 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021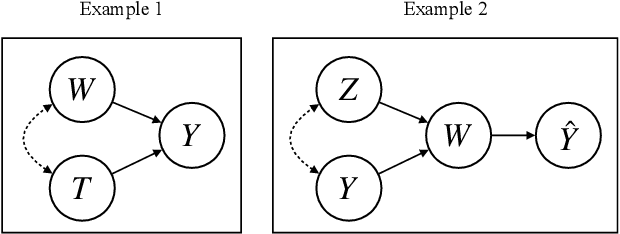
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
Learning to Look Inside: Augmenting Token-Based Encoders with Character-Level Information
Aug 01, 2021
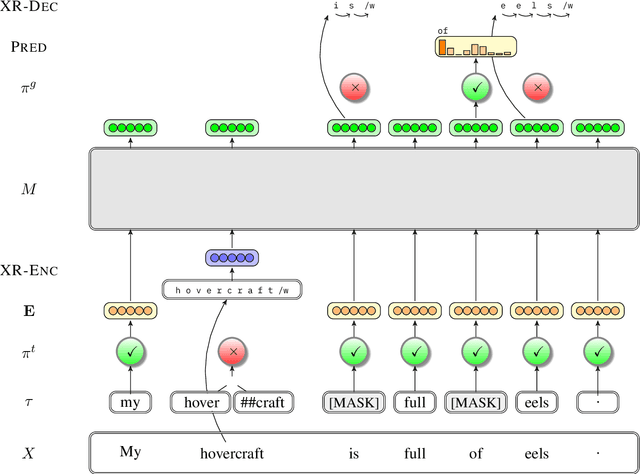

Commonly-used transformer language models depend on a tokenization schema which sets an unchangeable subword vocabulary prior to pre-training, destined to be applied to all downstream tasks regardless of domain shift, novel word formations, or other sources of vocabulary mismatch. Recent work has shown that "token-free" models can be trained directly on characters or bytes, but training these models from scratch requires substantial computational resources, and this implies discarding the many domain-specific models that were trained on tokens. In this paper, we present XRayEmb, a method for retrofitting existing token-based models with character-level information. XRayEmb is composed of a character-level "encoder" that computes vector representations of character sequences, and a generative component that decodes from the internal representation to a character sequence. We show that incorporating XRayEmb's learned vectors into sequences of pre-trained token embeddings helps performance on both autoregressive and masked pre-trained transformer architectures and on both sequence-level and sequence tagging tasks, particularly on non-standard English text.
Revisiting the Primacy of English in Zero-shot Cross-lingual Transfer
Jun 30, 2021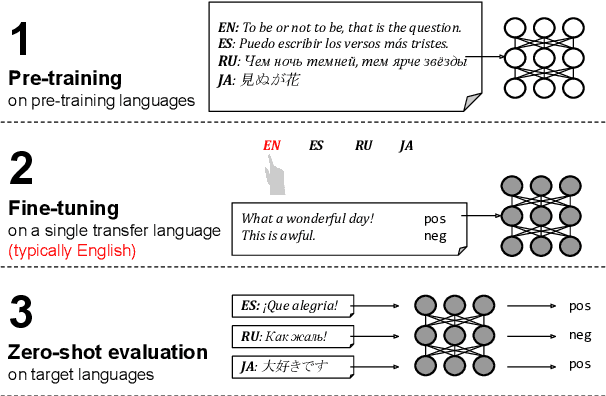
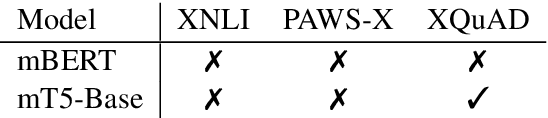
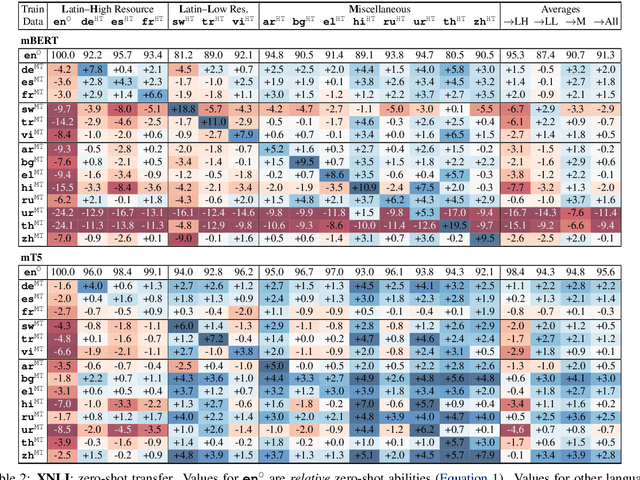
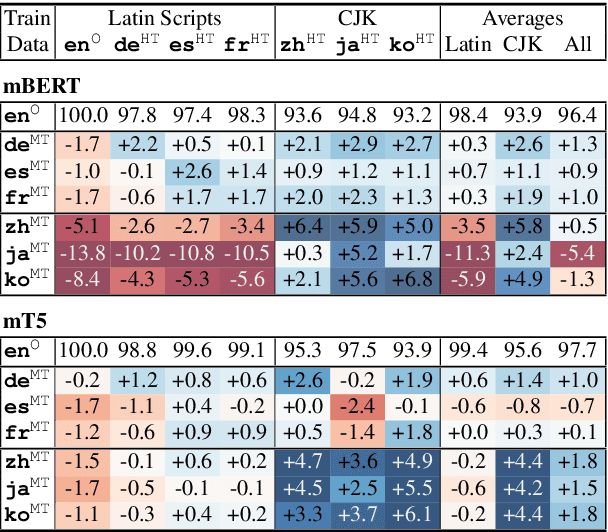
Despite their success, large pre-trained multilingual models have not completely alleviated the need for labeled data, which is cumbersome to collect for all target languages. Zero-shot cross-lingual transfer is emerging as a practical solution: pre-trained models later fine-tuned on one transfer language exhibit surprising performance when tested on many target languages. English is the dominant source language for transfer, as reinforced by popular zero-shot benchmarks. However, this default choice has not been systematically vetted. In our study, we compare English against other transfer languages for fine-tuning, on two pre-trained multilingual models (mBERT and mT5) and multiple classification and question answering tasks. We find that other high-resource languages such as German and Russian often transfer more effectively, especially when the set of target languages is diverse or unknown a priori. Unexpectedly, this can be true even when the training sets were automatically translated from English. This finding can have immediate impact on multilingual zero-shot systems, and should inform future benchmark designs.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021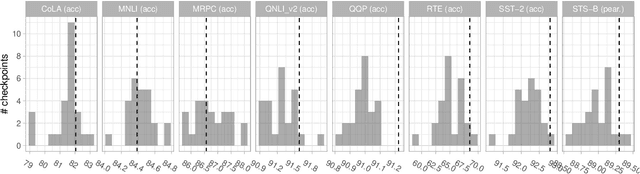
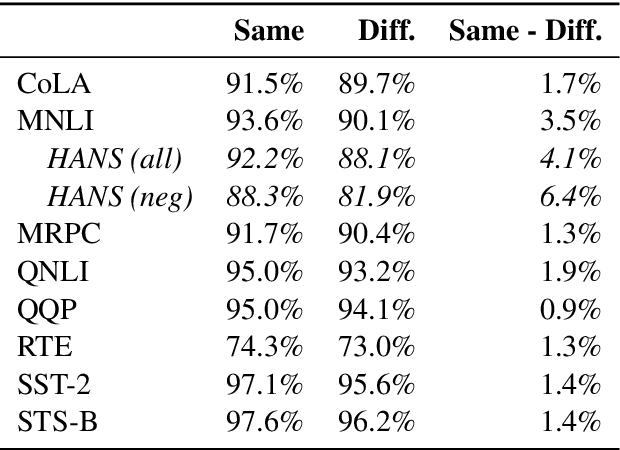
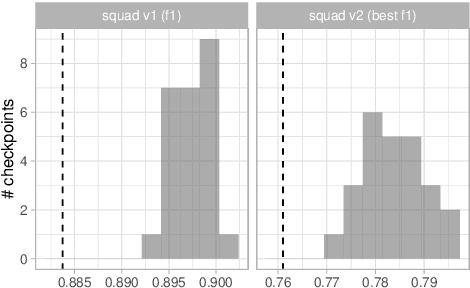
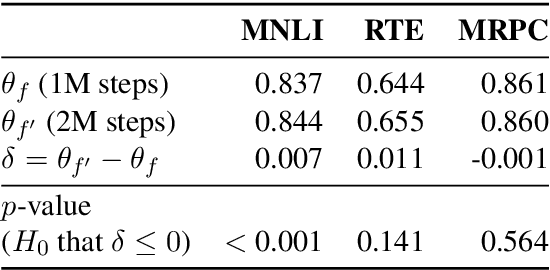
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
Time-Aware Language Models as Temporal Knowledge Bases
Jun 29, 2021
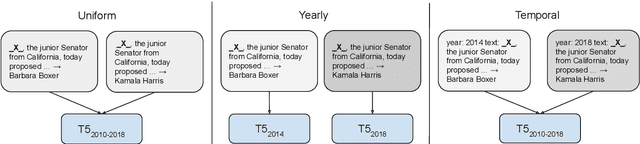
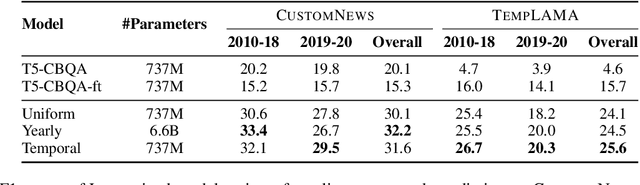
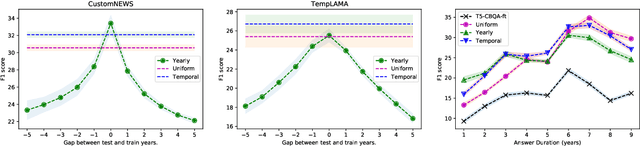
Many facts come with an expiration date, from the name of the President to the basketball team Lebron James plays for. But language models (LMs) are trained on snapshots of data collected at a specific moment in time, and this can limit their utility, especially in the closed-book setting where the pretraining corpus must contain the facts the model should memorize. We introduce a diagnostic dataset aimed at probing LMs for factual knowledge that changes over time and highlight problems with LMs at either end of the spectrum -- those trained on specific slices of temporal data, as well as those trained on a wide range of temporal data. To mitigate these problems, we propose a simple technique for jointly modeling text with its timestamp. This improves memorization of seen facts from the training time period, as well as calibration on predictions about unseen facts from future time periods. We also show that models trained with temporal context can be efficiently ``refreshed'' as new data arrives, without the need for retraining from scratch.
Counterfactual Invariance to Spurious Correlations: Why and How to Pass Stress Tests
Jun 02, 2021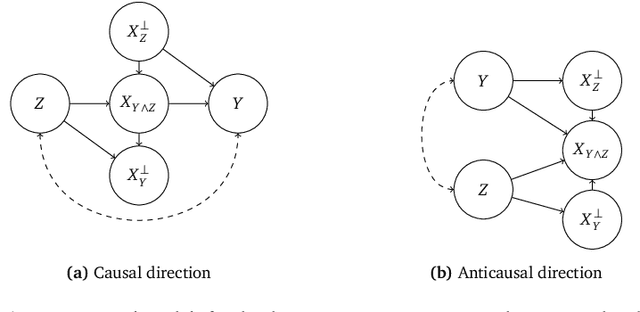

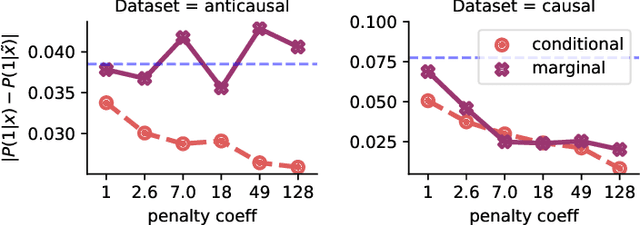
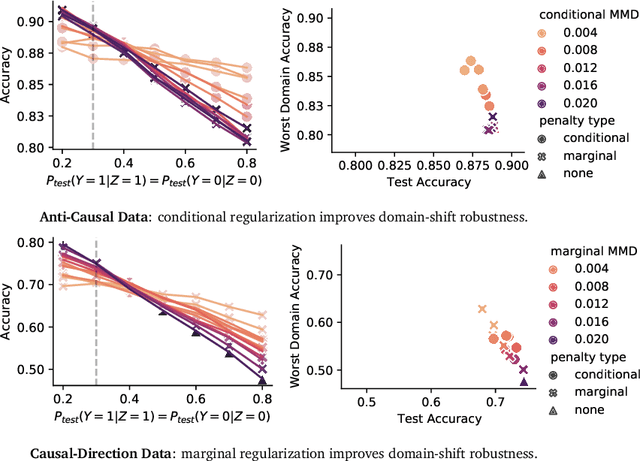
Informally, a `spurious correlation' is the dependence of a model on some aspect of the input data that an analyst thinks shouldn't matter. In machine learning, these have a know-it-when-you-see-it character; e.g., changing the gender of a sentence's subject changes a sentiment predictor's output. To check for spurious correlations, we can `stress test' models by perturbing irrelevant parts of input data and seeing if model predictions change. In this paper, we study stress testing using the tools of causal inference. We introduce \emph{counterfactual invariance} as a formalization of the requirement that changing irrelevant parts of the input shouldn't change model predictions. We connect counterfactual invariance to out-of-domain model performance, and provide practical schemes for learning (approximately) counterfactual invariant predictors (without access to counterfactual examples). It turns out that both the means and implications of counterfactual invariance depend fundamentally on the true underlying causal structure of the data. Distinct causal structures require distinct regularization schemes to induce counterfactual invariance. Similarly, counterfactual invariance implies different domain shift guarantees depending on the underlying causal structure. This theory is supported by empirical results on text classification.
Abolitionist Networks: Modeling Language Change in Nineteenth-Century Activist Newspapers
Mar 12, 2021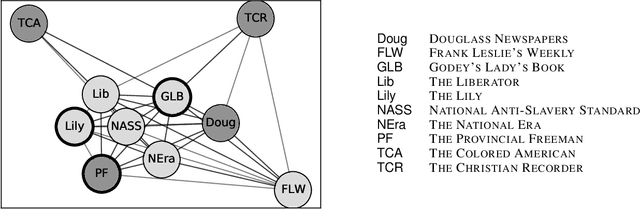
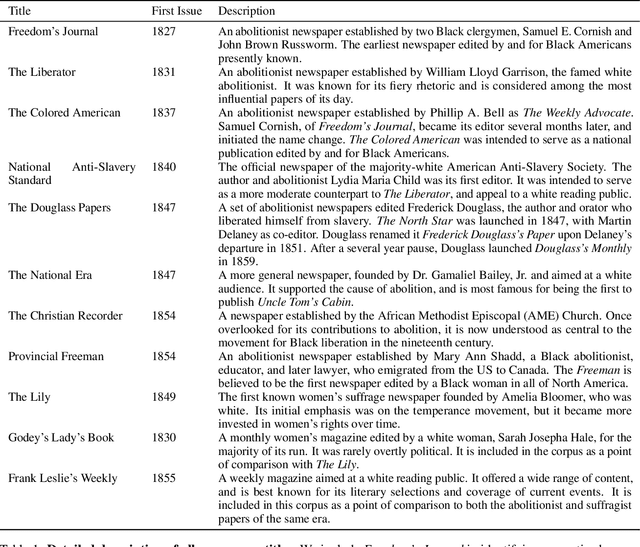

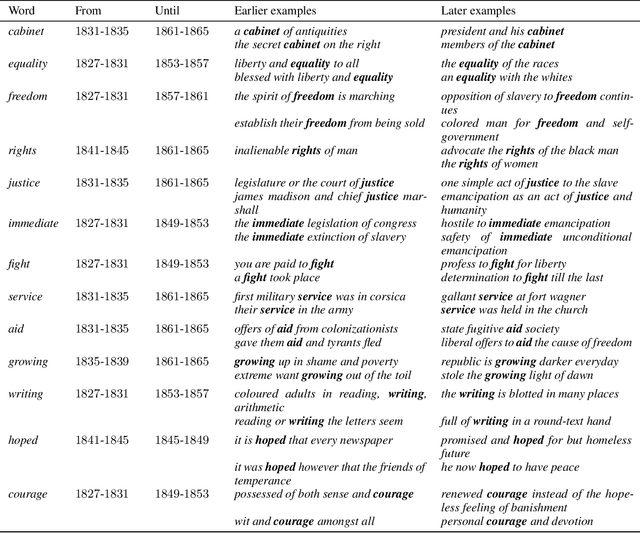
The abolitionist movement of the nineteenth-century United States remains among the most significant social and political movements in US history. Abolitionist newspapers played a crucial role in spreading information and shaping public opinion around a range of issues relating to the abolition of slavery. These newspapers also serve as a primary source of information about the movement for scholars today, resulting in powerful new accounts of the movement and its leaders. This paper supplements recent qualitative work on the role of women in abolition's vanguard, as well as the role of the Black press, with a quantitative text modeling approach. Using diachronic word embeddings, we identify which newspapers tended to lead lexical semantic innovations -- the introduction of new usages of specific words -- and which newspapers tended to follow. We then aggregate the evidence across hundreds of changes into a weighted network with the newspapers as nodes; directed edge weights represent the frequency with which each newspaper led the other in the adoption of a lexical semantic change. Analysis of this network reveals pathways of lexical semantic influence, distinguishing leaders from followers, as well as others who stood apart from the semantic changes that swept through this period. More specifically, we find that two newspapers edited by women -- THE PROVINCIAL FREEMAN and THE LILY -- led a large number of semantic changes in our corpus, lending additional credence to the argument that a multiracial coalition of women led the abolitionist movement in terms of both thought and action. It also contributes additional complexity to the scholarship that has sought to tease apart the relation of the abolitionist movement to the women's suffrage movement, and the vexed racial politics that characterized their relation.
* 23 pages, 6 figures, 2 tables
Tuiteamos o pongamos un tuit? Investigating the Social Constraints of Loanword Integration in Spanish Social Media
Jan 16, 2021
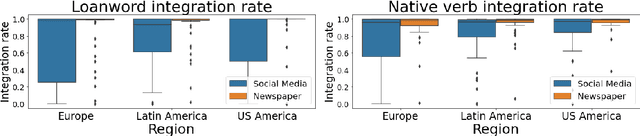

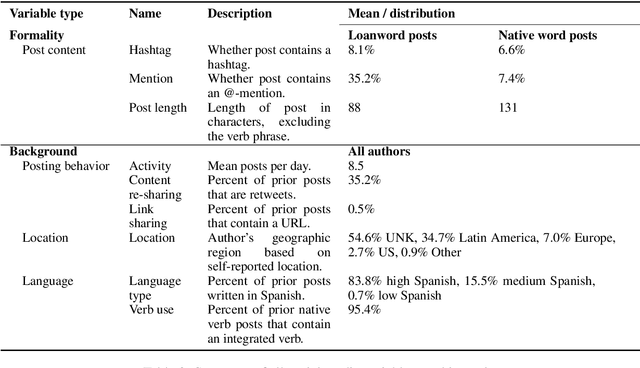
Speakers of non-English languages often adopt loanwords from English to express new or unusual concepts. While these loanwords may be borrowed unchanged, speakers may also integrate the words to fit the constraints of their native language, e.g. creating Spanish "tuitear" from English "tweet." Linguists have often considered the process of loanword integration to be more dependent on language-internal constraints, but sociolinguistic constraints such as speaker background remain only qualitatively understood. We investigate the role of social context and speaker background in Spanish speakers' use of integrated loanwords on social media. We find first that newspaper authors use the integrated forms of loanwords and native words more often than social media authors, showing that integration is associated with formal domains. In social media, we find that speaker background and expectations of formality explain loanword and native word integration, such that authors who use more Spanish and who write to a wider audience tend to use integrated verb forms more often. This study shows that loanword integration reflects not only language-internal constraints but also social expectations that vary by conversation and speaker.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Learning to Recognize Dialect Features
Oct 23, 2020
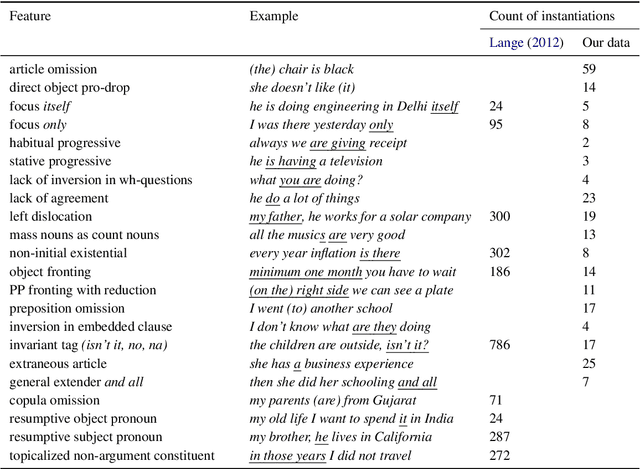
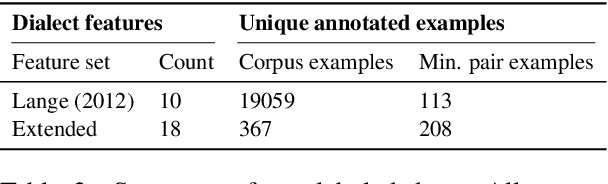
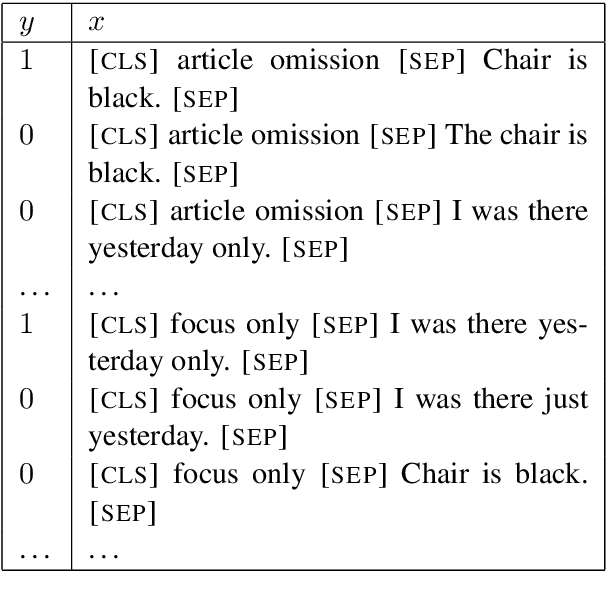
Linguists characterize dialects by the presence, absence, and frequency of dozens of interpretable features. Detecting these features in text has applications to social science and dialectology, and can be used to assess the robustness of natural language processing systems to dialect differences. For most dialects, large-scale annotated corpora for these features are unavailable, making it difficult to train recognizers. Linguists typically define dialect features by providing a small number of minimal pairs, which are paired examples distinguished only by whether the feature is present, while holding everything else constant. In this paper, we present two multitask learning architectures for recognizing dialect features, both based on pretrained transformers. We evaluate these models on two test sets of Indian English, annotated for a total of 22 dialect features. We find these models learn to recognize many features with high accuracy; crucially, a few minimal pairs can be nearly as effective for training as thousands of labeled examples. We also demonstrate the downstream applicability of our dialect feature detection model as a dialect density measure and as a dialect classifier.