 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
Explaining Competitive-Level Programming Solutions using LLMs
Jul 11, 2023



In this paper, we approach competitive-level programming problem-solving as a composite task of reasoning and code generation. We propose a novel method to automatically annotate natural language explanations to \textit{<problem, solution>} pairs. We show that despite poor performance in solving competitive-level programming problems, state-of-the-art LLMs exhibit a strong capacity in describing and explaining solutions. Our explanation generation methodology can generate a structured solution explanation for the problem containing descriptions and analysis. To evaluate the quality of the annotated explanations, we examine their effectiveness in two aspects: 1) satisfying the human programming expert who authored the oracle solution, and 2) aiding LLMs in solving problems more effectively. The experimental results on the CodeContests dataset demonstrate that while LLM GPT3.5's and GPT-4's abilities in describing the solution are comparable, GPT-4 shows a better understanding of the key idea behind the solution.
AlphaSnake: Policy Iteration on a Nondeterministic NP-hard Markov Decision Process
Nov 17, 2022
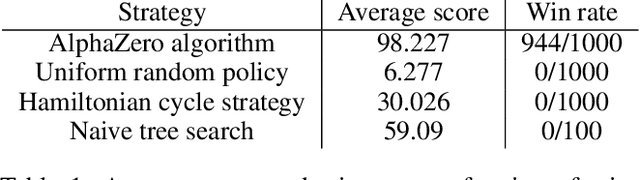
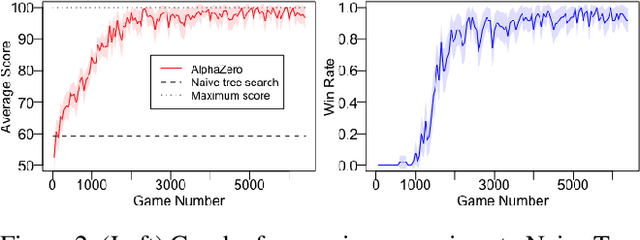

Reinforcement learning has recently been used to approach well-known NP-hard combinatorial problems in graph theory. Among these problems, Hamiltonian cycle problems are exceptionally difficult to analyze, even when restricted to individual instances of structurally complex graphs. In this paper, we use Monte Carlo Tree Search (MCTS), the search algorithm behind many state-of-the-art reinforcement learning algorithms such as AlphaZero, to create autonomous agents that learn to play the game of Snake, a game centered on properties of Hamiltonian cycles on grid graphs. The game of Snake can be formulated as a single-player discounted Markov Decision Process (MDP) where the agent must behave optimally in a stochastic environment. Determining the optimal policy for Snake, defined as the policy that maximizes the probability of winning - or win rate - with higher priority and minimizes the expected number of time steps to win with lower priority, is conjectured to be NP-hard. Performance-wise, compared to prior work in the Snake game, our algorithm is the first to achieve a win rate over $0.5$ (a uniform random policy achieves a win rate $< 2.57 \times 10^{-15}$), demonstrating the versatility of AlphaZero in approaching NP-hard environments.
PhyloTransformer: A Discriminative Model for Mutation Prediction Based on a Multi-head Self-attention Mechanism
Nov 03, 2021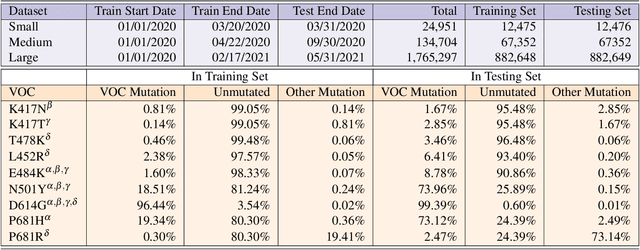
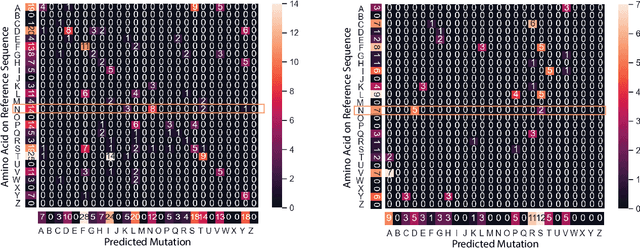
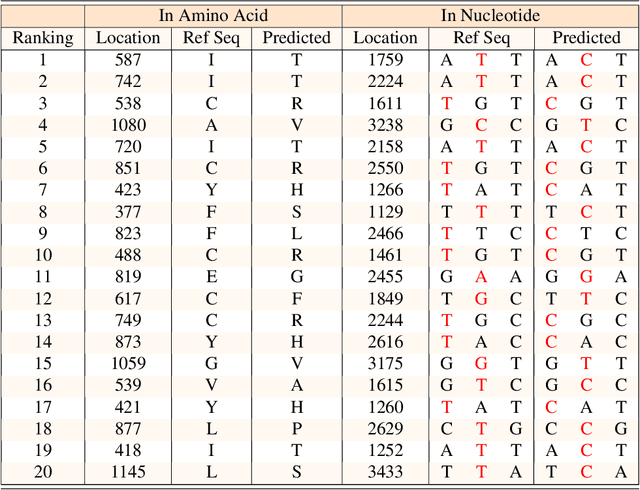
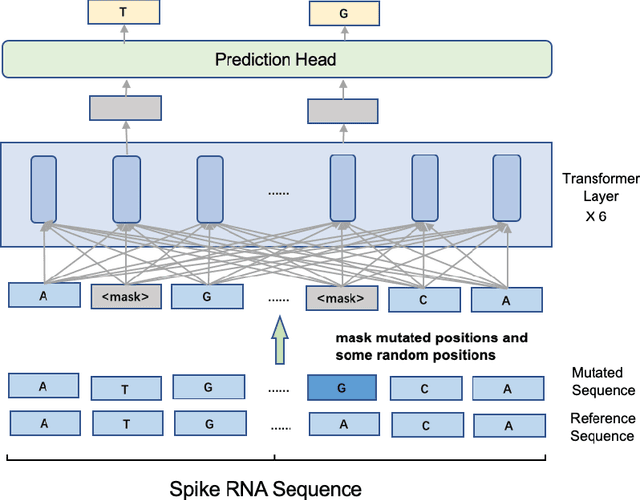
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has caused an ongoing pandemic infecting 219 million people as of 10/19/21, with a 3.6% mortality rate. Natural selection can generate favorable mutations with improved fitness advantages; however, the identified coronaviruses may be the tip of the iceberg, and potentially more fatal variants of concern (VOCs) may emerge over time. Understanding the patterns of emerging VOCs and forecasting mutations that may lead to gain of function or immune escape is urgently required. Here we developed PhyloTransformer, a Transformer-based discriminative model that engages a multi-head self-attention mechanism to model genetic mutations that may lead to viral reproductive advantage. In order to identify complex dependencies between the elements of each input sequence, PhyloTransformer utilizes advanced modeling techniques, including a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+) from Performer, and the Masked Language Model (MLM) from Bidirectional Encoder Representations from Transformers (BERT). PhyloTransformer was trained with 1,765,297 genetic sequences retrieved from the Global Initiative for Sharing All Influenza Data (GISAID) database. Firstly, we compared the prediction accuracy of novel mutations and novel combinations using extensive baseline models; we found that PhyloTransformer outperformed every baseline method with statistical significance. Secondly, we examined predictions of mutations in each nucleotide of the receptor binding motif (RBM), and we found our predictions were precise and accurate. Thirdly, we predicted modifications of N-glycosylation sites to identify mutations associated with altered glycosylation that may be favored during viral evolution. We anticipate that PhyloTransformer may guide proactive vaccine design for effective targeting of future SARS-CoV-2 variants.
Cuid: A new study of perceived image quality and its subjective assessment
Sep 28, 2020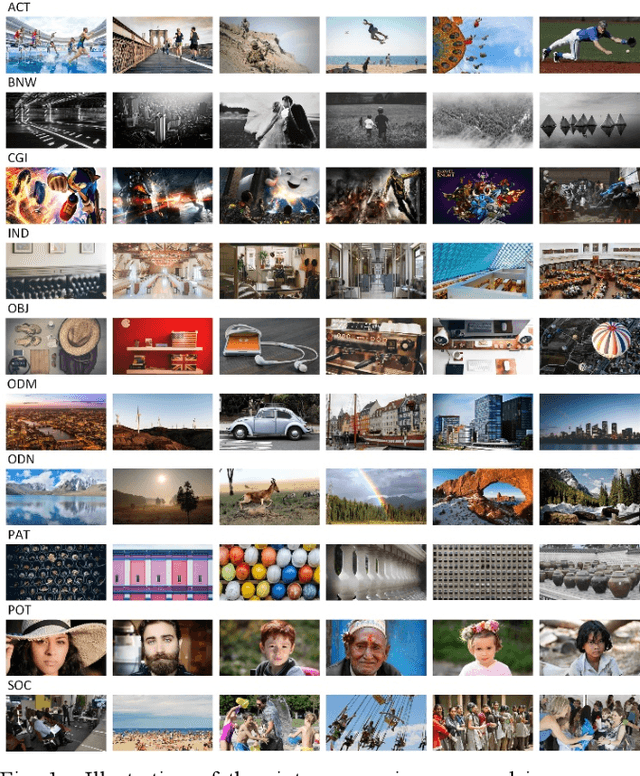


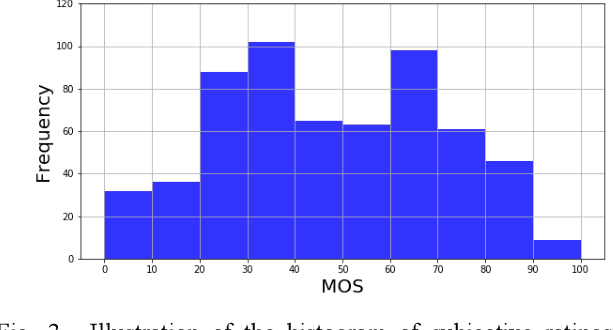
Research on image quality assessment (IQA) remains limited mainly due to our incomplete knowledge about human visual perception. Existing IQA algorithms have been designed or trained with insufficient subjective data with a small degree of stimulus variability. This has led to challenges for those algorithms to handle complexity and diversity of real-world digital content. Perceptual evidence from human subjects serves as a grounding for the development of advanced IQA algorithms. It is thus critical to acquire reliable subjective data with controlled perception experiments that faithfully reflect human behavioural responses to distortions in visual signals. In this paper, we present a new study of image quality perception where subjective ratings were collected in a controlled lab environment. We investigate how quality perception is affected by a combination of different categories of images and different types and levels of distortions. The database will be made publicly available to facilitate calibration and validation of IQA algorithms.