 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022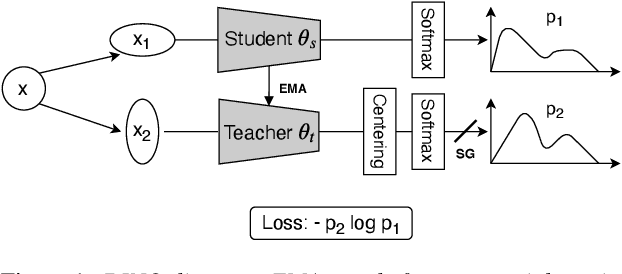
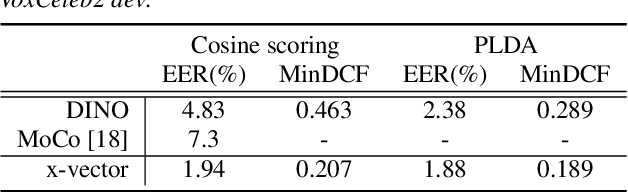
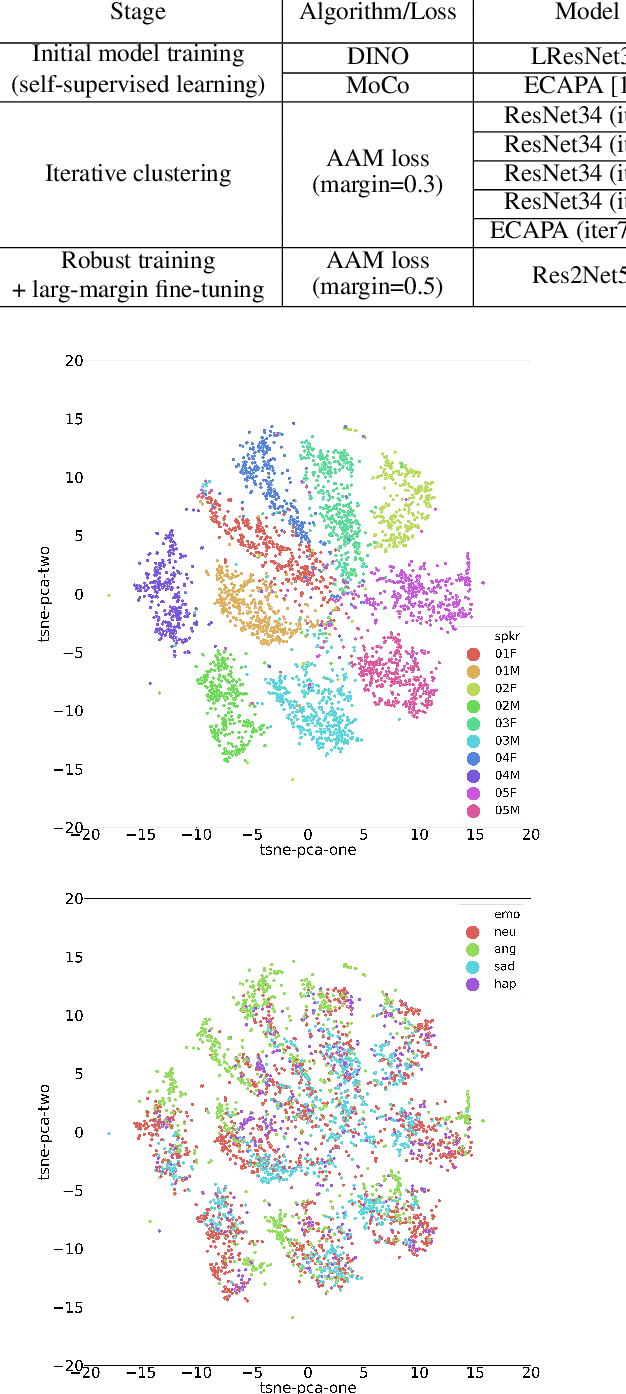
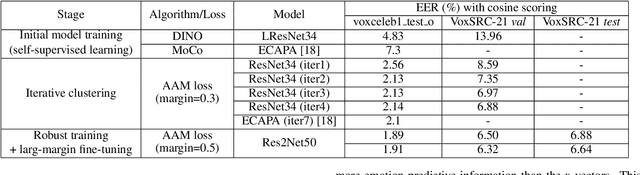
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
Wave-Encoded Model-based Deep Learning for Highly Accelerated Imaging with Joint Reconstruction
Feb 06, 2022Purpose: To propose a wave-encoded model-based deep learning (wave-MoDL) strategy for highly accelerated 3D imaging and joint multi-contrast image reconstruction, and further extend this to enable rapid quantitative imaging using an interleaved look-locker acquisition sequence with T2 preparation pulse (3D-QALAS). Method: Recently introduced MoDL technique successfully incorporates convolutional neural network (CNN)-based regularizers into physics-based parallel imaging reconstruction using a small number of network parameters. Wave-CAIPI is an emerging parallel imaging method that accelerates the imaging speed by employing sinusoidal gradients in the phase- and slice-encoding directions during the readout to take better advantage of 3D coil sensitivity profiles. In wave-MoDL, we propose to combine the wave-encoding strategy with unrolled network constraints to accelerate the acquisition speed while enforcing wave-encoded data consistency. We further extend wave-MoDL to reconstruct multi-contrast data with controlled aliasing in parallel imaging (CAIPI) sampling patterns to leverage similarity between multiple images to improve the reconstruction quality. Result: Wave-MoDL enables a 47-second MPRAGE acquisition at 1 mm resolution at 16-fold acceleration. For quantitative imaging, wave-MoDL permits a 2-minute acquisition for T1, T2, and proton density mapping at 1 mm resolution at 12-fold acceleration, from which contrast weighted images can be synthesized as well. Conclusion: Wave-MoDL allows rapid MR acquisition and high-fidelity image reconstruction and may facilitate clinical and neuroscientific applications by incorporating unrolled neural networks into wave-CAIPI reconstruction.
BUDA-SAGE with self-supervised denoising enables fast, distortion-free, high-resolution T2, T2*, para- and dia-magnetic susceptibility mapping
Sep 09, 2021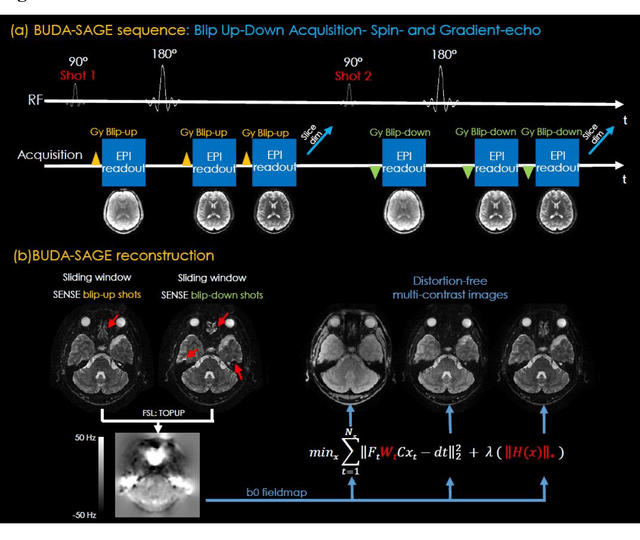
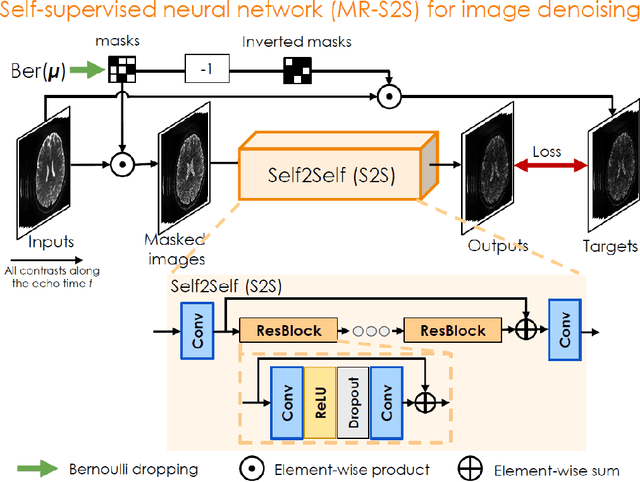

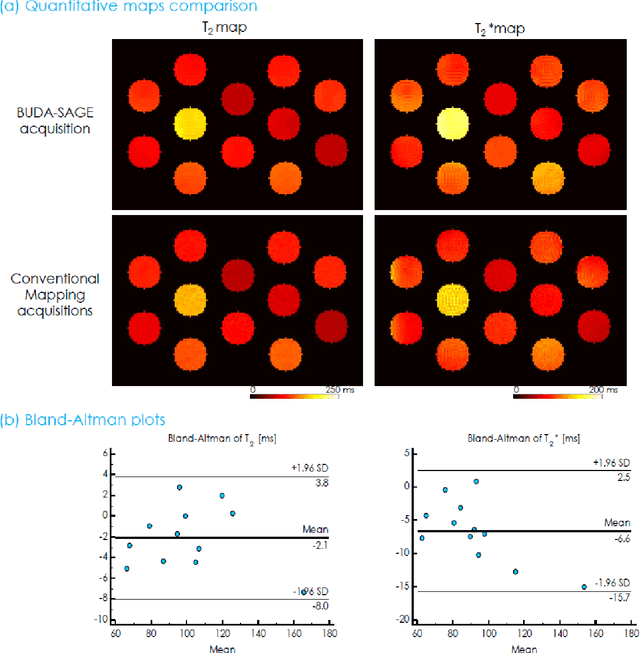
To rapidly obtain high resolution T2, T2* and quantitative susceptibility mapping (QSM) source separation maps with whole-brain coverage and high geometric fidelity. We propose Blip Up-Down Acquisition for Spin And Gradient Echo imaging (BUDA-SAGE), an efficient echo-planar imaging (EPI) sequence for quantitative mapping. The acquisition includes multiple T2*-, T2'- and T2-weighted contrasts. We alternate the phase-encoding polarities across the interleaved shots in this multi-shot navigator-free acquisition. A field map estimated from interim reconstructions was incorporated into the joint multi-shot EPI reconstruction with a structured low rank constraint to eliminate geometric distortion. A self-supervised MR-Self2Self (MR-S2S) neural network (NN) was utilized to perform denoising after BUDA reconstruction to boost SNR. Employing Slider encoding allowed us to reach 1 mm isotropic resolution by performing super-resolution reconstruction on BUDA-SAGE volumes acquired with 2 mm slice thickness. Quantitative T2 and T2* maps were obtained using Bloch dictionary matching on the reconstructed echoes. QSM was estimated using nonlinear dipole inversion (NDI) on the gradient echoes. Starting from the estimated R2 and R2* maps, R2' information was derived and used in source separation QSM reconstruction, which provided additional para- and dia-magnetic susceptibility maps. In vivo results demonstrate the ability of BUDA-SAGE to provide whole-brain, distortion-free, high-resolution multi-contrast images and quantitative T2 and T2* maps, as well as yielding para- and dia-magnetic susceptibility maps. Derived quantitative maps showed comparable values to conventional mapping methods in phantom and in vivo measurements. BUDA-SAGE acquisition with self-supervised denoising and Slider encoding enabled rapid, distortion-free, whole-brain T2, T2* mapping at 1 mm3 isotropic resolution in 90 seconds.
Highly Accelerated EPI with Wave Encoding and Multi-shot Simultaneous Multi-Slice Imaging
Jun 03, 2021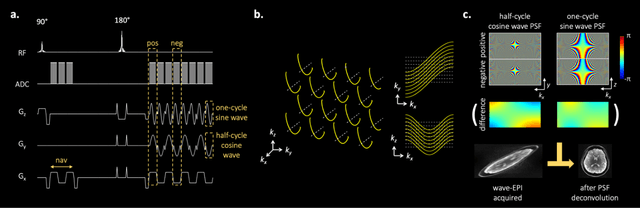
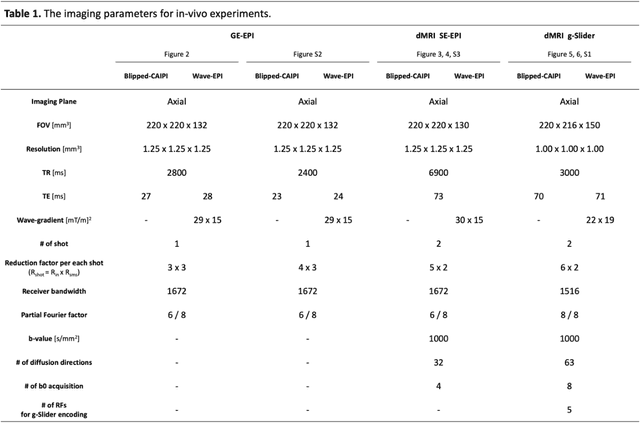
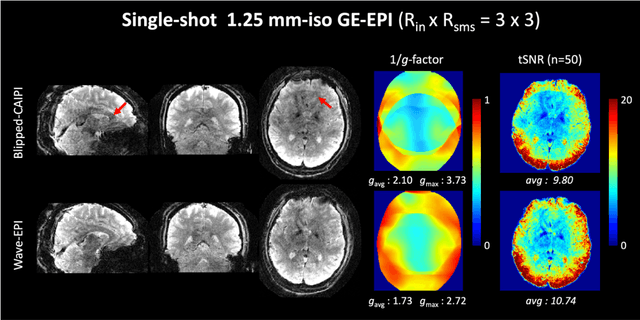
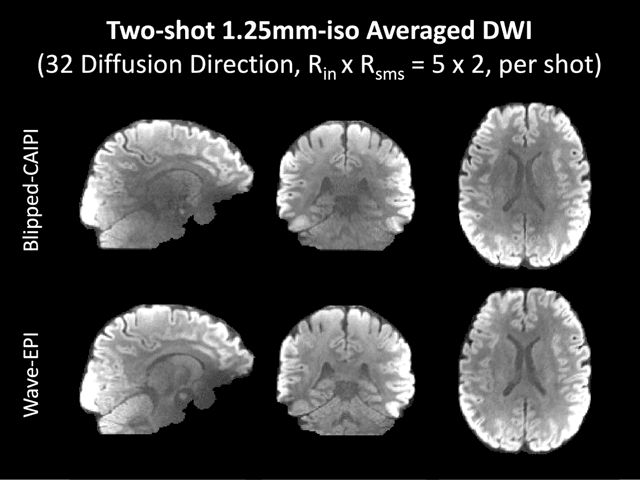
We introduce wave encoded acquisition and reconstruction techniques for highly accelerated echo planar imaging (EPI) with reduced g-factor penalty and image artifacts. Wave-EPI involves playing sinusoidal gradients during the EPI readout while employing interslice shifts as in blipped-CAIPI acquisitions. This spreads the aliasing in all spatial directions, thereby taking better advantage of 3D coil sensitivity profiles. The amount of voxel spreading that can be achieved by the wave gradients during the short EPI readout period is constrained by the slew rate of the gradient coils and peripheral nerve stimulation (PNS) monitor. We propose to use a half-cycle sinusoidal gradient to increase the amount of voxel spreading that can be achieved while respecting the slew and stimulation constraints. Extending wave-EPI to multi-shot acquisition minimizes geometric distortion and voxel blurring at high in-plane resolution, while structured low-rank regularization mitigates shot-to-shot phase variations without additional navigators. We propose to use different point spread functions (PSFs) for the k-space lines with positive and negative polarities, which are calibrated with a FLEET-based reference scan and allow for addressing gradient imperfections. Wave-EPI provided whole-brain single-shot gradient echo (GE) and multi-shot spin echo (SE) EPI acquisitions at high acceleration factors and was combined with g-Slider slab encoding to boost the SNR level in 1mm isotropic diffusion imaging. Relative to blipped-CAIPI, wave-EPI reduced average and maximum g-factors by up to 1.21- and 1.37-fold, respectively. In conclusion, wave-EPI allows highly accelerated single- and multi-shot EPI with reduced g-factor and artifacts and may facilitate clinical and neuroscientific applications of EPI by improving the spatial and temporal resolution in functional and diffusion imaging.
Learning Speaker Embedding from Text-to-Speech
Oct 21, 2020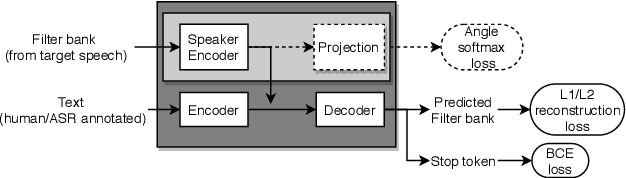

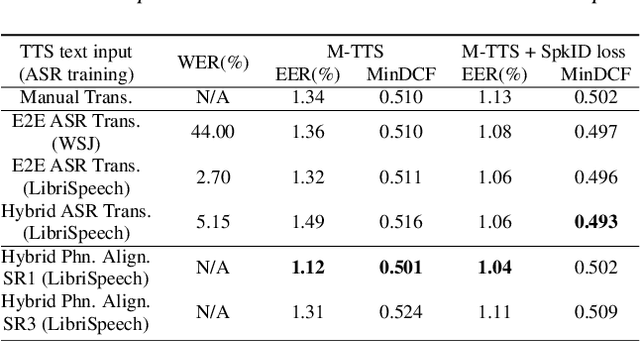
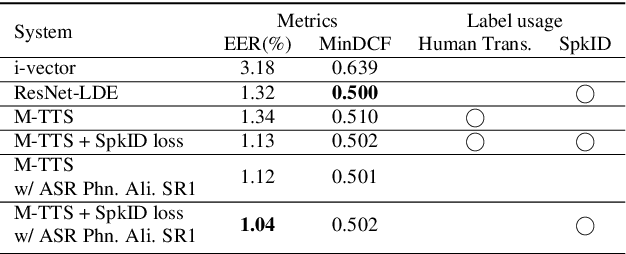
Zero-shot multi-speaker Text-to-Speech (TTS) generates target speaker voices given an input text and the corresponding speaker embedding. In this work, we investigate the effectiveness of the TTS reconstruction objective to improve representation learning for speaker verification. We jointly trained end-to-end Tacotron 2 TTS and speaker embedding networks in a self-supervised fashion. We hypothesize that the embeddings will contain minimal phonetic information since the TTS decoder will obtain that information from the textual input. TTS reconstruction can also be combined with speaker classification to enhance these embeddings further. Once trained, the speaker encoder computes representations for the speaker verification task, while the rest of the TTS blocks are discarded. We investigated training TTS from either manual or ASR-generated transcripts. The latter allows us to train embeddings on datasets without manual transcripts. We compared ASR transcripts and Kaldi phone alignments as TTS inputs, showing that the latter performed better due to their finer resolution. Unsupervised TTS embeddings improved EER by 2.06\% absolute with regard to i-vectors for the LibriTTS dataset. TTS with speaker classification loss improved EER by 0.28\% and 0.73\% absolutely from a model using only speaker classification loss in LibriTTS and Voxceleb1 respectively.
Transfer learning of language-independent end-to-end ASR with language model fusion
Nov 06, 2018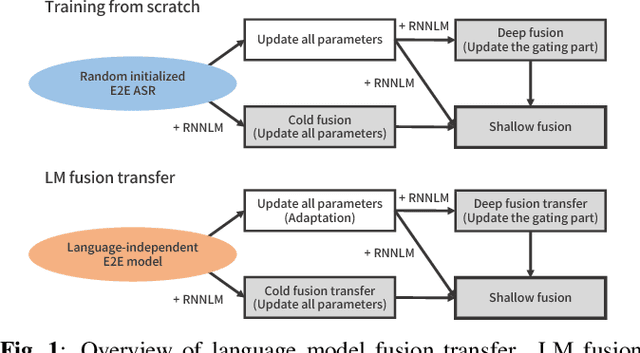
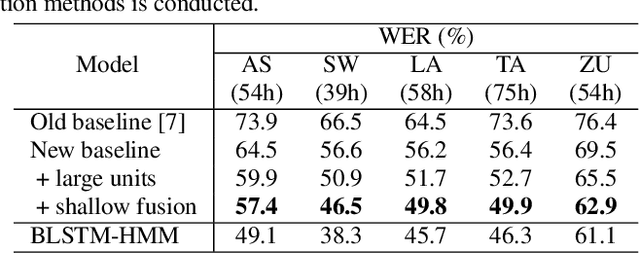
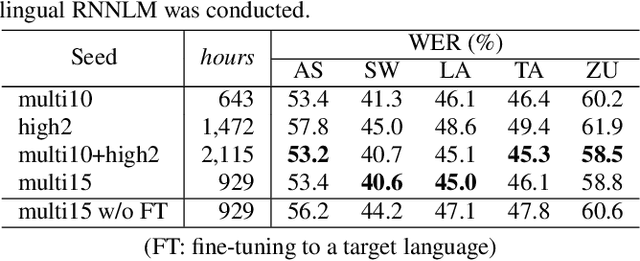
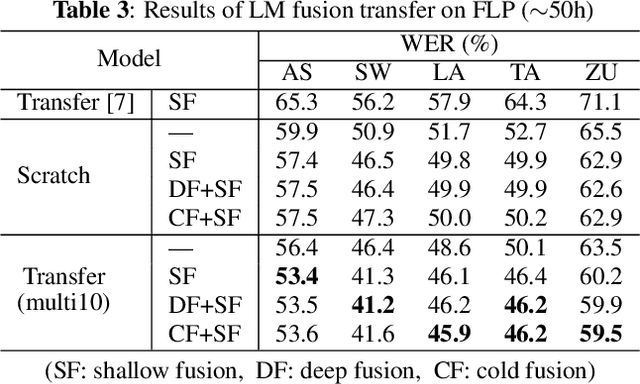
This work explores better adaptation methods to low-resource languages using an external language model (LM) under the framework of transfer learning. We first build a language-independent ASR system in a unified sequence-to-sequence (S2S) architecture with a shared vocabulary among all languages. During adaptation, we perform LM fusion transfer, where an external LM is integrated into the decoder network of the attention-based S2S model in the whole adaptation stage, to effectively incorporate linguistic context of the target language. We also investigate various seed models for transfer learning. Experimental evaluations using the IARPA BABEL data set show that LM fusion transfer improves performances on all target five languages compared with simple transfer learning when the external text data is available. Our final system drastically reduces the performance gap from the hybrid systems.
End-to-end Speech Recognition with Word-based RNN Language Models
Aug 08, 2018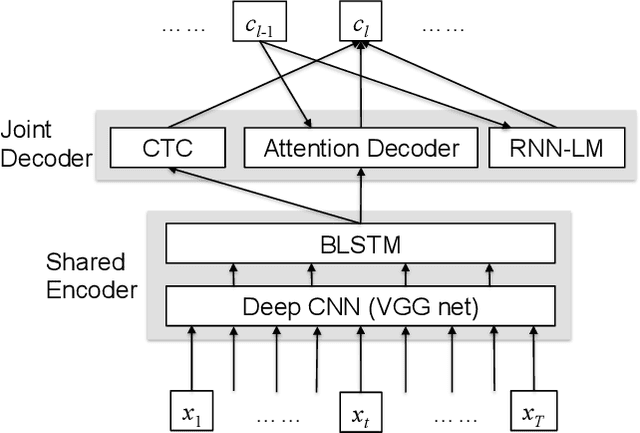

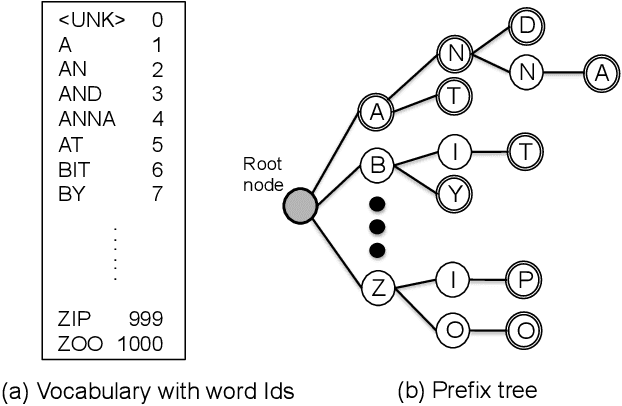
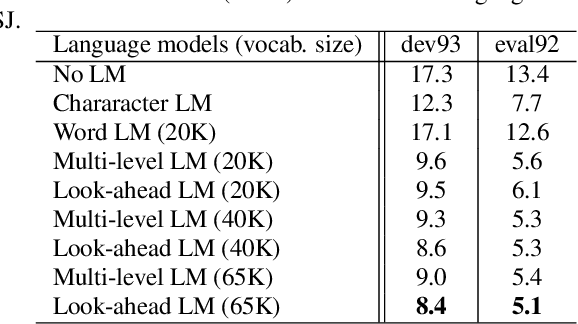
This paper investigates the impact of word-based RNN language models (RNN-LMs) on the performance of end-to-end automatic speech recognition (ASR). In our prior work, we have proposed a multi-level LM, in which character-based and word-based RNN-LMs are combined in hybrid CTC/attention-based ASR. Although this multi-level approach achieves significant error reduction in the Wall Street Journal (WSJ) task, two different LMs need to be trained and used for decoding, which increase the computational cost and memory usage. In this paper, we further propose a novel word-based RNN-LM, which allows us to decode with only the word-based LM, where it provides look-ahead word probabilities to predict next characters instead of the character-based LM, leading competitive accuracy with less computation compared to the multi-level LM. We demonstrate the efficacy of the word-based RNN-LMs using a larger corpus, LibriSpeech, in addition to WSJ we used in the prior work. Furthermore, we show that the proposed model achieves 5.1 %WER for WSJ Eval'92 test set when the vocabulary size is increased, which is the best WER reported for end-to-end ASR systems on this benchmark.