 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Foundation Models for Unsupervised Domain Adaptation
May 05, 2026Semantic segmentation provides pixel-level scene understanding essential for autonomous driving and fine-grained perception tasks. However, training segmentation models requires costly, labor-intensive annotations on real-world datasets. Unsupervised Domain Adaptation (UDA) addresses this by training models on labeled synthetic data and adapting them to unlabeled real images. While conceptually simple, adaptation is challenging due to the domain gap, i.e., differences in visual appearance and scene structure between synthetic and real data. Prior approaches bridge this gap through pixel-level mixing or feature-level contrastive learning. Yet, these techniques suffer from two major limitations: (1) reliance on high-confidence pseudo-labels restricts learning to a subset of the target domain, and (2) prototype-based contrastive methods initialize class prototypes from source-trained models, yielding biased and unstable anchors during adaptation. To address these issues, we propose a dual-foundation UDA framework that leverages two complementary foundation models. First, we employ the Segment Anything Model (SAM) with superpixel-guided prompting to enable learning from a broader range of target pixels beyond high-confidence predictions. Second, we incorporate DINOv3 to construct stable, domain-invariant class prototypes through its robust representation learning. Our method achieves consistent improvements of +1.3% and +1.4% mIoU over strong UDA baselines on GTA-to-Cityscapes and SYNTHIA-to-Cityscapes, respectively.
Pixel-Accurate Epipolar Guided Matching
Mar 19, 2026Keypoint matching can be slow and unreliable in challenging conditions such as repetitive textures or wide-baseline views. In such cases, known geometric relations (e.g., the fundamental matrix) can be used to restrict potential correspondences to a narrow epipolar envelope, thereby reducing the search space and improving robustness. These epipolar-guided matching approaches have proved effective in tasks such as SfM; however, most rely on coarse spatial binning, which introduces approximation errors, requires costly post-processing, and may miss valid correspondences. We address these limitations with an exact formulation that performs candidate selection directly in angular space. In our approach, each keypoint is assigned a tolerance circle which, when viewed from the epipole, defines an angular interval. Matching then becomes a 1D angular interval query, solved efficiently in logarithmic time with a segment tree. This guarantees pixel-level tolerance, supports per-keypoint control, and removes unnecessary descriptor comparisons. Extensive evaluation on ETH3D demonstrates noticeable speedups over existing approaches while recovering exact correspondence sets.
Detecting Regional Spurious Correlations in Vision Transformers via Token Discarding
Sep 04, 2025



Due to their powerful feature association capabilities, neural network-based computer vision models have the ability to detect and exploit unintended patterns within the data, potentially leading to correct predictions based on incorrect or unintended but statistically relevant signals. These clues may vary from simple color aberrations to small texts within the image. In situations where these unintended signals align with the predictive task, models can mistakenly link these features with the task and rely on them for making predictions. This phenomenon is referred to as spurious correlations, where patterns appear to be associated with the task but are actually coincidental. As a result, detection and mitigation of spurious correlations have become crucial tasks for building trustworthy, reliable, and generalizable machine learning models. In this work, we present a novel method to detect spurious correlations in vision transformers, a type of neural network architecture that gained significant popularity in recent years. Using both supervised and self-supervised trained models, we present large-scale experiments on the ImageNet dataset demonstrating the ability of the proposed method to identify spurious correlations. We also find that, even if the same architecture is used, the training methodology has a significant impact on the model's reliance on spurious correlations. Furthermore, we show that certain classes in the ImageNet dataset contain spurious signals that are easily detected by the models and discuss the underlying reasons for those spurious signals. In light of our findings, we provide an exhaustive list of the aforementioned images and call for caution in their use in future research efforts. Lastly, we present a case study investigating spurious signals in invasive breast mass classification, grounding our work in real-world scenarios.
Exploring Patient Data Requirements in Training Effective AI Models for MRI-based Breast Cancer Classification
Feb 22, 2025The past decade has witnessed a substantial increase in the number of startups and companies offering AI-based solutions for clinical decision support in medical institutions. However, the critical nature of medical decision-making raises several concerns about relying on external software. Key issues include potential variations in image modalities and the medical devices used to obtain these images, potential legal issues, and adversarial attacks. Fortunately, the open-source nature of machine learning research has made foundation models publicly available and straightforward to use for medical applications. This accessibility allows medical institutions to train their own AI-based models, thereby mitigating the aforementioned concerns. Given this context, an important question arises: how much data do medical institutions need to train effective AI models? In this study, we explore this question in relation to breast cancer detection, a particularly contested area due to the prevalence of this disease, which affects approximately 1 in every 8 women. Through large-scale experiments on various patient sizes in the training set, we show that medical institutions do not need a decade's worth of MRI images to train an AI model that performs competitively with the state-of-the-art, provided the model leverages foundation models. Furthermore, we observe that for patient counts greater than 50, the number of patients in the training set has a negligible impact on the performance of models and that simple ensembles further improve the results without additional complexity.
360 in the Wild: Dataset for Depth Prediction and View Synthesis
Jun 27, 2024



The large abundance of perspective camera datasets facilitated the emergence of novel learning-based strategies for various tasks, such as camera localization, single image depth estimation, or view synthesis. However, panoramic or omnidirectional image datasets, including essential information, such as pose and depth, are mostly made with synthetic scenes. In this work, we introduce a large scale 360$^{\circ}$ videos dataset in the wild. This dataset has been carefully scraped from the Internet and has been captured from various locations worldwide. Hence, this dataset exhibits very diversified environments (e.g., indoor and outdoor) and contexts (e.g., with and without moving objects). Each of the 25K images constituting our dataset is provided with its respective camera's pose and depth map. We illustrate the relevance of our dataset for two main tasks, namely, single image depth estimation and view synthesis.
In Defense of Pure 16-bit Floating-Point Neural Networks
May 18, 2023Reducing the number of bits needed to encode the weights and activations of neural networks is highly desirable as it speeds up their training and inference time while reducing memory consumption. For these reasons, research in this area has attracted significant attention toward developing neural networks that leverage lower-precision computing, such as mixed-precision training. Interestingly, none of the existing approaches has investigated pure 16-bit floating-point settings. In this paper, we shed light on the overlooked efficiency of pure 16-bit floating-point neural networks. As such, we provide a comprehensive theoretical analysis to investigate the factors contributing to the differences observed between 16-bit and 32-bit models. We formalize the concepts of floating-point error and tolerance, enabling us to quantitatively explain the conditions under which a 16-bit model can closely approximate the results of its 32-bit counterpart. This theoretical exploration offers perspective that is distinct from the literature which attributes the success of low-precision neural networks to its regularization effect. This in-depth analysis is supported by an extensive series of experiments. Our findings demonstrate that pure 16-bit floating-point neural networks can achieve similar or even better performance than their mixed-precision and 32-bit counterparts. We believe the results presented in this paper will have significant implications for machine learning practitioners, offering an opportunity to reconsider using pure 16-bit networks in various applications.
Generative AI meets 3D: A Survey on Text-to-3D in AIGC Era
May 10, 2023



Generative AI (AIGC, a.k.a. AI generated content) has made remarkable progress in the past few years, among which text-guided content generation is the most practical one since it enables the interaction between human instruction and AIGC. Due to the development in text-to-image as well 3D modeling technologies (like NeRF), text-to-3D has become a newly emerging yet highly active research field. Our work conducts the first yet comprehensive survey on text-to-3D to help readers interested in this direction quickly catch up with its fast development. First, we introduce 3D data representations, including both Euclidean data and non-Euclidean data. On top of that, we introduce various foundation technologies as well as summarize how recent works combine those foundation technologies to realize satisfactory text-to-3D. Moreover, we summarize how text-to-3D technology is used in various applications, including avatar generation, texture generation, shape transformation, and scene generation.
InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
Jan 10, 2023



The construction of lightweight High-definition (HD) maps containing geometric and semantic information is of foremost importance for the large-scale deployment of autonomous driving. To automatically generate such type of map from a set of images captured by a vehicle, most works formulate this mapping as a segmentation problem, which implies heavy post-processing to obtain the final vectorized representation. Alternative techniques have the ability to generate an HD map in an end-to-end manner but rely on computationally expensive auto-regressive models. To bring camera-based to an applicable level, we propose InstaGraM, a fast end-to-end network generating a vectorized HD map via instance-level graph modeling of the map elements. Our strategy consists of three main stages: top-view feature extraction, road elements' vertices and edges detection, and conversion to a semantic vector representation. After top-down feature extraction, an encoder-decoder architecture is utilized to predict a set of vertices and edge maps of the road elements. Finally, these vertices along with edge maps are associated through an attentional graph neural network generating a semantic vectorized map. Instead of relying on a common segmentation approach, we propose to regress distance transform maps as they provide strong spatial relations and directional information between vertices. Comprehensive experiments on nuScenes dataset show that our proposed network outperforms HDMapNet by 13.7 mAP and achieves comparable accuracy with VectorMapNet 5x faster inference speed.
Labeling Where Adapting Fails: Cross-Domain Semantic Segmentation with Point Supervision via Active Selection
Jun 04, 2022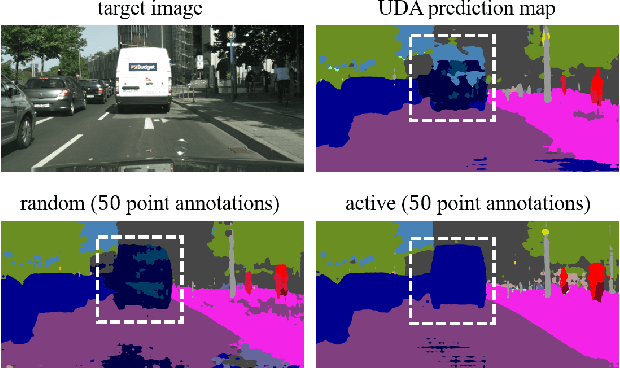
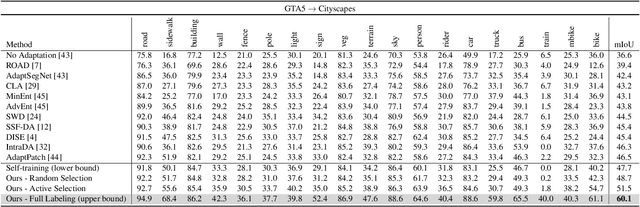
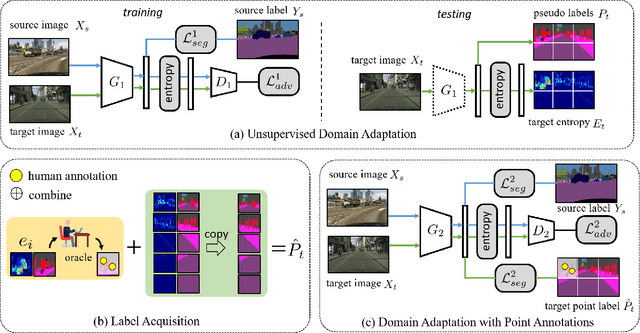
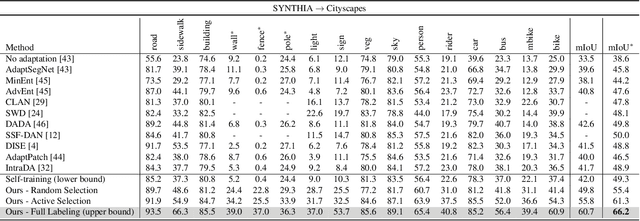
Training models dedicated to semantic segmentation requires a large amount of pixel-wise annotated data. Due to their costly nature, these annotations might not be available for the task at hand. To alleviate this problem, unsupervised domain adaptation approaches aim at aligning the feature distributions between the labeled source and the unlabeled target data. While these strategies lead to noticeable improvements, their effectiveness remains limited. To guide the domain adaptation task more efficiently, previous works attempted to include human interactions in this process under the form of sparse single-pixel annotations in the target data. In this work, we propose a new domain adaptation framework for semantic segmentation with annotated points via active selection. First, we conduct an unsupervised domain adaptation of the model; from this adaptation, we use an entropy-based uncertainty measurement for target points selection. Finally, to minimize the domain gap, we propose a domain adaptation framework utilizing these target points annotated by human annotators. Experimental results on benchmark datasets show the effectiveness of our methods against existing unsupervised domain adaptation approaches. The propose pipeline is generic and can be included as an extra module to existing domain adaptation strategies.
Keypoints Tracking via Transformer Networks
Mar 24, 2022
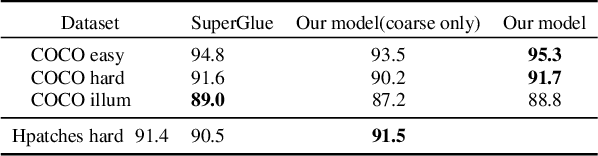
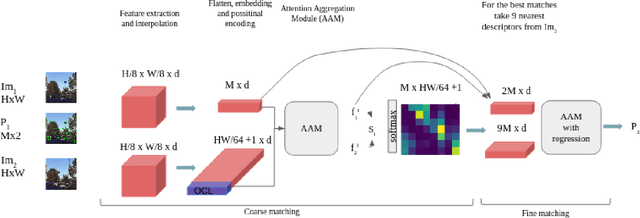

In this thesis, we propose a pioneering work on sparse keypoints tracking across images using transformer networks. While deep learning-based keypoints matching have been widely investigated using graph neural networks - and more recently transformer networks, they remain relatively too slow to operate in real-time and are particularly sensitive to the poor repeatability of the keypoints detectors. In order to address these shortcomings, we propose to study the particular case of real-time and robust keypoints tracking. Specifically, we propose a novel architecture which ensures a fast and robust estimation of the keypoints tracking between successive images of a video sequence. Our method takes advantage of a recent breakthrough in computer vision, namely, visual transformer networks. Our method consists of two successive stages, a coarse matching followed by a fine localization of the keypoints' correspondences prediction. Through various experiments, we demonstrate that our approach achieves competitive results and demonstrates high robustness against adverse conditions, such as illumination change, occlusion and viewpoint differences.