 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMahalanobis Distance-based Multi-view Optimal Transport for Multi-view Crowd Localization
Sep 03, 2024



Multi-view crowd localization predicts the ground locations of all people in the scene. Typical methods usually estimate the crowd density maps on the ground plane first, and then obtain the crowd locations. However, the performance of existing methods is limited by the ambiguity of the density maps in crowded areas, where local peaks can be smoothed away. To mitigate the weakness of density map supervision, optimal transport-based point supervision methods have been proposed in the single-image crowd localization tasks, but have not been explored for multi-view crowd localization yet. Thus, in this paper, we propose a novel Mahalanobis distance-based multi-view optimal transport (M-MVOT) loss specifically designed for multi-view crowd localization. First, we replace the Euclidean-based transport cost with the Mahalanobis distance, which defines elliptical iso-contours in the cost function whose long-axis and short-axis directions are guided by the view ray direction. Second, the object-to-camera distance in each view is used to adjust the optimal transport cost of each location further, where the wrong predictions far away from the camera are more heavily penalized. Finally, we propose a strategy to consider all the input camera views in the model loss (M-MVOT) by computing the optimal transport cost for each ground-truth point based on its closest camera. Experiments demonstrate the advantage of the proposed method over density map-based or common Euclidean distance-based optimal transport loss on several multi-view crowd localization datasets. Project page: https://vcc.tech/research/2024/MVOT.
Adapt PointFormer: 3D Point Cloud Analysis via Adapting 2D Visual Transformers
Jul 18, 2024



Pre-trained large-scale models have exhibited remarkable efficacy in computer vision, particularly for 2D image analysis. However, when it comes to 3D point clouds, the constrained accessibility of data, in contrast to the vast repositories of images, poses a challenge for the development of 3D pre-trained models. This paper therefore attempts to directly leverage pre-trained models with 2D prior knowledge to accomplish the tasks for 3D point cloud analysis. Accordingly, we propose the Adaptive PointFormer (APF), which fine-tunes pre-trained 2D models with only a modest number of parameters to directly process point clouds, obviating the need for mapping to images. Specifically, we convert raw point clouds into point embeddings for aligning dimensions with image tokens. Given the inherent disorder in point clouds, in contrast to the structured nature of images, we then sequence the point embeddings to optimize the utilization of 2D attention priors. To calibrate attention across 3D and 2D domains and reduce computational overhead, a trainable PointFormer with a limited number of parameters is subsequently concatenated to a frozen pre-trained image model. Extensive experiments on various benchmarks demonstrate the effectiveness of the proposed APF. The source code and more details are available at https://vcc.tech/research/2024/PointFormer.
Generating 3D House Wireframes with Semantics
Jul 17, 2024We present a new approach for generating 3D house wireframes with semantic enrichment using an autoregressive model. Unlike conventional generative models that independently process vertices, edges, and faces, our approach employs a unified wire-based representation for improved coherence in learning 3D wireframe structures. By re-ordering wire sequences based on semantic meanings, we facilitate seamless semantic integration during sequence generation. Our two-phase technique merges a graph-based autoencoder with a transformer-based decoder to learn latent geometric tokens and generate semantic-aware wireframes. Through iterative prediction and decoding during inference, our model produces detailed wireframes that can be easily segmented into distinct components, such as walls, roofs, and rooms, reflecting the semantic essence of the shape. Empirical results on a comprehensive house dataset validate the superior accuracy, novelty, and semantic fidelity of our model compared to existing generative models. More results and details can be found on https://vcc.tech/research/2024/3DWire.
FRI-Net: Floorplan Reconstruction via Room-wise Implicit Representation
Jul 15, 2024



In this paper, we introduce a novel method called FRI-Net for 2D floorplan reconstruction from 3D point cloud. Existing methods typically rely on corner regression or box regression, which lack consideration for the global shapes of rooms. To address these issues, we propose a novel approach using a room-wise implicit representation with structural regularization to characterize the shapes of rooms in floorplans. By incorporating geometric priors of room layouts in floorplans into our training strategy, the generated room polygons are more geometrically regular. We have conducted experiments on two challenging datasets, Structured3D and SceneCAD. Our method demonstrates improved performance compared to state-of-the-art methods, validating the effectiveness of our proposed representation for floorplan reconstruction.
Split-and-Fit: Learning B-Reps via Structure-Aware Voronoi Partitioning
Jun 07, 2024



We introduce a novel method for acquiring boundary representations (B-Reps) of 3D CAD models which involves a two-step process: it first applies a spatial partitioning, referred to as the ``split``, followed by a ``fit`` operation to derive a single primitive within each partition. Specifically, our partitioning aims to produce the classical Voronoi diagram of the set of ground-truth (GT) B-Rep primitives. In contrast to prior B-Rep constructions which were bottom-up, either via direct primitive fitting or point clustering, our Split-and-Fit approach is top-down and structure-aware, since a Voronoi partition explicitly reveals both the number of and the connections between the primitives. We design a neural network to predict the Voronoi diagram from an input point cloud or distance field via a binary classification. We show that our network, coined NVD-Net for neural Voronoi diagrams, can effectively learn Voronoi partitions for CAD models from training data and exhibits superior generalization capabilities. Extensive experiments and evaluation demonstrate that the resulting B-Reps, consisting of parametric surfaces, curves, and vertices, are more plausible than those obtained by existing alternatives, with significant improvements in reconstruction quality. Code will be released on https://github.com/yilinliu77/NVDNet.
Multi-View People Detection in Large Scenes via Supervised View-Wise Contribution Weighting
May 30, 2024



Recent deep learning-based multi-view people detection (MVD) methods have shown promising results on existing datasets. However, current methods are mainly trained and evaluated on small, single scenes with a limited number of multi-view frames and fixed camera views. As a result, these methods may not be practical for detecting people in larger, more complex scenes with severe occlusions and camera calibration errors. This paper focuses on improving multi-view people detection by developing a supervised view-wise contribution weighting approach that better fuses multi-camera information under large scenes. Besides, a large synthetic dataset is adopted to enhance the model's generalization ability and enable more practical evaluation and comparison. The model's performance on new testing scenes is further improved with a simple domain adaptation technique. Experimental results demonstrate the effectiveness of our approach in achieving promising cross-scene multi-view people detection performance. See code here: https://vcc.tech/research/2024/MVD.
EmoEdit: Evoking Emotions through Image Manipulation
May 21, 2024



Affective Image Manipulation (AIM) seeks to modify user-provided images to evoke specific emotional responses. This task is inherently complex due to its twofold objective: significantly evoking the intended emotion, while preserving the original image composition. Existing AIM methods primarily adjust color and style, often failing to elicit precise and profound emotional shifts. Drawing on psychological insights, we extend AIM by incorporating content modifications to enhance emotional impact. We introduce EmoEdit, a novel two-stage framework comprising emotion attribution and image editing. In the emotion attribution stage, we leverage a Vision-Language Model (VLM) to create hierarchies of semantic factors that represent abstract emotions. In the image editing stage, the VLM identifies the most relevant factors for the provided image, and guides a generative editing model to perform affective modifications. A ranking technique that we developed selects the best edit, balancing between emotion fidelity and structure integrity. To validate EmoEdit, we assembled a dataset of 416 images, categorized into positive, negative, and neutral classes. Our method is evaluated both qualitatively and quantitatively, demonstrating superior performance compared to existing state-of-the-art techniques. Additionally, we showcase EmoEdit's potential in various manipulation tasks, including emotion-oriented and semantics-oriented editing.
Spatial and Surface Correspondence Field for Interaction Transfer
May 06, 2024



In this paper, we introduce a new method for the task of interaction transfer. Given an example interaction between a source object and an agent, our method can automatically infer both surface and spatial relationships for the agent and target objects within the same category, yielding more accurate and valid transfers. Specifically, our method characterizes the example interaction using a combined spatial and surface representation. We correspond the agent points and object points related to the representation to the target object space using a learned spatial and surface correspondence field, which represents objects as deformed and rotated signed distance fields. With the corresponded points, an optimization is performed under the constraints of our spatial and surface interaction representation and additional regularization. Experiments conducted on human-chair and hand-mug interaction transfer tasks show that our approach can handle larger geometry and topology variations between source and target shapes, significantly outperforming state-of-the-art methods.
LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
May 06, 2024



In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024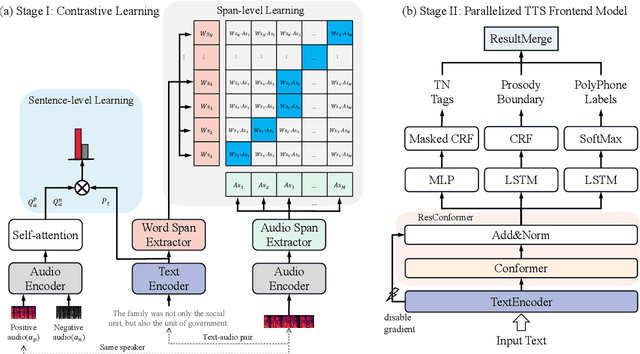
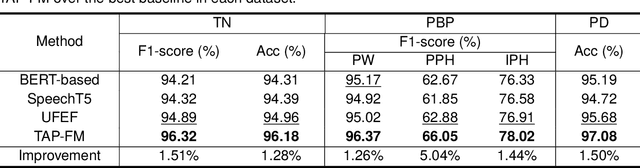

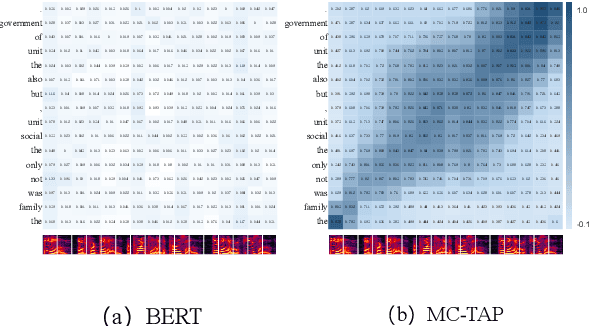
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.