 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Tree-Search, Generative Models, and Nash Bargaining Concepts in Game-Theoretic Reinforcement Learning
Feb 01, 2023



Multiagent reinforcement learning (MARL) has benefited significantly from population-based and game-theoretic training regimes. One approach, Policy-Space Response Oracles (PSRO), employs standard reinforcement learning to compute response policies via approximate best responses and combines them via meta-strategy selection. We augment PSRO by adding a novel search procedure with generative sampling of world states, and introduce two new meta-strategy solvers based on the Nash bargaining solution. We evaluate PSRO's ability to compute approximate Nash equilibrium, and its performance in two negotiation games: Colored Trails, and Deal or No Deal. We conduct behavioral studies where human participants negotiate with our agents ($N = 346$). We find that search with generative modeling finds stronger policies during both training time and test time, enables online Bayesian co-player prediction, and can produce agents that achieve comparable social welfare negotiating with humans as humans trading among themselves.
AlphaSnake: Policy Iteration on a Nondeterministic NP-hard Markov Decision Process
Nov 17, 2022Reinforcement learning has recently been used to approach well-known NP-hard combinatorial problems in graph theory. Among these problems, Hamiltonian cycle problems are exceptionally difficult to analyze, even when restricted to individual instances of structurally complex graphs. In this paper, we use Monte Carlo Tree Search (MCTS), the search algorithm behind many state-of-the-art reinforcement learning algorithms such as AlphaZero, to create autonomous agents that learn to play the game of Snake, a game centered on properties of Hamiltonian cycles on grid graphs. The game of Snake can be formulated as a single-player discounted Markov Decision Process (MDP) where the agent must behave optimally in a stochastic environment. Determining the optimal policy for Snake, defined as the policy that maximizes the probability of winning - or win rate - with higher priority and minimizes the expected number of time steps to win with lower priority, is conjectured to be NP-hard. Performance-wise, compared to prior work in the Snake game, our algorithm is the first to achieve a win rate over $0.5$ (a uniform random policy achieves a win rate $< 2.57 \times 10^{-15}$), demonstrating the versatility of AlphaZero in approaching NP-hard environments.
Turbocharging Solution Concepts: Solving NEs, CEs and CCEs with Neural Equilibrium Solvers
Oct 17, 2022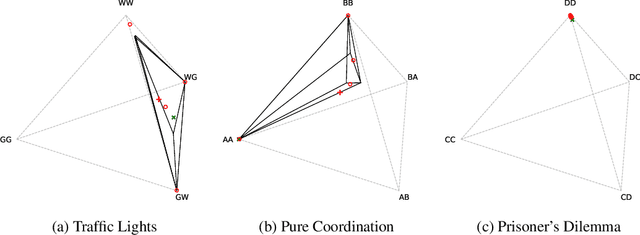
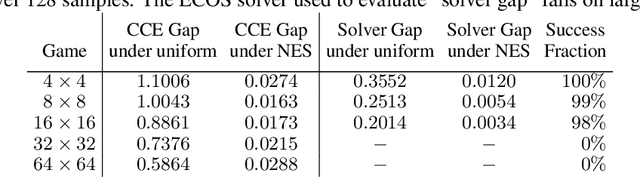

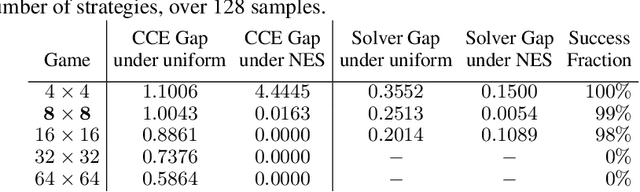
Solution concepts such as Nash Equilibria, Correlated Equilibria, and Coarse Correlated Equilibria are useful components for many multiagent machine learning algorithms. Unfortunately, solving a normal-form game could take prohibitive or non-deterministic time to converge, and could fail. We introduce the Neural Equilibrium Solver which utilizes a special equivariant neural network architecture to approximately solve the space of all games of fixed shape, buying speed and determinism. We define a flexible equilibrium selection framework, that is capable of uniquely selecting an equilibrium that minimizes relative entropy, or maximizes welfare. The network is trained without needing to generate any supervised training data. We show remarkable zero-shot generalization to larger games. We argue that such a network is a powerful component for many possible multiagent algorithms.
Game Theoretic Rating in N-player general-sum games with Equilibria
Oct 05, 2022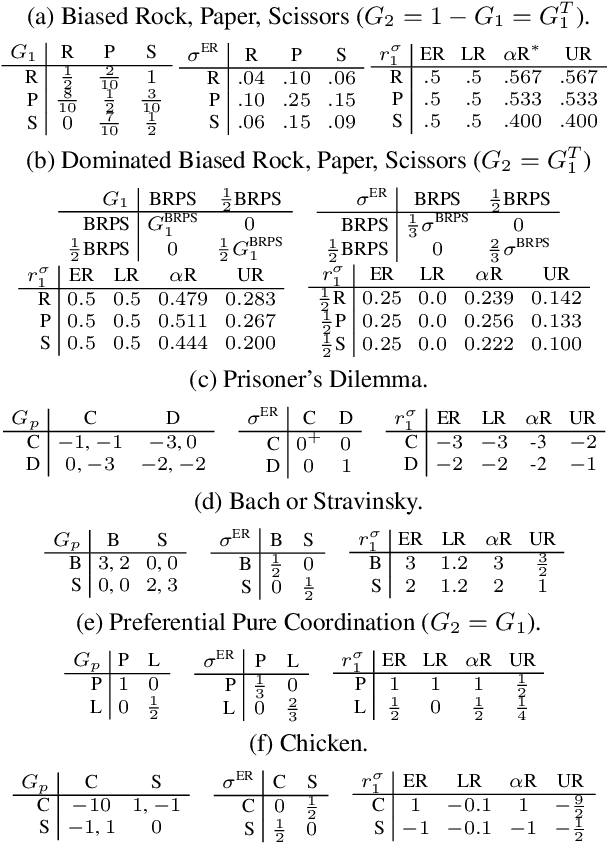
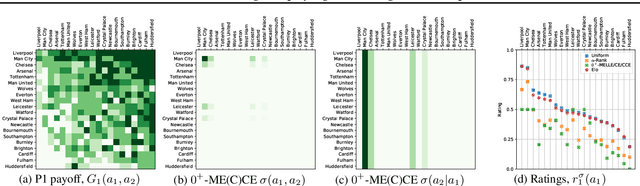
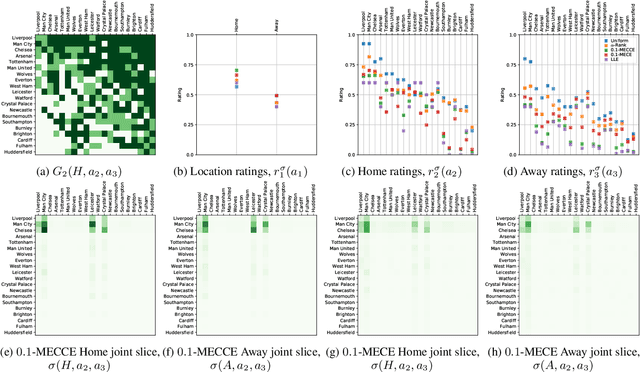
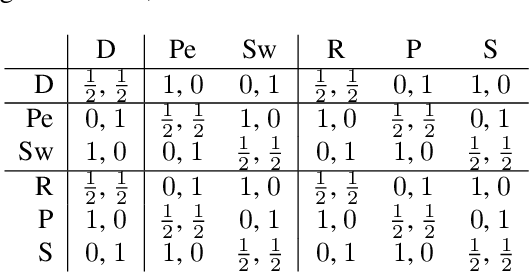
Rating strategies in a game is an important area of research in game theory and artificial intelligence, and can be applied to any real-world competitive or cooperative setting. Traditionally, only transitive dependencies between strategies have been used to rate strategies (e.g. Elo), however recent work has expanded ratings to utilize game theoretic solutions to better rate strategies in non-transitive games. This work generalizes these ideas and proposes novel algorithms suitable for N-player, general-sum rating of strategies in normal-form games according to the payoff rating system. This enables well-established solution concepts, such as equilibria, to be leveraged to efficiently rate strategies in games with complex strategic interactions, which arise in multiagent training and real-world interactions between many agents. We empirically validate our methods on real world normal-form data (Premier League) and multiagent reinforcement learning agent evaluation.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Stochastic Parallelizable Eigengap Dilation for Large Graph Clustering
Jul 29, 2022

Large graphs commonly appear in social networks, knowledge graphs, recommender systems, life sciences, and decision making problems. Summarizing large graphs by their high level properties is helpful in solving problems in these settings. In spectral clustering, we aim to identify clusters of nodes where most edges fall within clusters and only few edges fall between clusters. This task is important for many downstream applications and exploratory analysis. A core step of spectral clustering is performing an eigendecomposition of the corresponding graph Laplacian matrix (or equivalently, a singular value decomposition, SVD, of the incidence matrix). The convergence of iterative singular value decomposition approaches depends on the eigengaps of the spectrum of the given matrix, i.e., the difference between consecutive eigenvalues. For a graph Laplacian corresponding to a well-clustered graph, the eigenvalues will be non-negative but very small (much less than $1$) slowing convergence. This paper introduces a parallelizable approach to dilating the spectrum in order to accelerate SVD solvers and in turn, spectral clustering. This is accomplished via polynomial approximations to matrix operations that favorably transform the spectrum of a matrix without changing its eigenvectors. Experiments demonstrate that this approach significantly accelerates convergence, and we explain how this transformation can be parallelized and stochastically approximated to scale with available compute.
The Generalized Eigenvalue Problem as a Nash Equilibrium
Jun 10, 2022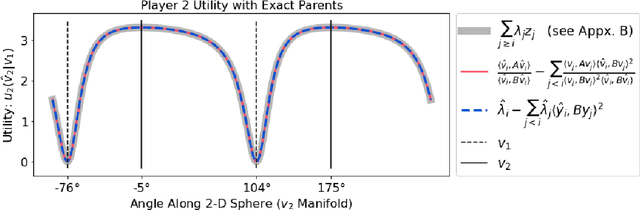
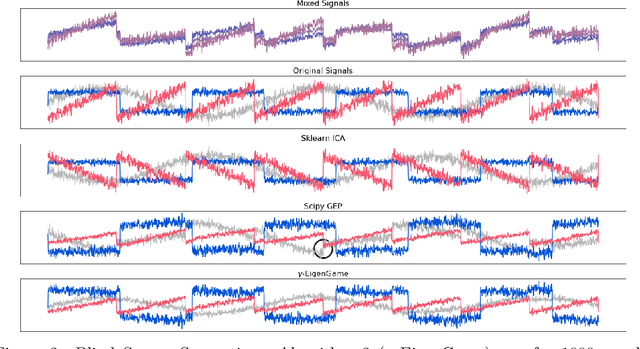
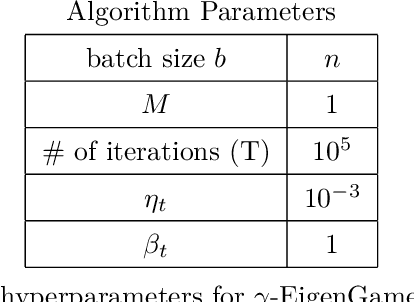
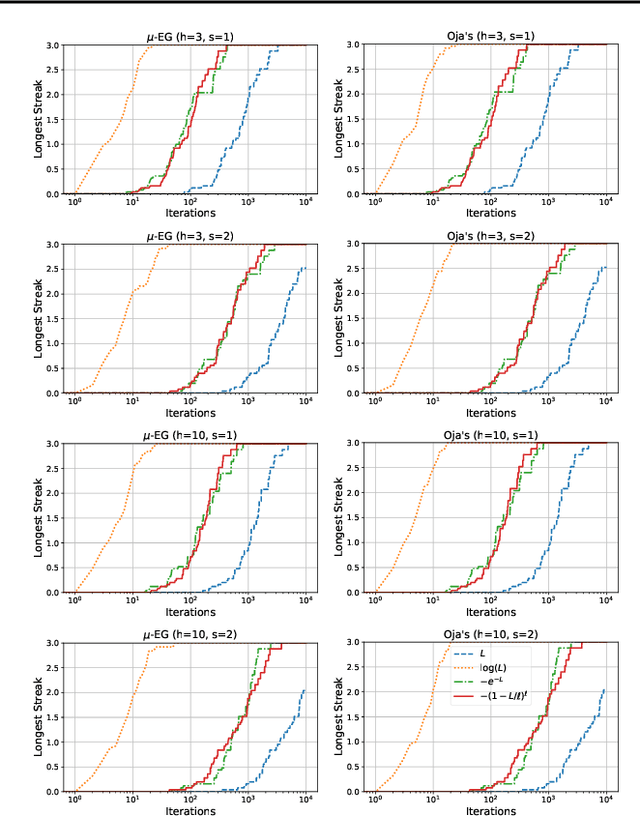
The generalized eigenvalue problem (GEP) is a fundamental concept in numerical linear algebra. It captures the solution of many classical machine learning problems such as canonical correlation analysis, independent components analysis, partial least squares, linear discriminant analysis, principal components, successor features and others. Despite this, most general solvers are prohibitively expensive when dealing with massive data sets and research has instead concentrated on finding efficient solutions to specific problem instances. In this work, we develop a game-theoretic formulation of the top-$k$ GEP whose Nash equilibrium is the set of generalized eigenvectors. We also present a parallelizable algorithm with guaranteed asymptotic convergence to the Nash. Current state-of-the-art methods require $\mathcal{O}(d^2k)$ complexity per iteration which is prohibitively expensive when the number of dimensions ($d$) is large. We show how to achieve $\mathcal{O}(dk)$ complexity, scaling to datasets $100\times$ larger than those evaluated by prior methods. Empirically we demonstrate that our algorithm is able to solve a variety of GEP problem instances including a large-scale analysis of neural network activations.
EigenGame Unloaded: When playing games is better than optimizing
Feb 08, 2021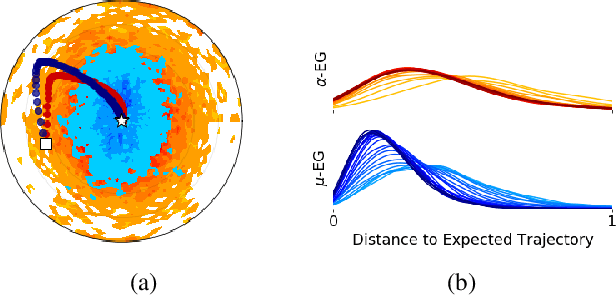
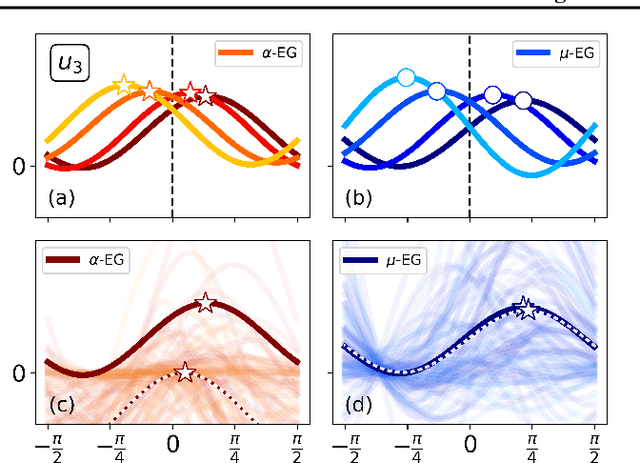
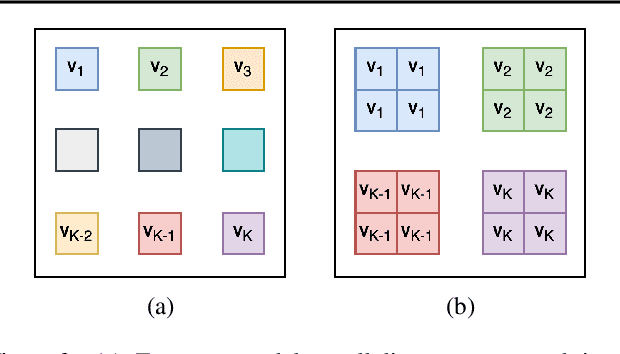
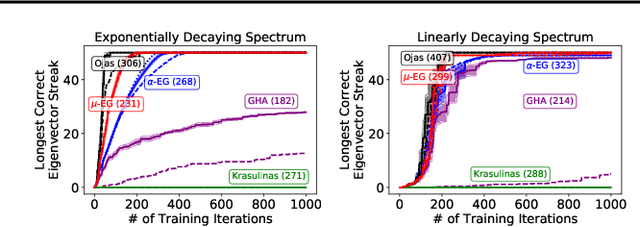
We build on the recently proposed EigenGame that views eigendecomposition as a competitive game. EigenGame's updates are biased if computed using minibatches of data, which hinders convergence and more sophisticated parallelism in the stochastic setting. In this work, we propose an unbiased stochastic update that is asymptotically equivalent to EigenGame, enjoys greater parallelism allowing computation on datasets of larger sample sizes, and outperforms EigenGame in experiments. We present applications to finding the principal components of massive datasets and performing spectral clustering of graphs. We analyze and discuss our proposed update in the context of EigenGame and the shift in perspective from optimization to games.
EigenGame: PCA as a Nash Equilibrium
Oct 01, 2020
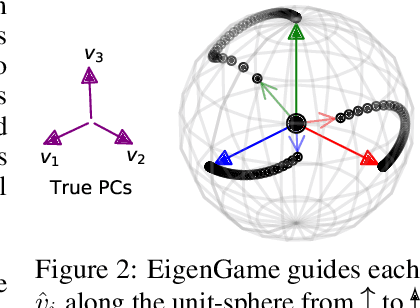
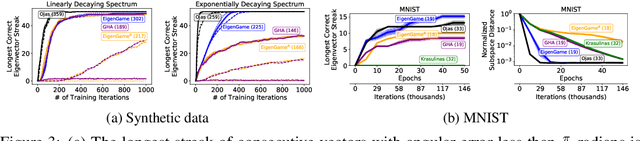
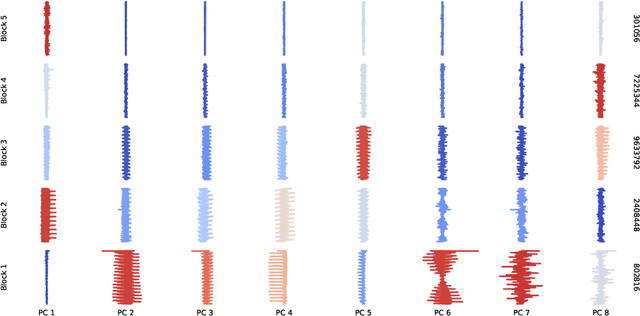
We present a novel view on principal component analysis (PCA) as a competitive game in which each approximate eigenvector is controlled by a player whose goal is to maximize their own utility function. We analyze the properties of this PCA game and the behavior of its gradient based updates. The resulting algorithm which combines elements from Oja's rule with a generalized Gram-Schmidt orthogonalization is naturally decentralized and hence parallelizable through message passing. We demonstrate the scalability of the algorithm with experiments on large image datasets and neural network activations. We discuss how this new view of PCA as a differentiable game can lead to further algorithmic developments and insights.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020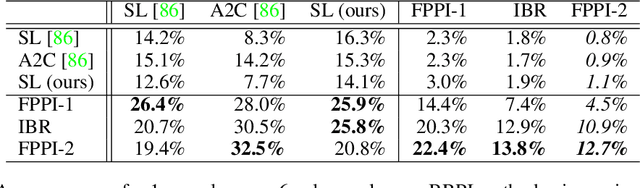
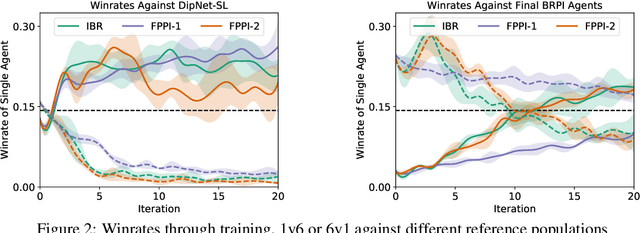
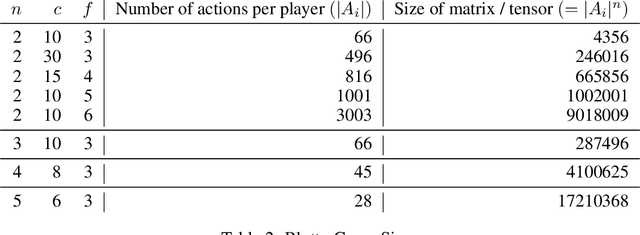
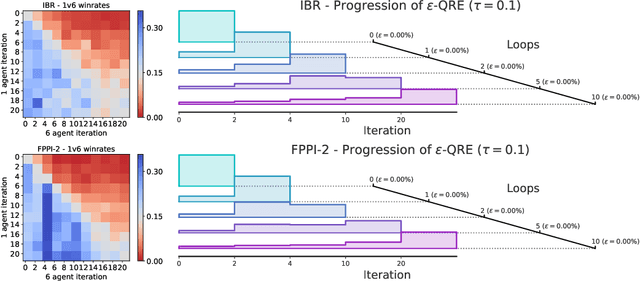
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.