 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
AlphaFlow: Understanding and Improving MeanFlow Models
Oct 23, 2025MeanFlow has recently emerged as a powerful framework for few-step generative modeling trained from scratch, but its success is not yet fully understood. In this work, we show that the MeanFlow objective naturally decomposes into two parts: trajectory flow matching and trajectory consistency. Through gradient analysis, we find that these terms are strongly negatively correlated, causing optimization conflict and slow convergence. Motivated by these insights, we introduce $\alpha$-Flow, a broad family of objectives that unifies trajectory flow matching, Shortcut Model, and MeanFlow under one formulation. By adopting a curriculum strategy that smoothly anneals from trajectory flow matching to MeanFlow, $\alpha$-Flow disentangles the conflicting objectives, and achieves better convergence. When trained from scratch on class-conditional ImageNet-1K 256x256 with vanilla DiT backbones, $\alpha$-Flow consistently outperforms MeanFlow across scales and settings. Our largest $\alpha$-Flow-XL/2+ model achieves new state-of-the-art results using vanilla DiT backbones, with FID scores of 2.58 (1-NFE) and 2.15 (2-NFE).
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025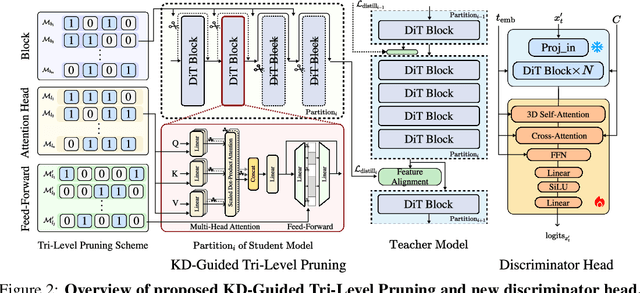
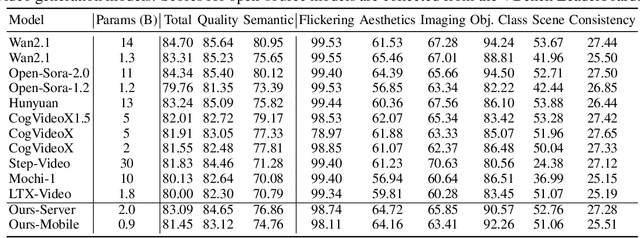

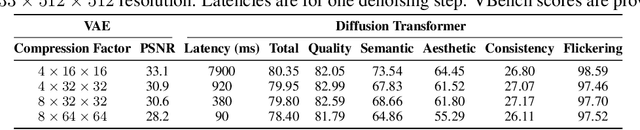
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.
Improving Progressive Generation with Decomposable Flow Matching
Jun 24, 2025



Generating high-dimensional visual modalities is a computationally intensive task. A common solution is progressive generation, where the outputs are synthesized in a coarse-to-fine spectral autoregressive manner. While diffusion models benefit from the coarse-to-fine nature of denoising, explicit multi-stage architectures are rarely adopted. These architectures have increased the complexity of the overall approach, introducing the need for a custom diffusion formulation, decomposition-dependent stage transitions, add-hoc samplers, or a model cascade. Our contribution, Decomposable Flow Matching (DFM), is a simple and effective framework for the progressive generation of visual media. DFM applies Flow Matching independently at each level of a user-defined multi-scale representation (such as Laplacian pyramid). As shown by our experiments, our approach improves visual quality for both images and videos, featuring superior results compared to prior multistage frameworks. On Imagenet-1k 512px, DFM achieves 35.2% improvements in FDD scores over the base architecture and 26.4% over the best-performing baseline, under the same training compute. When applied to finetuning of large models, such as FLUX, DFM shows faster convergence speed to the training distribution. Crucially, all these advantages are achieved with a single model, architectural simplicity, and minimal modifications to existing training pipelines.
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion Models
Apr 14, 2025Autoencoder (AE) is the key to the success of latent diffusion models for image and video generation, reducing the denoising resolution and improving efficiency. However, the power of AE has long been underexplored in terms of network design, compression ratio, and training strategy. In this work, we systematically examine the architecture design choices and optimize the computation distribution to obtain a series of efficient and high-compression video AEs that can decode in real time on mobile devices. We also unify the design of plain Autoencoder and image-conditioned I2V VAE, achieving multifunctionality in a single network. In addition, we find that the widely adopted discriminative losses, i.e., GAN, LPIPS, and DWT losses, provide no significant improvements when training AEs at scale. We propose a novel latent consistency loss that does not require complicated discriminator design or hyperparameter tuning, but provides stable improvements in reconstruction quality. Our AE achieves an ultra-high compression ratio and real-time decoding speed on mobile while outperforming prior art in terms of reconstruction metrics by a large margin. We finally validate our AE by training a DiT on its latent space and demonstrate fast, high-quality text-to-video generation capability.
Improving the Diffusability of Autoencoders
Feb 20, 2025Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.
Dynamic Concepts Personalization from Single Videos
Feb 20, 2025



Personalizing generative text-to-image models has seen remarkable progress, but extending this personalization to text-to-video models presents unique challenges. Unlike static concepts, personalizing text-to-video models has the potential to capture dynamic concepts, i.e., entities defined not only by their appearance but also by their motion. In this paper, we introduce Set-and-Sequence, a novel framework for personalizing Diffusion Transformers (DiTs)-based generative video models with dynamic concepts. Our approach imposes a spatio-temporal weight space within an architecture that does not explicitly separate spatial and temporal features. This is achieved in two key stages. First, we fine-tune Low-Rank Adaptation (LoRA) layers using an unordered set of frames from the video to learn an identity LoRA basis that represents the appearance, free from temporal interference. In the second stage, with the identity LoRAs frozen, we augment their coefficients with Motion Residuals and fine-tune them on the full video sequence, capturing motion dynamics. Our Set-and-Sequence framework results in a spatio-temporal weight space that effectively embeds dynamic concepts into the video model's output domain, enabling unprecedented editability and compositionality while setting a new benchmark for personalizing dynamic concepts.
Multi-subject Open-set Personalization in Video Generation
Jan 10, 2025



Video personalization methods allow us to synthesize videos with specific concepts such as people, pets, and places. However, existing methods often focus on limited domains, require time-consuming optimization per subject, or support only a single subject. We present Video Alchemist $-$ a video model with built-in multi-subject, open-set personalization capabilities for both foreground objects and background, eliminating the need for time-consuming test-time optimization. Our model is built on a new Diffusion Transformer module that fuses each conditional reference image and its corresponding subject-level text prompt with cross-attention layers. Developing such a large model presents two main challenges: dataset and evaluation. First, as paired datasets of reference images and videos are extremely hard to collect, we sample selected video frames as reference images and synthesize a clip of the target video. However, while models can easily denoise training videos given reference frames, they fail to generalize to new contexts. To mitigate this issue, we design a new automatic data construction pipeline with extensive image augmentations. Second, evaluating open-set video personalization is a challenge in itself. To address this, we introduce a personalization benchmark that focuses on accurate subject fidelity and supports diverse personalization scenarios. Finally, our extensive experiments show that our method significantly outperforms existing personalization methods in both quantitative and qualitative evaluations.
AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Dec 19, 2024



We propose AV-Link, a unified framework for Video-to-Audio and Audio-to-Video generation that leverages the activations of frozen video and audio diffusion models for temporally-aligned cross-modal conditioning. The key to our framework is a Fusion Block that enables bidirectional information exchange between our backbone video and audio diffusion models through a temporally-aligned self attention operation. Unlike prior work that uses feature extractors pretrained for other tasks for the conditioning signal, AV-Link can directly leverage features obtained by the complementary modality in a single framework i.e. video features to generate audio, or audio features to generate video. We extensively evaluate our design choices and demonstrate the ability of our method to achieve synchronized and high-quality audiovisual content, showcasing its potential for applications in immersive media generation. Project Page: snap-research.github.io/AVLink/