 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawVideo: Generating Long Video from Storyboard Keyframe Sketches
May 22, 2026Long video generation requires high-fidelity synthesis, coherent narrative structure, and user control over extended time spans. Existing text-to-video methods often rely on a single long prompt, limiting control over pose, composition, layout, and motion. We propose DrawVideo, a sketch-guided, storyboard-driven framework for controllable long-video generation. DrawVideo decomposes long videos into independently controllable shots, each defined by a black-and-white sketch, an appearance prompt, and a motion prompt. The sketch controls pose and layout, the appearance prompt defines identity, scene, and style, and the motion prompt guides temporal dynamics. DrawVideo follows a hierarchical 'global multi-shot, local single-sketch' strategy: it first generates a structure-aligned reference keyframe, then expands the motion prompt into derivative keyframes representing action states, and finally synthesizes clips between adjacent keyframes to build each shot. We also introduce SketchLongVideo, the first dataset for sketch-guided text-to-long-video generation, constructed from animation videos via shot detection, keyframe extraction, vision-language recognition, prompt decomposition, and sketch conversion. Experiments show that DrawVideo achieves strong structural controllability, appearance consistency, visual stability, and coherent long-video generation.
Tail-Aware Information-Theoretic Generalization for RLHF and SGLD
Apr 12, 2026Classical information-theoretic generalization bounds typically control the generalization gap through KL-based mutual information and therefore rely on boundedness or sub-Gaussian tails via the moment generating function (MGF). In many modern pipelines, such as robust learning, RLHF, and stochastic optimization, losses and rewards can be heavy-tailed, and MGFs may not exist, rendering KL-based tools ineffective. We develop a tail-dependent information-theoretic framework for sub-Weibull data, where the tail parameter $θ$ controls the tail heaviness: $θ=2$ corresponds to sub-Gaussian, $θ=1$ to sub-exponential, and $0<θ<1$ to genuinely heavy tails. Our key technical ingredient is a decorrelation lemma that bounds change-of-measure expectations using a shifted-log $f_θ$-divergence, which admits explicit comparisons to Rényi divergence without MGF arguments. On the empirical-process side, we establish sharp maximal inequalities and a Dudley-type chaining bound for sub-Weibull processes with tail index $θ$, with complexity scaling as $\log^{1/θ}$ and entropy$^{1/θ}$. These tools yield expected and high-probability PAC-Bayes generalization bounds, as well as an information-theoretic chaining inequality based on multiscale Rényi mutual information. We illustrate the consequences in Rényi-regularized RLHF under heavy-tailed rewards and in stochastic gradient Langevin dynamics with heavy-tailed gradient noise.
Sharper Generalization Bounds for Transformer
Mar 23, 2026This paper studies generalization error bounds for Transformer models. Based on the offset Rademacher complexity, we derive sharper generalization bounds for different Transformer architectures, including single-layer single-head, single-layer multi-head, and multi-layer Transformers. We first express the excess risk of Transformers in terms of the offset Rademacher complexity. By exploiting its connection with the empirical covering numbers of the corresponding hypothesis spaces, we obtain excess risk bounds that achieve optimal convergence rates up to constant factors. We then derive refined excess risk bounds by upper bounding the covering numbers of Transformer hypothesis spaces using matrix ranks and matrix norms, leading to precise, architecture-dependent generalization bounds. Finally, we relax the boundedness assumption on feature mappings and extend our theoretical results to settings with unbounded (sub-Gaussian) features and heavy-tailed distributions.
Adaptive Robust Estimator for Multi-Agent Reinforcement Learning
Mar 23, 2026Multi-agent collaboration has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models, yet it suffers from interaction-level ambiguity that blurs generation, critique, and revision, making credit assignment across agents difficult. Moreover, policy optimization in this setting is vulnerable to heavy-tailed and noisy rewards, which can bias advantage estimation and trigger unstable or even divergent training. To address both issues, we propose a robust multi-agent reinforcement learning framework for collaborative reasoning, consisting of two components: Dual-Agent Answer-Critique-Rewrite (DACR) and an Adaptive Robust Estimator (ARE). DACR decomposes reasoning into a structured three-stage pipeline: answer, critique, and rewrite, while enabling explicit attribution of each agent's marginal contribution to its partner's performance. ARE provides robust estimation of batch experience means during multi-agent policy optimization. Across mathematical reasoning and embodied intelligence benchmarks, even under noisy rewards, our method consistently outperforms the baseline in both homogeneous and heterogeneous settings. These results indicate stronger robustness to reward noise and more stable training dynamics, effectively preventing optimization failures caused by noisy reward signals.
Counterfactual Credit Policy Optimization for Multi-Agent Collaboration
Mar 23, 2026Collaborative multi-agent large language models (LLMs) can solve complex reasoning tasks by decomposing roles and aggregating diverse hypotheses. Yet, reinforcement learning (RL) for such systems is often undermined by credit assignment: a shared global reward obscures individual contributions, inflating update variance and encouraging free-riding. We introduce Counterfactual Credit Policy Optimization (CCPO), a framework that assigns agent-specific learning signals by estimating each agent's marginal contribution through counterfactual trajectories. CCPO builds dynamic counterfactual baselines that simulate outcomes with an agent's contribution removed, yielding role-sensitive advantages for policy optimization. To further improve stability under heterogeneous tasks and data distributions, we propose a global-history-aware normalization scheme that calibrates advantages using global rollout statistics. We evaluate CCPO on two collaboration topologies: a sequential Think--Reason dyad and multi-agent voting. Across mathematical and logical reasoning benchmarks, CCPO mitigates free-riding and outperforms strong multi-agent RL baselines, yielding finer-grained and more effective credit assignment for collaborative LLM training. Our code is available at https://github.com/bhai114/ccpo.
Selective Reviews of Bandit Problems in AI via a Statistical View
Dec 03, 2024



Reinforcement Learning (RL) is a widely researched area in artificial intelligence that focuses on teaching agents decision-making through interactions with their environment. A key subset includes stochastic multi-armed bandit (MAB) and continuum-armed bandit (SCAB) problems, which model sequential decision-making under uncertainty. This review outlines the foundational models and assumptions of bandit problems, explores non-asymptotic theoretical tools like concentration inequalities and minimax regret bounds, and compares frequentist and Bayesian algorithms for managing exploration-exploitation trade-offs. We also extend the discussion to $K$-armed contextual bandits and SCAB, examining their methodologies, regret analyses, and discussing the relation between the SCAB problems and the functional data analysis. Finally, we highlight recent advances and ongoing challenges in the field.
Tight Non-asymptotic Inference via Sub-Gaussian Intrinsic Moment Norm
Mar 13, 2023In non-asymptotic statistical inferences, variance-type parameters of sub-Gaussian distributions play a crucial role. However, direct estimation of these parameters based on the empirical moment generating function (MGF) is infeasible. To this end, we recommend using a sub-Gaussian intrinsic moment norm [Buldygin and Kozachenko (2000), Theorem 1.3] through maximizing a series of normalized moments. Importantly, the recommended norm can not only recover the exponential moment bounds for the corresponding MGFs, but also lead to tighter Hoeffding's sub-Gaussian concentration inequalities. In practice, {\color{black} we propose an intuitive way of checking sub-Gaussian data with a finite sample size by the sub-Gaussian plot}. Intrinsic moment norm can be robustly estimated via a simple plug-in approach. Our theoretical results are applied to non-asymptotic analysis, including the multi-armed bandit.
Distribution Estimation of Contaminated Data via DNN-based MoM-GANs
Dec 28, 2022This paper studies the distribution estimation of contaminated data by the MoM-GAN method, which combines generative adversarial net (GAN) and median-of-mean (MoM) estimation. We use a deep neural network (DNN) with a ReLU activation function to model the generator and discriminator of the GAN. Theoretically, we derive a non-asymptotic error bound for the DNN-based MoM-GAN estimator measured by integral probability metrics with the $b$-smoothness H\"{o}lder class. The error bound decreases essentially as $n^{-b/p}\vee n^{-1/2}$, where $n$ and $p$ are the sample size and the dimension of input data. We give an algorithm for the MoM-GAN method and implement it through two real applications. The numerical results show that the MoM-GAN outperforms other competitive methods when dealing with contaminated data.
Inference and FDR Control for Simulated Ising Models in High-dimension
Feb 11, 2022This paper studies the consistency and statistical inference of simulated Ising models in the high dimensional background. Our estimators are based on the Markov chain Monte Carlo maximum likelihood estimation (MCMC-MLE) method penalized by the Elastic-net. Under mild conditions that ensure a specific convergence rate of MCMC method, the $\ell_{1}$ consistency of Elastic-net-penalized MCMC-MLE is proved. We further propose a decorrelated score test based on the decorrelated score function and prove the asymptotic normality of the score function without the influence of many nuisance parameters under the assumption that accelerates the convergence of the MCMC method. The one-step estimator for a single parameter of interest is purposed by linearizing the decorrelated score function to solve its root, as well as its normality and confidence interval for the true value, therefore, be established. Finally, we use different algorithms to control the false discovery rate (FDR) via traditional p-values and novel e-values.
Non-Asymptotic Guarantees for Robust Statistical Learning under $(1+\varepsilon)$-th Moment Assumption
Jan 10, 2022
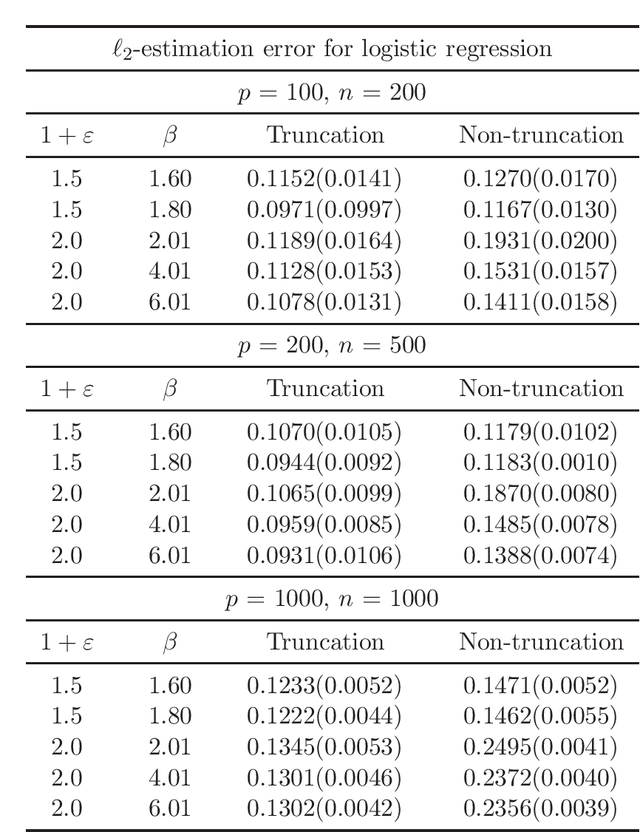
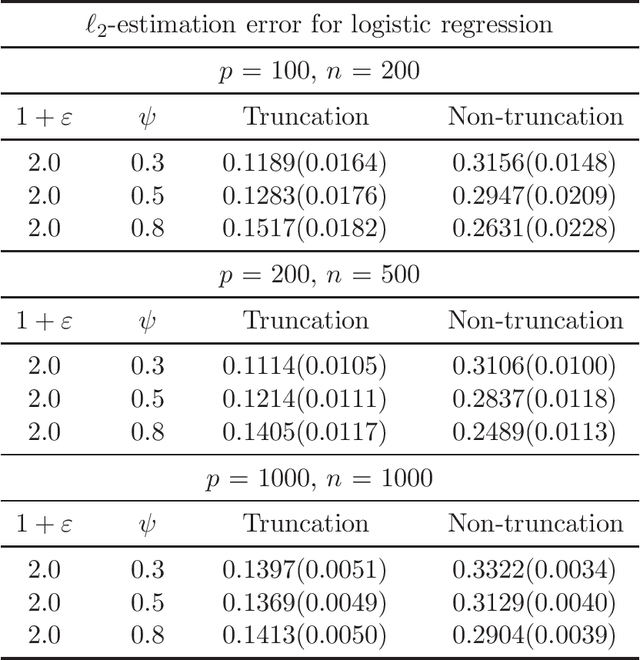
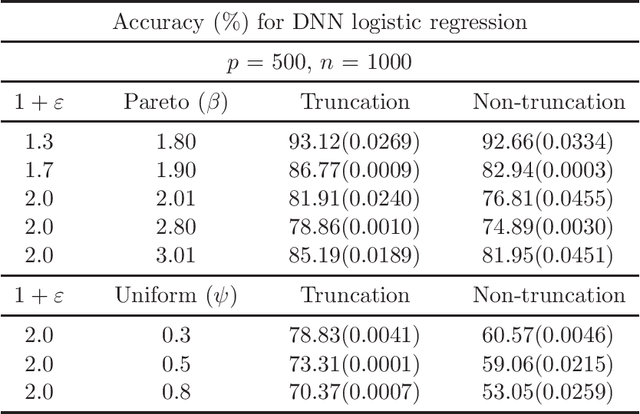
There has been a surge of interest in developing robust estimators for models with heavy-tailed data in statistics and machine learning. This paper proposes a log-truncated M-estimator for a large family of statistical regressions and establishes its excess risk bound under the condition that the data have $(1+\varepsilon)$-th moment with $\varepsilon \in (0,1]$. With an additional assumption on the associated risk function, we obtain an $\ell_2$-error bound for the estimation. Our theorems are applied to establish robust M-estimators for concrete regressions. Besides convex regressions such as quantile regression and generalized linear models, many non-convex regressions can also be fit into our theorems, we focus on robust deep neural network regressions, which can be solved by the stochastic gradient descent algorithms. Simulations and real data analysis demonstrate the superiority of log-truncated estimations over standard estimations.