method to smoothly control the degree to which it preserves source features while generating images from an entirely new domain using only a single model. Our extensive experiments show that the proposed method can produce more consistent and realistic images than previous works and maintain precise controllability over different levels of transformation. The code is available at https://github.com/LeeDongYeun/FixNoise.
Can We Find Strong Lottery Tickets in Generative Models?
Dec 16, 2022Yes. In this paper, we investigate strong lottery tickets in generative models, the subnetworks that achieve good generative performance without any weight update. Neural network pruning is considered the main cornerstone of model compression for reducing the costs of computation and memory. Unfortunately, pruning a generative model has not been extensively explored, and all existing pruning algorithms suffer from excessive weight-training costs, performance degradation, limited generalizability, or complicated training. To address these problems, we propose to find a strong lottery ticket via moment-matching scores. Our experimental results show that the discovered subnetwork can perform similarly or better than the trained dense model even when only 10% of the weights remain. To the best of our knowledge, we are the first to show the existence of strong lottery tickets in generative models and provide an algorithm to find it stably. Our code and supplementary materials are publicly available.
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
Aug 31, 2022
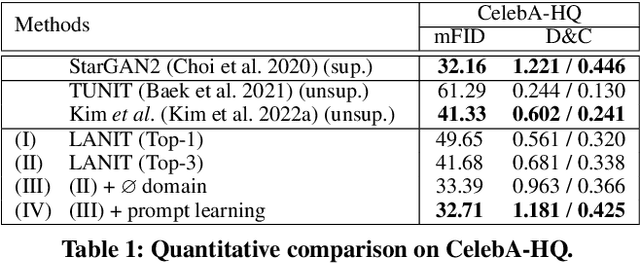
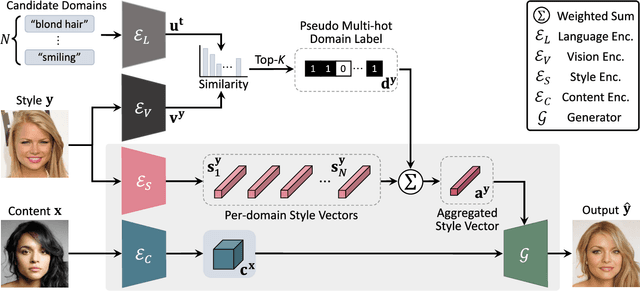
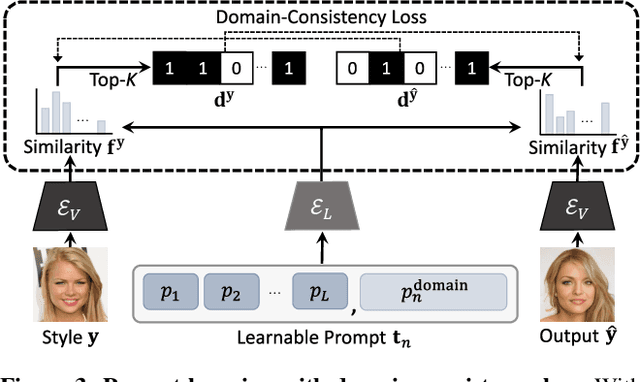
Existing techniques for image-to-image translation commonly have suffered from two critical problems: heavy reliance on per-sample domain annotation and/or inability of handling multiple attributes per image. Recent methods adopt clustering approaches to easily provide per-sample annotations in an unsupervised manner. However, they cannot account for the real-world setting; one sample may have multiple attributes. In addition, the semantics of the clusters are not easily coupled to human understanding. To overcome these, we present a LANguage-driven Image-to-image Translation model, dubbed LANIT. We leverage easy-to-obtain candidate domain annotations given in texts for a dataset and jointly optimize them during training. The target style is specified by aggregating multi-domain style vectors according to the multi-hot domain assignments. As the initial candidate domain texts might be inaccurate, we set the candidate domain texts to be learnable and jointly fine-tune them during training. Furthermore, we introduce a slack domain to cover samples that are not covered by the candidate domains. Experiments on several standard benchmarks demonstrate that LANIT achieves comparable or superior performance to the existing model.
Rethinking the Truly Unsupervised Image-to-Image Translation
Jun 11, 2020

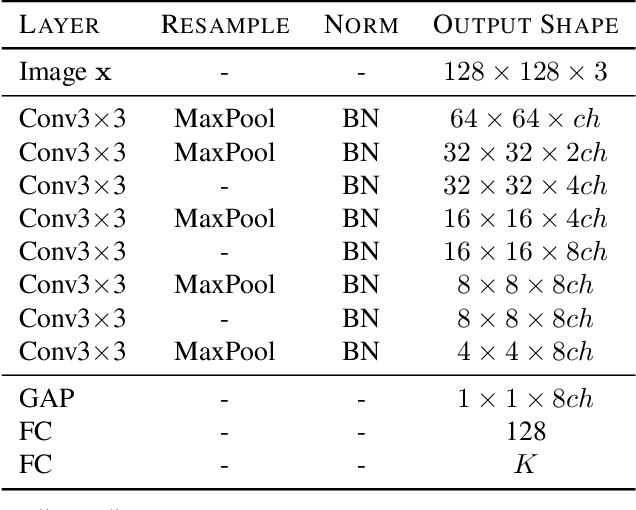
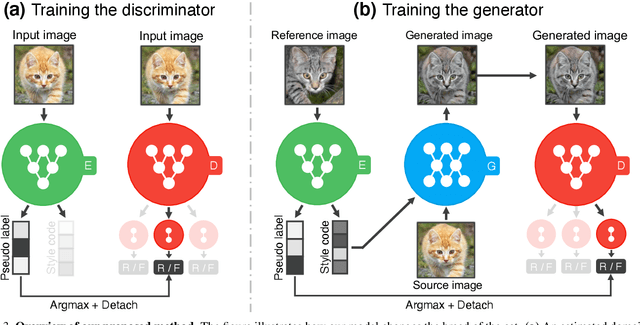
Every recent image-to-image translation model uses either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision at minimum. However, even the set-level supervision can be a serious bottleneck for data collection in practice. In this paper, we tackle image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. To this end, we propose the truly unsupervised image-to-image translation method (TUNIT) that simultaneously learns to separate image domains via an information-theoretic approach and generate corresponding images using the estimated domain labels. Experimental results on various datasets show that the proposed method successfully separates domains and translates images across those domains. In addition, our model outperforms existing set-level supervised methods under a semi-supervised setting, where a subset of domain labels is provided. The source code is available at https://github.com/clovaai/tunit
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
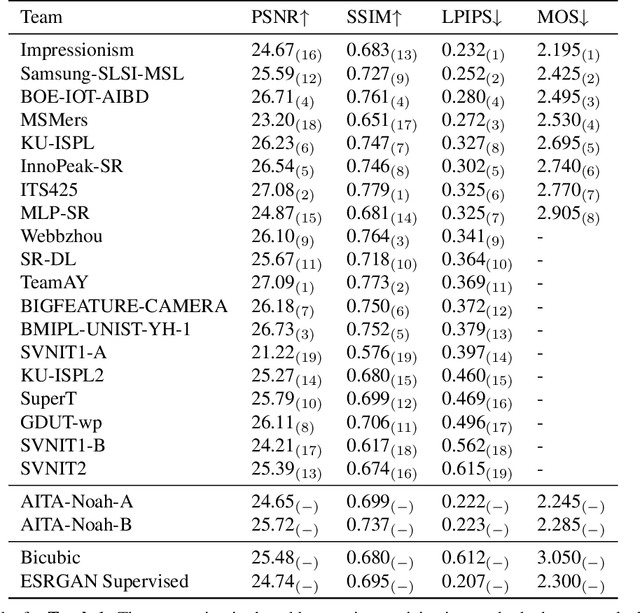
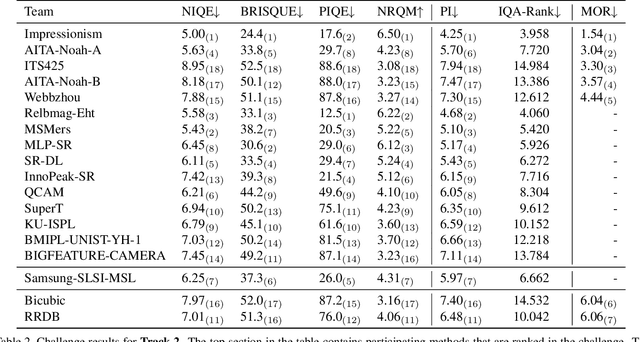

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New Strategy
Apr 23, 2020
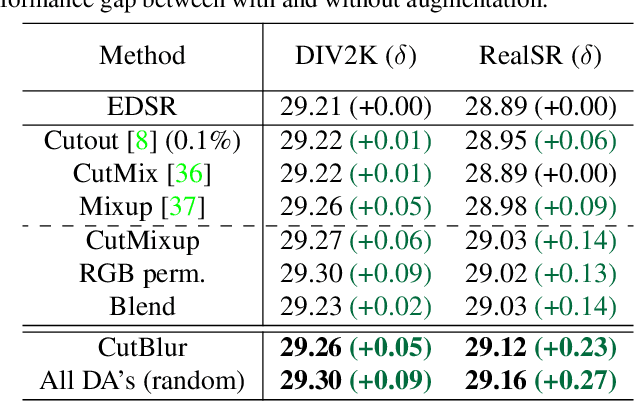

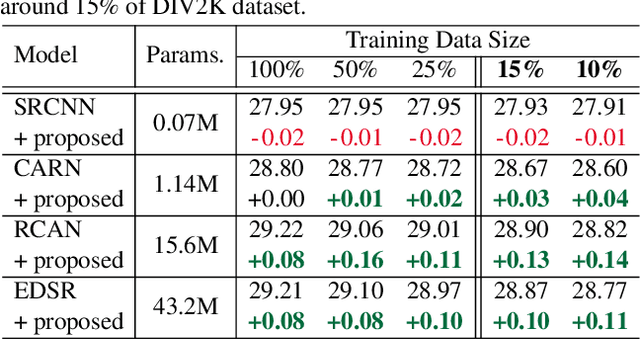
Data augmentation is an effective way to improve the performance of deep networks. Unfortunately, current methods are mostly developed for high-level vision tasks (e.g., classification) and few are studied for low-level vision tasks (e.g., image restoration). In this paper, we provide a comprehensive analysis of the existing augmentation methods applied to the super-resolution task. We find that the methods discarding or manipulating the pixels or features too much hamper the image restoration, where the spatial relationship is very important. Based on our analyses, we propose CutBlur that cuts a low-resolution patch and pastes it to the corresponding high-resolution image region and vice versa. The key intuition of CutBlur is to enable a model to learn not only "how" but also "where" to super-resolve an image. By doing so, the model can understand "how much", instead of blindly learning to apply super-resolution to every given pixel. Our method consistently and significantly improves the performance across various scenarios, especially when the model size is big and the data is collected under real-world environments. We also show that our method improves other low-level vision tasks, such as denoising and compression artifact removal.