 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Variational Inference with Inverse Autoregressive Flow
Jan 30, 2017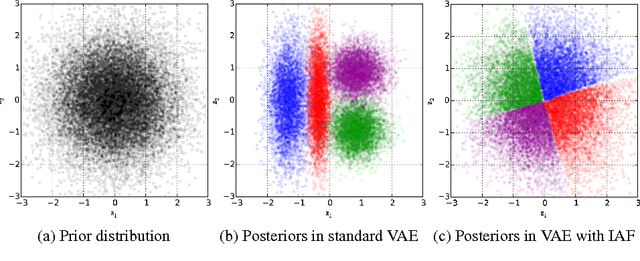
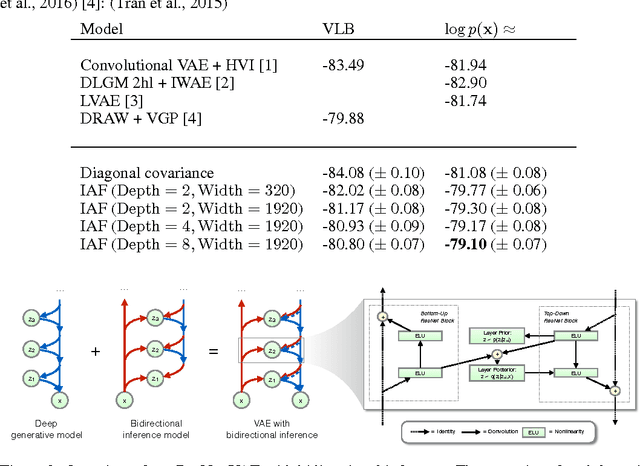
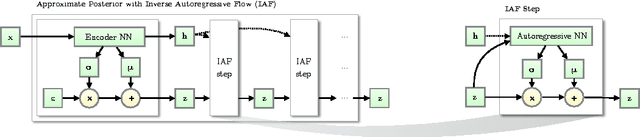
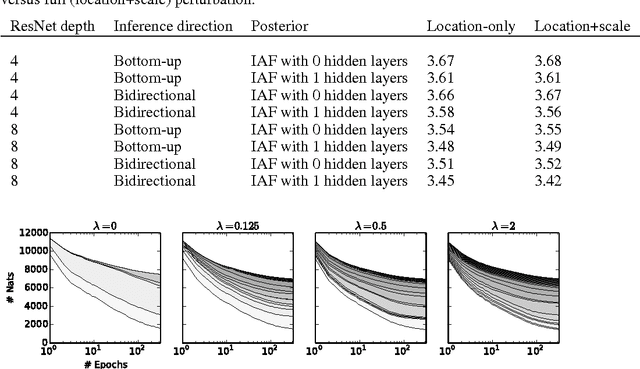
The framework of normalizing flows provides a general strategy for flexible variational inference of posteriors over latent variables. We propose a new type of normalizing flow, inverse autoregressive flow (IAF), that, in contrast to earlier published flows, scales well to high-dimensional latent spaces. The proposed flow consists of a chain of invertible transformations, where each transformation is based on an autoregressive neural network. In experiments, we show that IAF significantly improves upon diagonal Gaussian approximate posteriors. In addition, we demonstrate that a novel type of variational autoencoder, coupled with IAF, is competitive with neural autoregressive models in terms of attained log-likelihood on natural images, while allowing significantly faster synthesis.
RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
Nov 10, 2016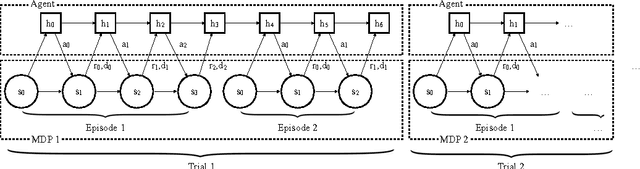
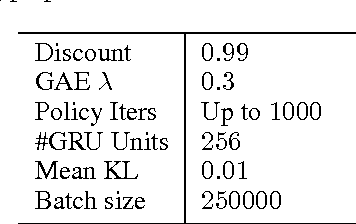
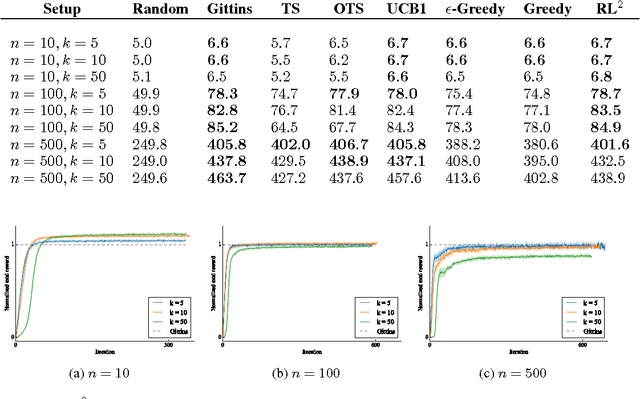

Deep reinforcement learning (deep RL) has been successful in learning sophisticated behaviors automatically; however, the learning process requires a huge number of trials. In contrast, animals can learn new tasks in just a few trials, benefiting from their prior knowledge about the world. This paper seeks to bridge this gap. Rather than designing a "fast" reinforcement learning algorithm, we propose to represent it as a recurrent neural network (RNN) and learn it from data. In our proposed method, RL$^2$, the algorithm is encoded in the weights of the RNN, which are learned slowly through a general-purpose ("slow") RL algorithm. The RNN receives all information a typical RL algorithm would receive, including observations, actions, rewards, and termination flags; and it retains its state across episodes in a given Markov Decision Process (MDP). The activations of the RNN store the state of the "fast" RL algorithm on the current (previously unseen) MDP. We evaluate RL$^2$ experimentally on both small-scale and large-scale problems. On the small-scale side, we train it to solve randomly generated multi-arm bandit problems and finite MDPs. After RL$^2$ is trained, its performance on new MDPs is close to human-designed algorithms with optimality guarantees. On the large-scale side, we test RL$^2$ on a vision-based navigation task and show that it scales up to high-dimensional problems.
Extensions and Limitations of the Neural GPU
Nov 04, 2016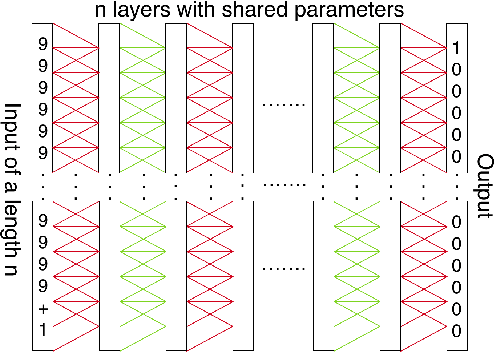

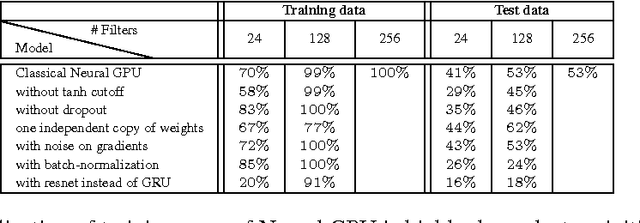
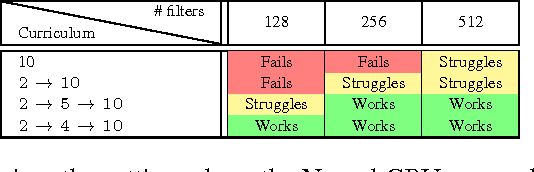
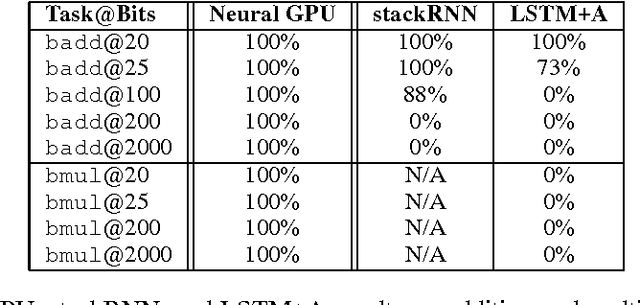
The Neural GPU is a recent model that can learn algorithms such as multi-digit binary addition and binary multiplication in a way that generalizes to inputs of arbitrary length. We show that there are two simple ways of improving the performance of the Neural GPU: by carefully designing a curriculum, and by increasing model size. The latter requires a memory efficient implementation, as a naive implementation of the Neural GPU is memory intensive. We find that these techniques increase the set of algorithmic problems that can be solved by the Neural GPU: we have been able to learn to perform all the arithmetic operations (and generalize to arbitrarily long numbers) when the arguments are given in the decimal representation (which, surprisingly, has not been possible before). We have also been able to train the Neural GPU to evaluate long arithmetic expressions with multiple operands that require respecting the precedence order of the operands, although these have succeeded only in their binary representation, and not with perfect accuracy. In addition, we gain insight into the Neural GPU by investigating its failure modes. We find that Neural GPUs that correctly generalize to arbitrarily long numbers still fail to compute the correct answer on highly-symmetric, atypical inputs: for example, a Neural GPU that achieves near-perfect generalization on decimal multiplication of up to 100-digit long numbers can fail on $000000\dots002 \times 000000\dots002$ while succeeding at $2 \times 2$. These failure modes are reminiscent of adversarial examples.
A Neural Transducer
Aug 04, 2016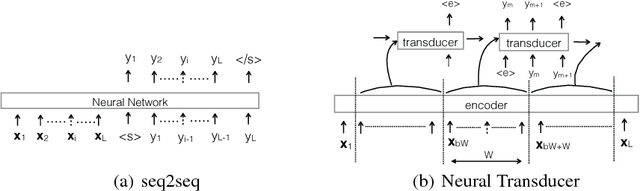

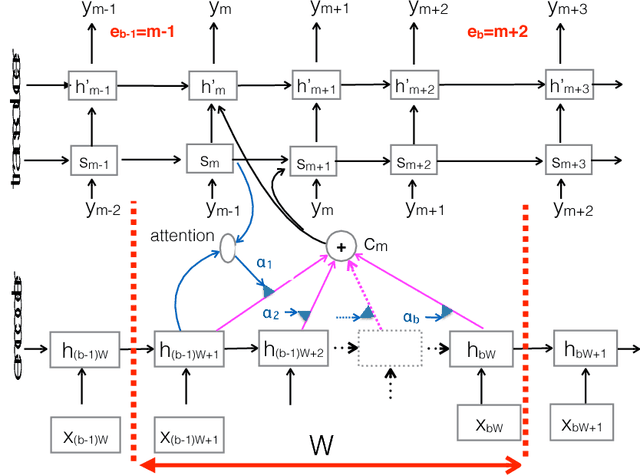
Sequence-to-sequence models have achieved impressive results on various tasks. However, they are unsuitable for tasks that require incremental predictions to be made as more data arrives or tasks that have long input sequences and output sequences. This is because they generate an output sequence conditioned on an entire input sequence. In this paper, we present a Neural Transducer that can make incremental predictions as more input arrives, without redoing the entire computation. Unlike sequence-to-sequence models, the Neural Transducer computes the next-step distribution conditioned on the partially observed input sequence and the partially generated sequence. At each time step, the transducer can decide to emit zero to many output symbols. The data can be processed using an encoder and presented as input to the transducer. The discrete decision to emit a symbol at every time step makes it difficult to learn with conventional backpropagation. It is however possible to train the transducer by using a dynamic programming algorithm to generate target discrete decisions. Our experiments show that the Neural Transducer works well in settings where it is required to produce output predictions as data come in. We also find that the Neural Transducer performs well for long sequences even when attention mechanisms are not used.
Neural Programmer: Inducing Latent Programs with Gradient Descent
Aug 04, 2016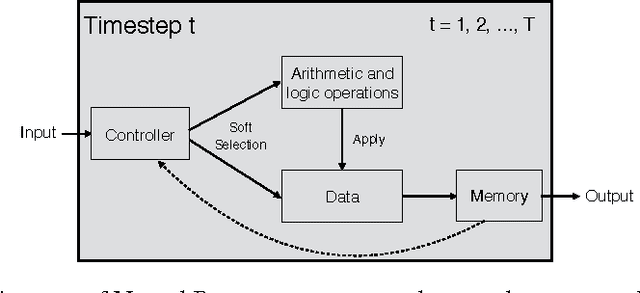

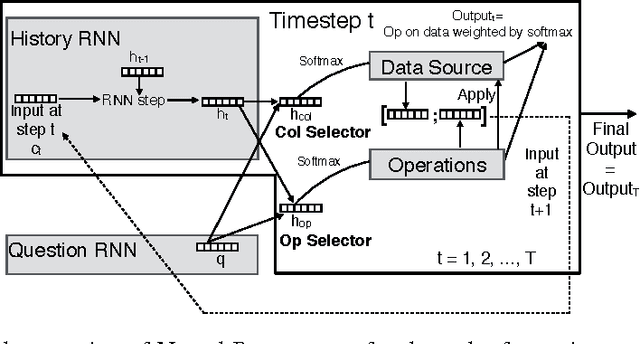
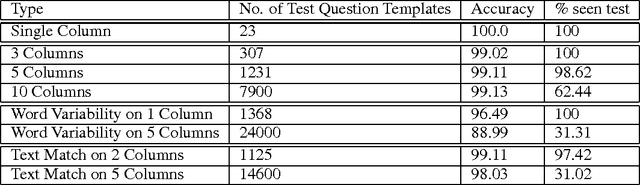
Deep neural networks have achieved impressive supervised classification performance in many tasks including image recognition, speech recognition, and sequence to sequence learning. However, this success has not been translated to applications like question answering that may involve complex arithmetic and logic reasoning. A major limitation of these models is in their inability to learn even simple arithmetic and logic operations. For example, it has been shown that neural networks fail to learn to add two binary numbers reliably. In this work, we propose Neural Programmer, an end-to-end differentiable neural network augmented with a small set of basic arithmetic and logic operations. Neural Programmer can call these augmented operations over several steps, thereby inducing compositional programs that are more complex than the built-in operations. The model learns from a weak supervision signal which is the result of execution of the correct program, hence it does not require expensive annotation of the correct program itself. The decisions of what operations to call, and what data segments to apply to are inferred by Neural Programmer. Such decisions, during training, are done in a differentiable fashion so that the entire network can be trained jointly by gradient descent. We find that training the model is difficult, but it can be greatly improved by adding random noise to the gradient. On a fairly complex synthetic table-comprehension dataset, traditional recurrent networks and attentional models perform poorly while Neural Programmer typically obtains nearly perfect accuracy.
Learning Online Alignments with Continuous Rewards Policy Gradient
Aug 03, 2016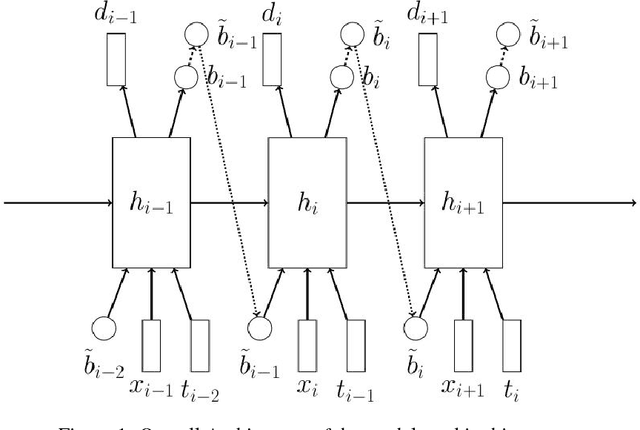



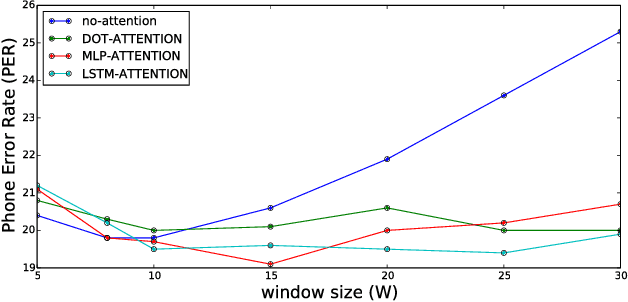
Sequence-to-sequence models with soft attention had significant success in machine translation, speech recognition, and question answering. Though capable and easy to use, they require that the entirety of the input sequence is available at the beginning of inference, an assumption that is not valid for instantaneous translation and speech recognition. To address this problem, we present a new method for solving sequence-to-sequence problems using hard online alignments instead of soft offline alignments. The online alignments model is able to start producing outputs without the need to first process the entire input sequence. A highly accurate online sequence-to-sequence model is useful because it can be used to build an accurate voice-based instantaneous translator. Our model uses hard binary stochastic decisions to select the timesteps at which outputs will be produced. The model is trained to produce these stochastic decisions using a standard policy gradient method. In our experiments, we show that this model achieves encouraging performance on TIMIT and Wall Street Journal (WSJ) speech recognition datasets.
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
Jun 12, 2016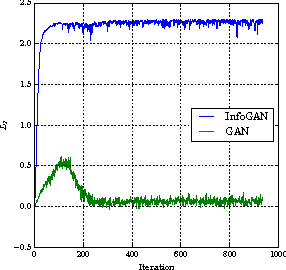



This paper describes InfoGAN, an information-theoretic extension to the Generative Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner. InfoGAN is a generative adversarial network that also maximizes the mutual information between a small subset of the latent variables and the observation. We derive a lower bound to the mutual information objective that can be optimized efficiently, and show that our training procedure can be interpreted as a variation of the Wake-Sleep algorithm. Specifically, InfoGAN successfully disentangles writing styles from digit shapes on the MNIST dataset, pose from lighting of 3D rendered images, and background digits from the central digit on the SVHN dataset. It also discovers visual concepts that include hair styles, presence/absence of eyeglasses, and emotions on the CelebA face dataset. Experiments show that InfoGAN learns interpretable representations that are competitive with representations learned by existing fully supervised methods.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016

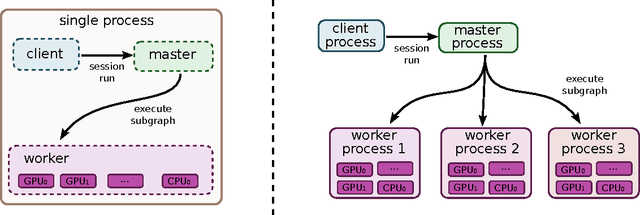
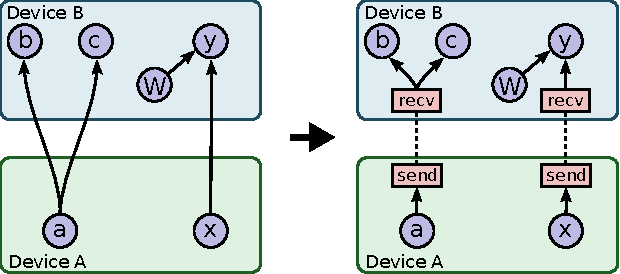
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Neural GPUs Learn Algorithms
Mar 15, 2016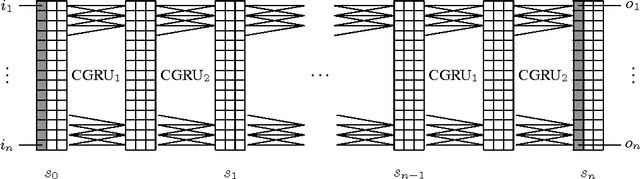
Learning an algorithm from examples is a fundamental problem that has been widely studied. Recently it has been addressed using neural networks, in particular by Neural Turing Machines (NTMs). These are fully differentiable computers that use backpropagation to learn their own programming. Despite their appeal NTMs have a weakness that is caused by their sequential nature: they are not parallel and are are hard to train due to their large depth when unfolded. We present a neural network architecture to address this problem: the Neural GPU. It is based on a type of convolutional gated recurrent unit and, like the NTM, is computationally universal. Unlike the NTM, the Neural GPU is highly parallel which makes it easier to train and efficient to run. An essential property of algorithms is their ability to handle inputs of arbitrary size. We show that the Neural GPU can be trained on short instances of an algorithmic task and successfully generalize to long instances. We verified it on a number of tasks including long addition and long multiplication of numbers represented in binary. We train the Neural GPU on numbers with upto 20 bits and observe no errors whatsoever while testing it, even on much longer numbers. To achieve these results we introduce a technique for training deep recurrent networks: parameter sharing relaxation. We also found a small amount of dropout and gradient noise to have a large positive effect on learning and generalization.
Continuous Deep Q-Learning with Model-based Acceleration
Mar 02, 2016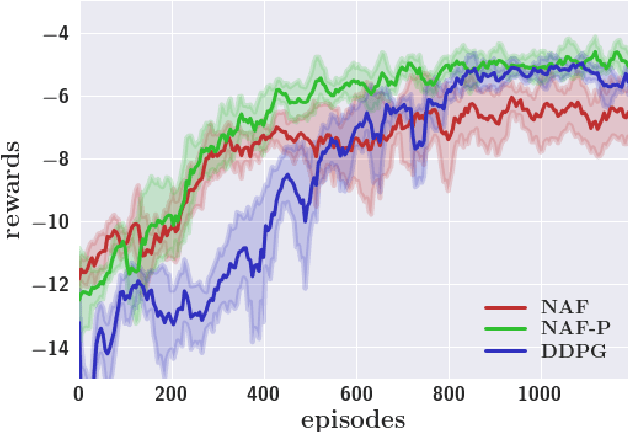
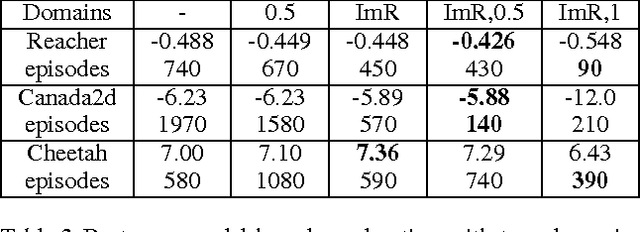
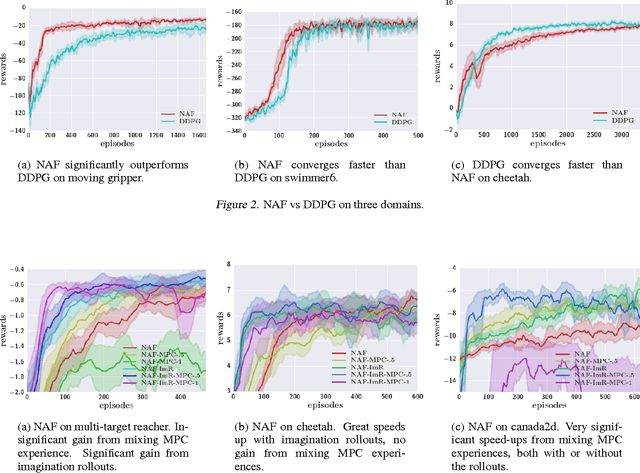
Model-free reinforcement learning has been successfully applied to a range of challenging problems, and has recently been extended to handle large neural network policies and value functions. However, the sample complexity of model-free algorithms, particularly when using high-dimensional function approximators, tends to limit their applicability to physical systems. In this paper, we explore algorithms and representations to reduce the sample complexity of deep reinforcement learning for continuous control tasks. We propose two complementary techniques for improving the efficiency of such algorithms. First, we derive a continuous variant of the Q-learning algorithm, which we call normalized adantage functions (NAF), as an alternative to the more commonly used policy gradient and actor-critic methods. NAF representation allows us to apply Q-learning with experience replay to continuous tasks, and substantially improves performance on a set of simulated robotic control tasks. To further improve the efficiency of our approach, we explore the use of learned models for accelerating model-free reinforcement learning. We show that iteratively refitted local linear models are especially effective for this, and demonstrate substantially faster learning on domains where such models are applicable.