 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Adversarial Contrastive Learning for Self-supervised Adversarial Robustness
Jul 22, 2022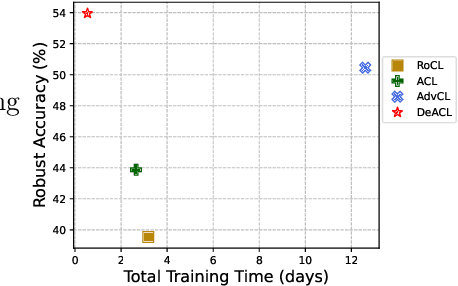
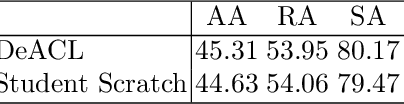
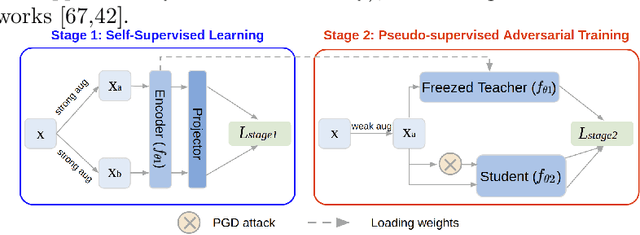
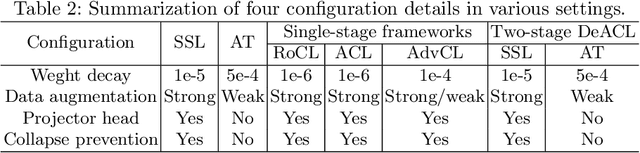
Adversarial training (AT) for robust representation learning and self-supervised learning (SSL) for unsupervised representation learning are two active research fields. Integrating AT into SSL, multiple prior works have accomplished a highly significant yet challenging task: learning robust representation without labels. A widely used framework is adversarial contrastive learning which couples AT and SSL, and thus constitute a very complex optimization problem. Inspired by the divide-and-conquer philosophy, we conjecture that it might be simplified as well as improved by solving two sub-problems: non-robust SSL and pseudo-supervised AT. This motivation shifts the focus of the task from seeking an optimal integrating strategy for a coupled problem to finding sub-solutions for sub-problems. With this said, this work discards prior practices of directly introducing AT to SSL frameworks and proposed a two-stage framework termed Decoupled Adversarial Contrastive Learning (DeACL). Extensive experimental results demonstrate that our DeACL achieves SOTA self-supervised adversarial robustness while significantly reducing the training time, which validates its effectiveness and efficiency. Moreover, our DeACL constitutes a more explainable solution, and its success also bridges the gap with semi-supervised AT for exploiting unlabeled samples for robust representation learning. The code is publicly accessible at https://github.com/pantheon5100/DeACL.
The Anatomy of Video Editing: A Dataset and Benchmark Suite for AI-Assisted Video Editing
Jul 21, 2022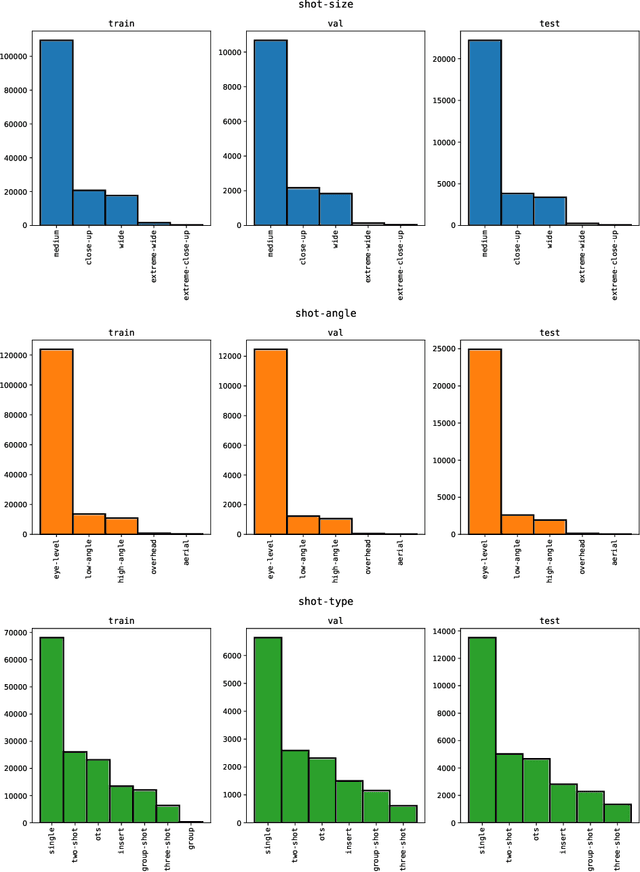
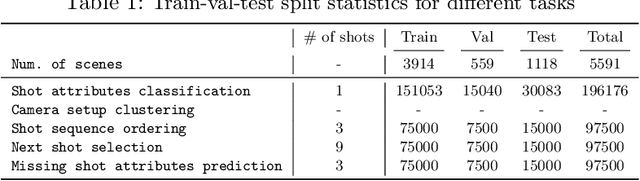
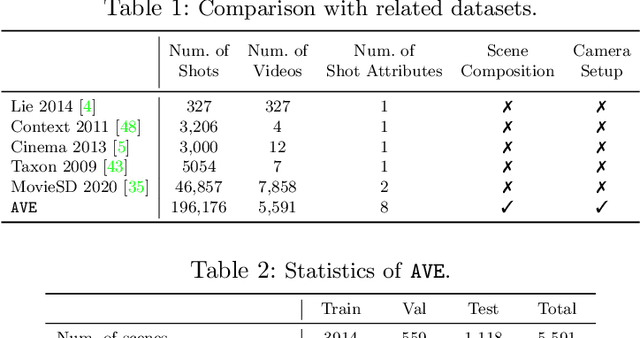
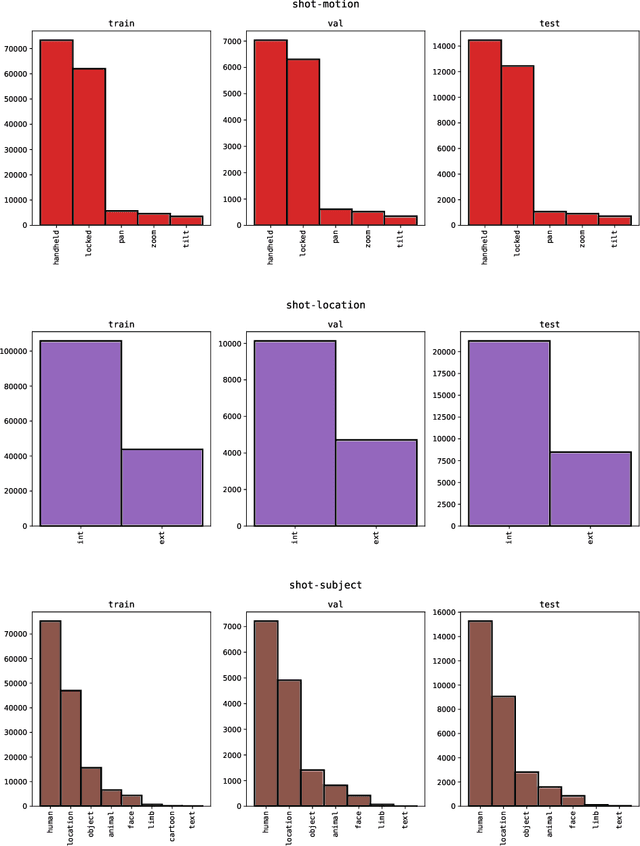
Machine learning is transforming the video editing industry. Recent advances in computer vision have leveled-up video editing tasks such as intelligent reframing, rotoscoping, color grading, or applying digital makeups. However, most of the solutions have focused on video manipulation and VFX. This work introduces the Anatomy of Video Editing, a dataset, and benchmark, to foster research in AI-assisted video editing. Our benchmark suite focuses on video editing tasks, beyond visual effects, such as automatic footage organization and assisted video assembling. To enable research on these fronts, we annotate more than 1.5M tags, with relevant concepts to cinematography, from 196176 shots sampled from movie scenes. We establish competitive baseline methods and detailed analyses for each of the tasks. We hope our work sparks innovative research towards underexplored areas of AI-assisted video editing.
ML-BPM: Multi-teacher Learning with Bidirectional Photometric Mixing for Open Compound Domain Adaptation in Semantic Segmentation
Jul 19, 2022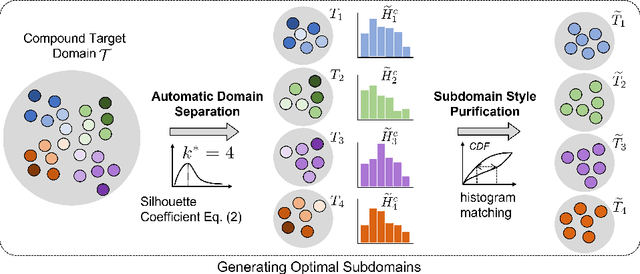
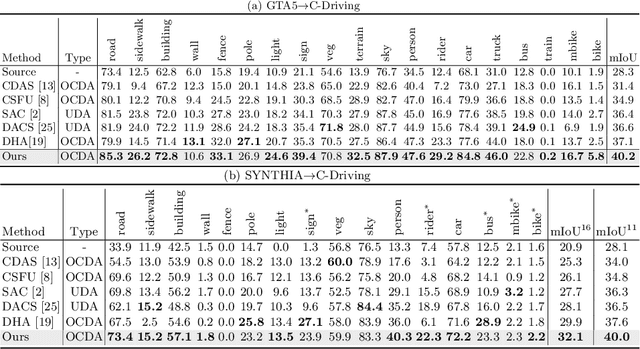

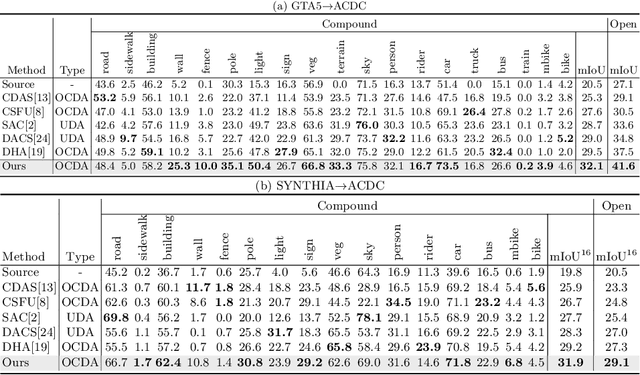
Open compound domain adaptation (OCDA) considers the target domain as the compound of multiple unknown homogeneous subdomains. The goal of OCDA is to minimize the domain gap between the labeled source domain and the unlabeled compound target domain, which benefits the model generalization to the unseen domains. Current OCDA for semantic segmentation methods adopt manual domain separation and employ a single model to simultaneously adapt to all the target subdomains. However, adapting to a target subdomain might hinder the model from adapting to other dissimilar target subdomains, which leads to limited performance. In this work, we introduce a multi-teacher framework with bidirectional photometric mixing to separately adapt to every target subdomain. First, we present an automatic domain separation to find the optimal number of subdomains. On this basis, we propose a multi-teacher framework in which each teacher model uses bidirectional photometric mixing to adapt to one target subdomain. Furthermore, we conduct an adaptive distillation to learn a student model and apply consistency regularization to improve the student generalization. Experimental results on benchmark datasets show the efficacy of the proposed approach for both the compound domain and the open domains against existing state-of-the-art approaches.
DRL-ISP: Multi-Objective Camera ISP with Deep Reinforcement Learning
Jul 07, 2022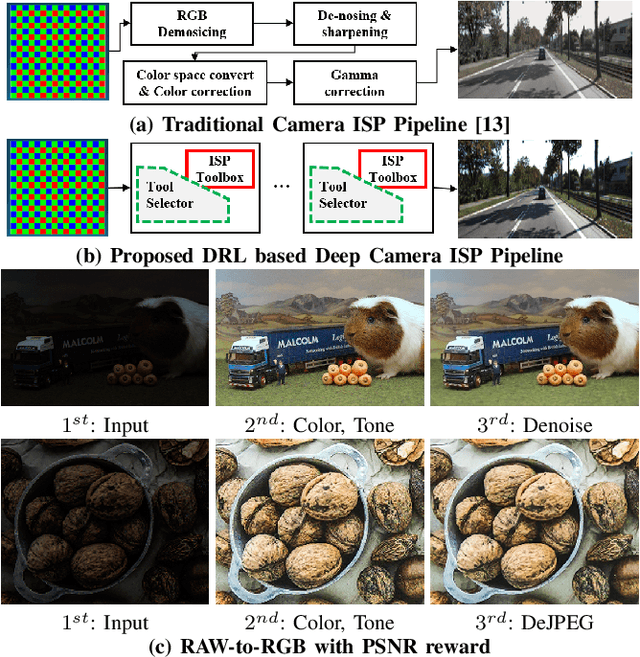
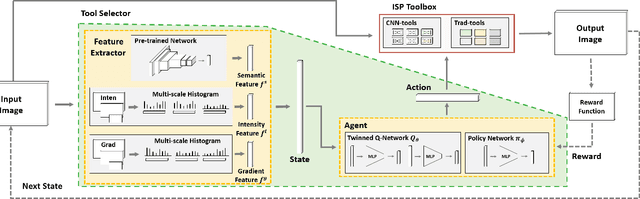

In this paper, we propose a multi-objective camera ISP framework that utilizes Deep Reinforcement Learning (DRL) and camera ISP toolbox that consist of network-based and conventional ISP tools. The proposed DRL-based camera ISP framework iteratively selects a proper tool from the toolbox and applies it to the image to maximize a given vision task-specific reward function. For this purpose, we implement total 51 ISP tools that include exposure correction, color-and-tone correction, white balance, sharpening, denoising, and the others. We also propose an efficient DRL network architecture that can extract the various aspects of an image and make a rigid mapping relationship between images and a large number of actions. Our proposed DRL-based ISP framework effectively improves the image quality according to each vision task such as RAW-to-RGB image restoration, 2D object detection, and monocular depth estimation.
Labeling Where Adapting Fails: Cross-Domain Semantic Segmentation with Point Supervision via Active Selection
Jun 04, 2022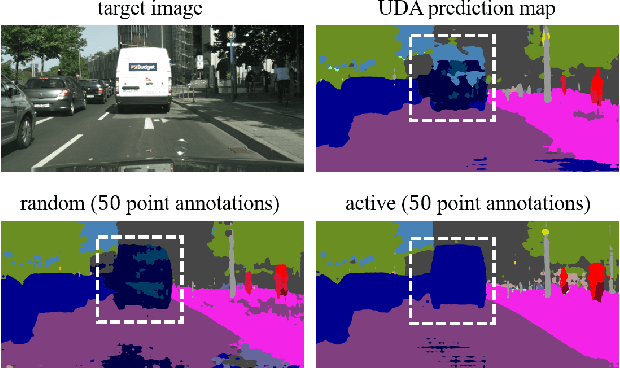
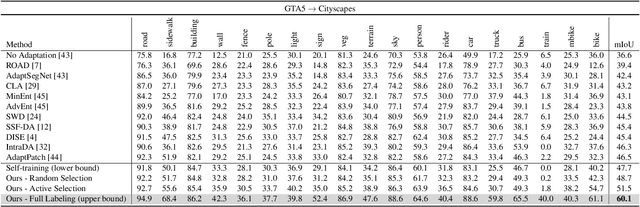
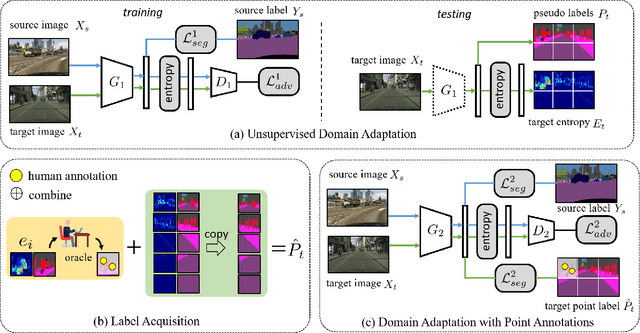
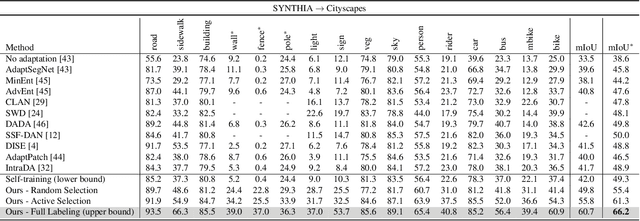
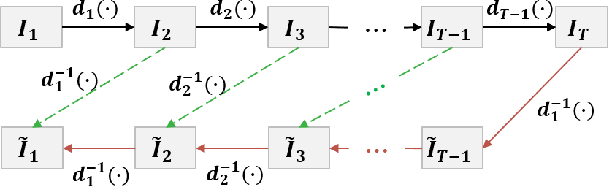
Training models dedicated to semantic segmentation requires a large amount of pixel-wise annotated data. Due to their costly nature, these annotations might not be available for the task at hand. To alleviate this problem, unsupervised domain adaptation approaches aim at aligning the feature distributions between the labeled source and the unlabeled target data. While these strategies lead to noticeable improvements, their effectiveness remains limited. To guide the domain adaptation task more efficiently, previous works attempted to include human interactions in this process under the form of sparse single-pixel annotations in the target data. In this work, we propose a new domain adaptation framework for semantic segmentation with annotated points via active selection. First, we conduct an unsupervised domain adaptation of the model; from this adaptation, we use an entropy-based uncertainty measurement for target points selection. Finally, to minimize the domain gap, we propose a domain adaptation framework utilizing these target points annotated by human annotators. Experimental results on benchmark datasets show the effectiveness of our methods against existing unsupervised domain adaptation approaches. The propose pipeline is generic and can be included as an extra module to existing domain adaptation strategies.
TubeFormer-DeepLab: Video Mask Transformer
May 30, 2022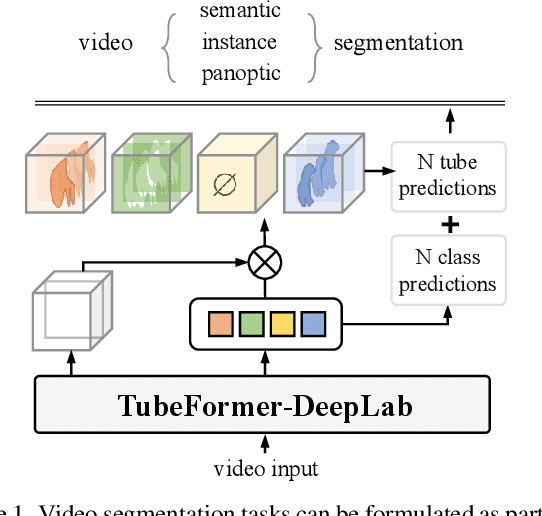
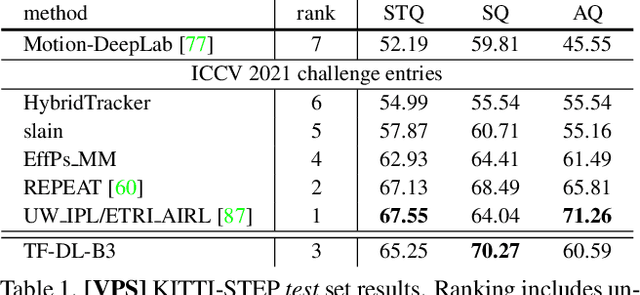
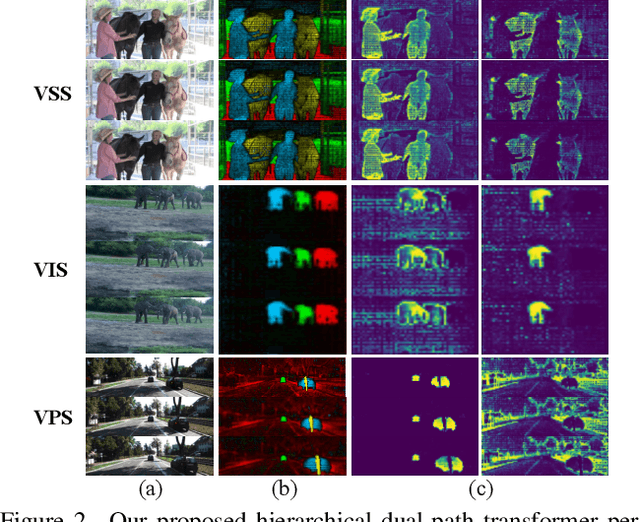
We present TubeFormer-DeepLab, the first attempt to tackle multiple core video segmentation tasks in a unified manner. Different video segmentation tasks (e.g., video semantic/instance/panoptic segmentation) are usually considered as distinct problems. State-of-the-art models adopted in the separate communities have diverged, and radically different approaches dominate in each task. By contrast, we make a crucial observation that video segmentation tasks could be generally formulated as the problem of assigning different predicted labels to video tubes (where a tube is obtained by linking segmentation masks along the time axis) and the labels may encode different values depending on the target task. The observation motivates us to develop TubeFormer-DeepLab, a simple and effective video mask transformer model that is widely applicable to multiple video segmentation tasks. TubeFormer-DeepLab directly predicts video tubes with task-specific labels (either pure semantic categories, or both semantic categories and instance identities), which not only significantly simplifies video segmentation models, but also advances state-of-the-art results on multiple video segmentation benchmarks
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022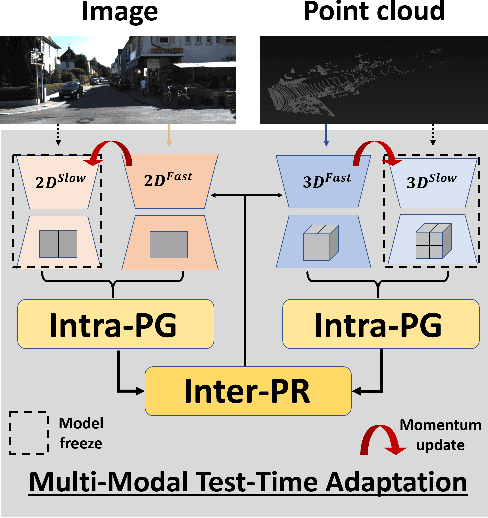
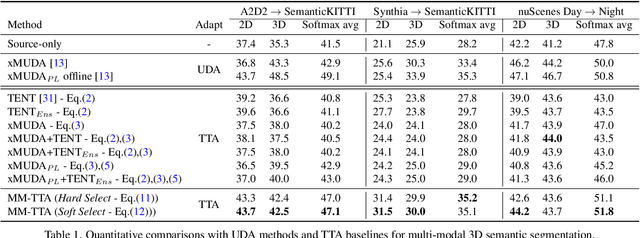
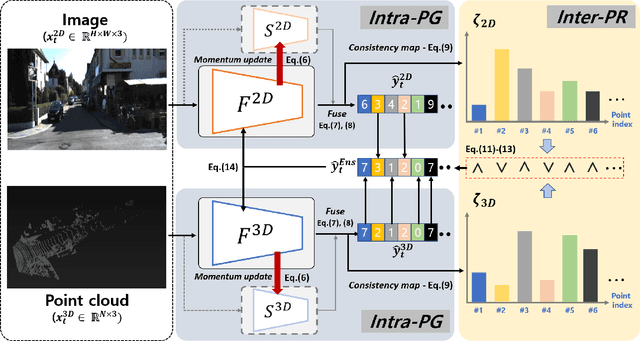
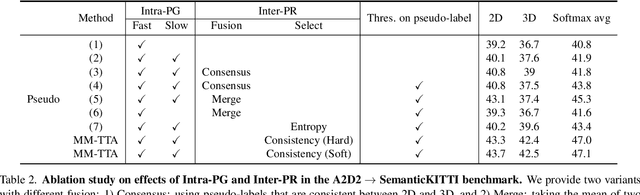
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
Investigating Top-$k$ White-Box and Transferable Black-box Attack
Mar 30, 2022
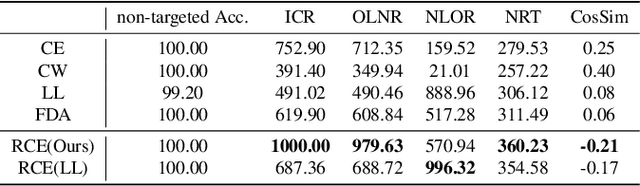


Existing works have identified the limitation of top-$1$ attack success rate (ASR) as a metric to evaluate the attack strength but exclusively investigated it in the white-box setting, while our work extends it to a more practical black-box setting: transferable attack. It is widely reported that stronger I-FGSM transfers worse than simple FGSM, leading to a popular belief that transferability is at odds with the white-box attack strength. Our work challenges this belief with empirical finding that stronger attack actually transfers better for the general top-$k$ ASR indicated by the interest class rank (ICR) after attack. For increasing the attack strength, with an intuitive interpretation of the logit gradient from the geometric perspective, we identify that the weakness of the commonly used losses lie in prioritizing the speed to fool the network instead of maximizing its strength. To this end, we propose a new normalized CE loss that guides the logit to be updated in the direction of implicitly maximizing its rank distance from the ground-truth class. Extensive results in various settings have verified that our proposed new loss is simple yet effective for top-$k$ attack. Code is available at: \url{https://bit.ly/3uCiomP}
Dual Temperature Helps Contrastive Learning Without Many Negative Samples: Towards Understanding and Simplifying MoCo
Mar 30, 2022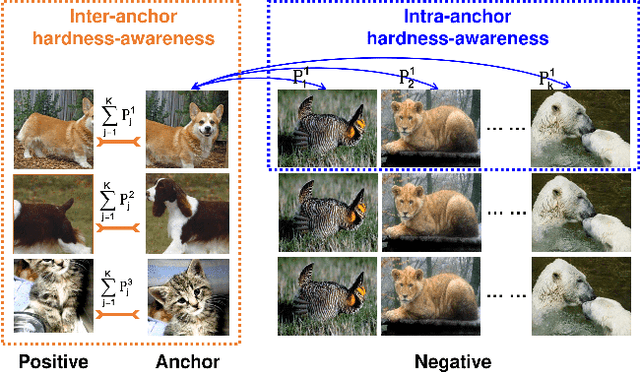

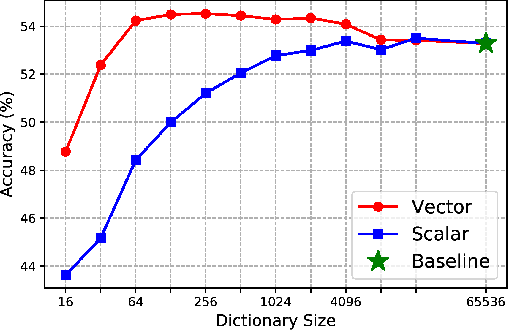
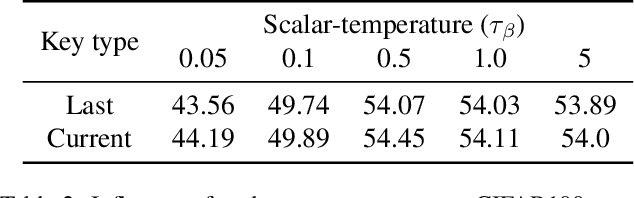
Contrastive learning (CL) is widely known to require many negative samples, 65536 in MoCo for instance, for which the performance of a dictionary-free framework is often inferior because the negative sample size (NSS) is limited by its mini-batch size (MBS). To decouple the NSS from the MBS, a dynamic dictionary has been adopted in a large volume of CL frameworks, among which arguably the most popular one is MoCo family. In essence, MoCo adopts a momentum-based queue dictionary, for which we perform a fine-grained analysis of its size and consistency. We point out that InfoNCE loss used in MoCo implicitly attract anchors to their corresponding positive sample with various strength of penalties and identify such inter-anchor hardness-awareness property as a major reason for the necessity of a large dictionary. Our findings motivate us to simplify MoCo v2 via the removal of its dictionary as well as momentum. Based on an InfoNCE with the proposed dual temperature, our simplified frameworks, SimMoCo and SimCo, outperform MoCo v2 by a visible margin. Moreover, our work bridges the gap between CL and non-CL frameworks, contributing to a more unified understanding of these two mainstream frameworks in SSL. Code is available at: https://bit.ly/3LkQbaT.
How Does SimSiam Avoid Collapse Without Negative Samples? A Unified Understanding with Self-supervised Contrastive Learning
Mar 30, 2022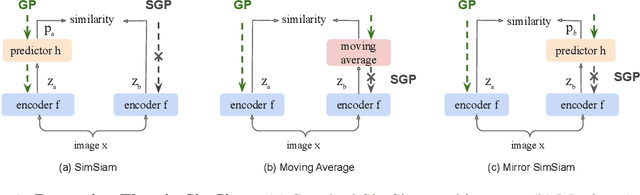
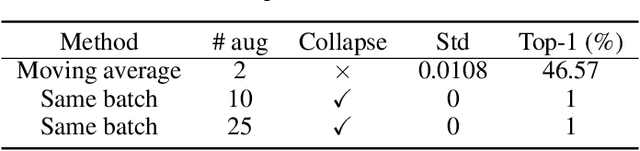
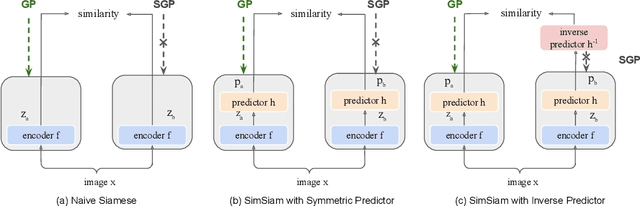
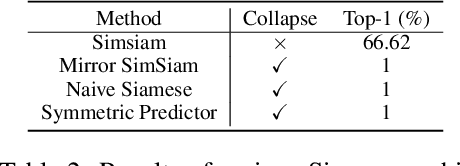
To avoid collapse in self-supervised learning (SSL), a contrastive loss is widely used but often requires a large number of negative samples. Without negative samples yet achieving competitive performance, a recent work has attracted significant attention for providing a minimalist simple Siamese (SimSiam) method to avoid collapse. However, the reason for how it avoids collapse without negative samples remains not fully clear and our investigation starts by revisiting the explanatory claims in the original SimSiam. After refuting their claims, we introduce vector decomposition for analyzing the collapse based on the gradient analysis of the $l_2$-normalized representation vector. This yields a unified perspective on how negative samples and SimSiam alleviate collapse. Such a unified perspective comes timely for understanding the recent progress in SSL.