 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Preference Coding: Aligning Large Language Models via Discrete Latent Codes
May 08, 2025Large language models (LLMs) have achieved remarkable success, yet aligning their generations with human preferences remains a critical challenge. Existing approaches to preference modeling often rely on an explicit or implicit reward function, overlooking the intricate and multifaceted nature of human preferences that may encompass conflicting factors across diverse tasks and populations. To address this limitation, we introduce Latent Preference Coding (LPC), a novel framework that models the implicit factors as well as their combinations behind holistic preferences using discrete latent codes. LPC seamlessly integrates with various offline alignment algorithms, automatically inferring the underlying factors and their importance from data without relying on pre-defined reward functions and hand-crafted combination weights. Extensive experiments on multiple benchmarks demonstrate that LPC consistently improves upon three alignment algorithms (DPO, SimPO, and IPO) using three base models (Mistral-7B, Llama3-8B, and Llama3-8B-Instruct). Furthermore, deeper analysis reveals that the learned latent codes effectively capture the differences in the distribution of human preferences and significantly enhance the robustness of alignment against noise in data. By providing a unified representation for the multifarious preference factors, LPC paves the way towards developing more robust and versatile alignment techniques for the responsible deployment of powerful LLMs.
VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
Nov 27, 2024



Recent researches on video large language models (VideoLLM) predominantly focus on model architectures and training datasets, leaving the interaction format between the user and the model under-explored. In existing works, users often interact with VideoLLMs by using the entire video and a query as input, after which the model generates a response. This interaction format constrains the application of VideoLLMs in scenarios such as live-streaming comprehension where videos do not end and responses are required in a real-time manner, and also results in unsatisfactory performance on time-sensitive tasks that requires localizing video segments. In this paper, we focus on a video-text duet interaction format. This interaction format is characterized by the continuous playback of the video, and both the user and the model can insert their text messages at any position during the video playback. When a text message ends, the video continues to play, akin to the alternative of two performers in a duet. We construct MMDuetIT, a video-text training dataset designed to adapt VideoLLMs to video-text duet interaction format. We also introduce the Multi-Answer Grounded Video Question Answering (MAGQA) task to benchmark the real-time response ability of VideoLLMs. Trained on MMDuetIT, MMDuet demonstrates that adopting the video-text duet interaction format enables the model to achieve significant improvements in various time-sensitive tasks (76% CIDEr on YouCook2 dense video captioning, 90\% mAP on QVHighlights highlight detection and 25% R@0.5 on Charades-STA temporal video grounding) with minimal training efforts, and also enable VideoLLMs to reply in a real-time manner as the video plays. Code, data and demo are available at: https://github.com/yellow-binary-tree/MMDuet.
AIDBench: A benchmark for evaluating the authorship identification capability of large language models
Nov 20, 2024



As large language models (LLMs) rapidly advance and integrate into daily life, the privacy risks they pose are attracting increasing attention. We focus on a specific privacy risk where LLMs may help identify the authorship of anonymous texts, which challenges the effectiveness of anonymity in real-world systems such as anonymous peer review systems. To investigate these risks, we present AIDBench, a new benchmark that incorporates several author identification datasets, including emails, blogs, reviews, articles, and research papers. AIDBench utilizes two evaluation methods: one-to-one authorship identification, which determines whether two texts are from the same author; and one-to-many authorship identification, which, given a query text and a list of candidate texts, identifies the candidate most likely written by the same author as the query text. We also introduce a Retrieval-Augmented Generation (RAG)-based method to enhance the large-scale authorship identification capabilities of LLMs, particularly when input lengths exceed the models' context windows, thereby establishing a new baseline for authorship identification using LLMs. Our experiments with AIDBench demonstrate that LLMs can correctly guess authorship at rates well above random chance, revealing new privacy risks posed by these powerful models. The source code and data will be made publicly available after acceptance.
Understanding Multimodal Hallucination with Parameter-Free Representation Alignment
Sep 02, 2024



Hallucination is a common issue in Multimodal Large Language Models (MLLMs), yet the underlying principles remain poorly understood. In this paper, we investigate which components of MLLMs contribute to object hallucinations. To analyze image representations while completely avoiding the influence of all other factors other than the image representation itself, we propose a parametric-free representation alignment metric (Pfram) that can measure the similarities between any two representation systems without requiring additional training parameters. Notably, Pfram can also assess the alignment of a neural representation system with the human representation system, represented by ground-truth annotations of images. By evaluating the alignment with object annotations, we demonstrate that this metric shows strong and consistent correlations with object hallucination across a wide range of state-of-the-art MLLMs, spanning various model architectures and sizes. Furthermore, using this metric, we explore other key issues related to image representations in MLLMs, such as the role of different modules, the impact of textual instructions, and potential improvements including the use of alternative visual encoders. Our code is available at: https://github.com/yellow-binary-tree/Pfram.
ReMamba: Equip Mamba with Effective Long-Sequence Modeling
Sep 01, 2024



While the Mamba architecture demonstrates superior inference efficiency and competitive performance on short-context natural language processing (NLP) tasks, empirical evidence suggests its capacity to comprehend long contexts is limited compared to transformer-based models. In this study, we investigate the long-context efficiency issues of the Mamba models and propose ReMamba, which enhances Mamba's ability to comprehend long contexts. ReMamba incorporates selective compression and adaptation techniques within a two-stage re-forward process, incurring minimal additional inference costs overhead. Experimental results on the LongBench and L-Eval benchmarks demonstrate ReMamba's efficacy, improving over the baselines by 3.2 and 1.6 points, respectively, and attaining performance almost on par with same-size transformer models.
Evidence-Enhanced Triplet Generation Framework for Hallucination Alleviation in Generative Question Answering
Aug 27, 2024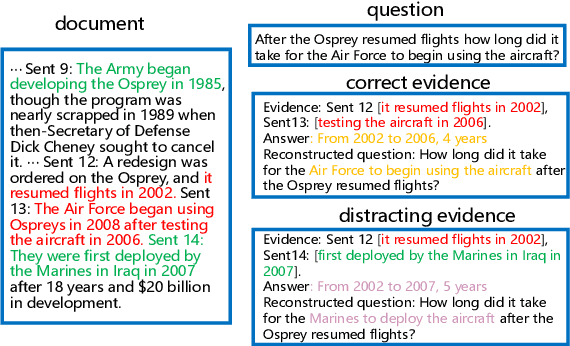
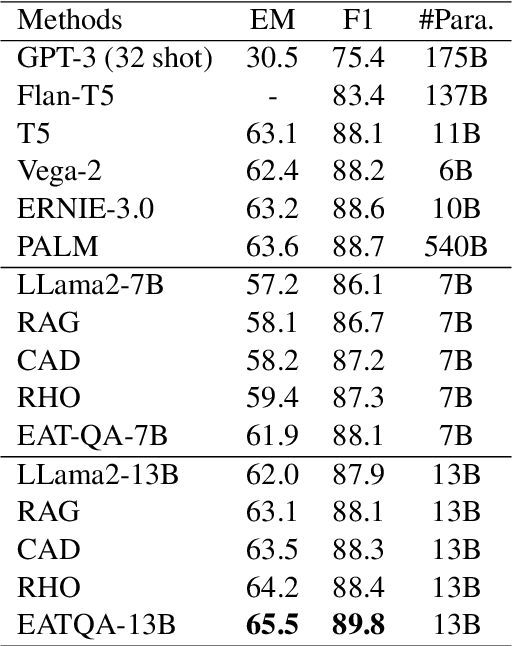
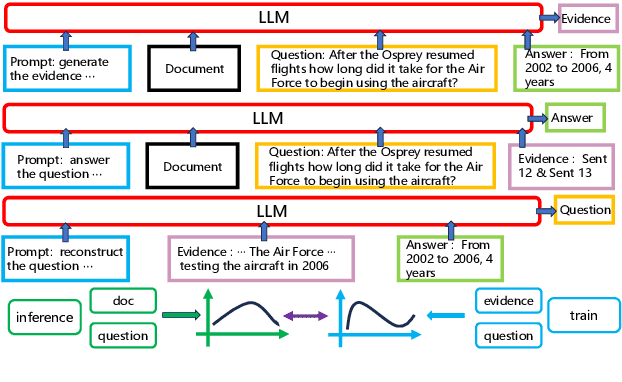
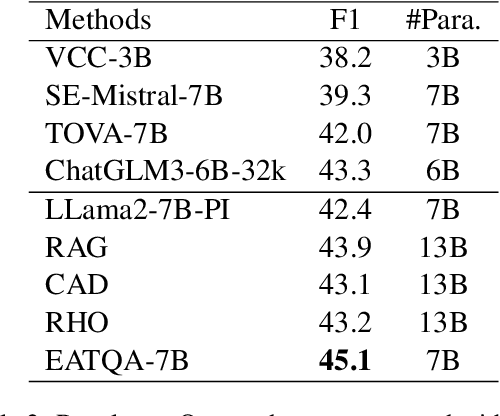
To address the hallucination in generative question answering (GQA) where the answer can not be derived from the document, we propose a novel evidence-enhanced triplet generation framework, EATQA, encouraging the model to predict all the combinations of (Question, Evidence, Answer) triplet by flipping the source pair and the target label to understand their logical relationships, i.e., predict Answer(A), Question(Q), and Evidence(E) given a QE, EA, and QA pairs, respectively. Furthermore, we bridge the distribution gap to distill the knowledge from evidence in inference stage. Our framework ensures the model to learn the logical relation between query, evidence and answer, which simultaneously improves the evidence generation and query answering. In this paper, we apply EATQA to LLama and it outperforms other LLMs-based methods and hallucination mitigation approaches on two challenging GQA benchmarks. Further analysis shows that our method not only keeps prior knowledge within LLM, but also mitigates hallucination and generates faithful answers.
Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Jul 09, 2024



Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.
Efficient Continual Pre-training by Mitigating the Stability Gap
Jun 21, 2024



Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the "stability gap," previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at \url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
Automatic Jailbreaking of the Text-to-Image Generative AI Systems
May 28, 2024



Recent AI systems have shown extremely powerful performance, even surpassing human performance, on various tasks such as information retrieval, language generation, and image generation based on large language models (LLMs). At the same time, there are diverse safety risks that can cause the generation of malicious contents by circumventing the alignment in LLMs, which are often referred to as jailbreaking. However, most of the previous works only focused on the text-based jailbreaking in LLMs, and the jailbreaking of the text-to-image (T2I) generation system has been relatively overlooked. In this paper, we first evaluate the safety of the commercial T2I generation systems, such as ChatGPT, Copilot, and Gemini, on copyright infringement with naive prompts. From this empirical study, we find that Copilot and Gemini block only 12% and 17% of the attacks with naive prompts, respectively, while ChatGPT blocks 84% of them. Then, we further propose a stronger automated jailbreaking pipeline for T2I generation systems, which produces prompts that bypass their safety guards. Our automated jailbreaking framework leverages an LLM optimizer to generate prompts to maximize degree of violation from the generated images without any weight updates or gradient computation. Surprisingly, our simple yet effective approach successfully jailbreaks the ChatGPT with 11.0% block rate, making it generate copyrighted contents in 76% of the time. Finally, we explore various defense strategies, such as post-generation filtering and machine unlearning techniques, but found that they were inadequate, which suggests the necessity of stronger defense mechanisms.
xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
May 22, 2024



This paper introduces xRAG, an innovative context compression method tailored for retrieval-augmented generation. xRAG reinterprets document embeddings in dense retrieval--traditionally used solely for retrieval--as features from the retrieval modality. By employing a modality fusion methodology, xRAG seamlessly integrates these embeddings into the language model representation space, effectively eliminating the need for their textual counterparts and achieving an extreme compression rate. In xRAG, the only trainable component is the modality bridge, while both the retriever and the language model remain frozen. This design choice allows for the reuse of offline-constructed document embeddings and preserves the plug-and-play nature of retrieval augmentation. Experimental results demonstrate that xRAG achieves an average improvement of over 10% across six knowledge-intensive tasks, adaptable to various language model backbones, ranging from a dense 7B model to an 8x7B Mixture of Experts configuration. xRAG not only significantly outperforms previous context compression methods but also matches the performance of uncompressed models on several datasets, while reducing overall FLOPs by a factor of 3.53. Our work pioneers new directions in retrieval-augmented generation from the perspective of multimodality fusion, and we hope it lays the foundation for future efficient and scalable retrieval-augmented systems