 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointLLM-R: Enhancing 3D Point Cloud Reasoning via Chain-of-Thought
May 21, 2026Understanding 3D point clouds through language remains a fundamental challenge in computer graphics and visual computing, due to the irregular structure of point cloud data and the lack of explicit reasoning in existing 3D multimodal models. While Chain-of-Thought (CoT) reasoning has shown strong effectiveness in LLMs and image-based MLLMs, its extension to 3D understanding remains largely underexplored. In this paper, we propose a data-centric framework for constructing large-scale CoT supervision tailored to 3D point cloud understanding. Our framework consists of a two-stage pipeline that first refines point-text instruction data via vision-language-model-based quality evaluation and reference-guided refinement, and then synthesizes high-quality reasoning paths through Human-in-the-Loop Prompt Optimization (HiLPO). Using this approach, we build PoCoTI, a CoT-enhanced point-text instruction-following dataset containing 55K samples with explicit reasoning paths. Fine-tuning PointLLM on PoCoTI yields PointLLM-R, a reasoning-capable 3D multimodal language model. Extensive experiments on generative 3D classification and captioning demonstrate that PointLLM-R achieves state-of-the-art performance and generalizes robustly to real-world scanned point clouds and multi-turn dialogue scenarios.
Know Your Intent: An Autonomous Multi-Perspective LLM Agent Framework for DeFi User Transaction Intent Mining
Nov 19, 2025



As Decentralized Finance (DeFi) develops, understanding user intent behind DeFi transactions is crucial yet challenging due to complex smart contract interactions, multifaceted on-/off-chain factors, and opaque hex logs. Existing methods lack deep semantic insight. To address this, we propose the Transaction Intent Mining (TIM) framework. TIM leverages a DeFi intent taxonomy built on grounded theory and a multi-agent Large Language Model (LLM) system to robustly infer user intents. A Meta-Level Planner dynamically coordinates domain experts to decompose multiple perspective-specific intent analyses into solvable subtasks. Question Solvers handle the tasks with multi-modal on/off-chain data. While a Cognitive Evaluator mitigates LLM hallucinations and ensures verifiability. Experiments show that TIM significantly outperforms machine learning models, single LLMs, and single Agent baselines. We also analyze core challenges in intent inference. This work helps provide a more reliable understanding of user motivations in DeFi, offering context-aware explanations for complex blockchain activity.
HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sep 16, 2024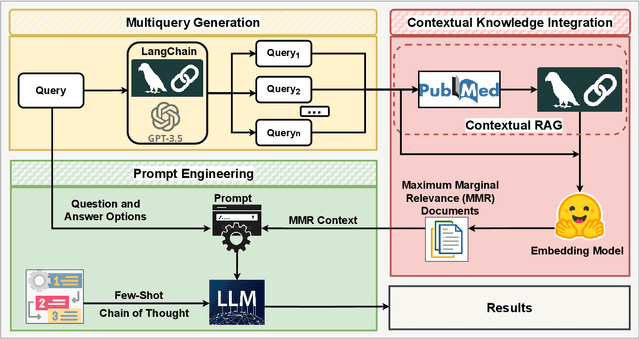
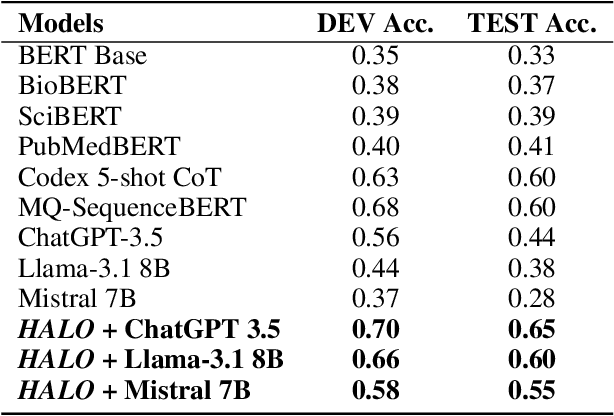


Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.
Generating 3D House Wireframes with Semantics
Jul 17, 2024We present a new approach for generating 3D house wireframes with semantic enrichment using an autoregressive model. Unlike conventional generative models that independently process vertices, edges, and faces, our approach employs a unified wire-based representation for improved coherence in learning 3D wireframe structures. By re-ordering wire sequences based on semantic meanings, we facilitate seamless semantic integration during sequence generation. Our two-phase technique merges a graph-based autoencoder with a transformer-based decoder to learn latent geometric tokens and generate semantic-aware wireframes. Through iterative prediction and decoding during inference, our model produces detailed wireframes that can be easily segmented into distinct components, such as walls, roofs, and rooms, reflecting the semantic essence of the shape. Empirical results on a comprehensive house dataset validate the superior accuracy, novelty, and semantic fidelity of our model compared to existing generative models. More results and details can be found on https://vcc.tech/research/2024/3DWire.
PELP: Pioneer Event Log Prediction Using Sequence-to-Sequence Neural Networks
Dec 15, 2023Process mining, a data-driven approach for analyzing, visualizing, and improving business processes using event logs, has emerged as a powerful technique in the field of business process management. Process forecasting is a sub-field of process mining that studies how to predict future processes and process models. In this paper, we introduce and motivate the problem of event log prediction and present our approach to solving the event log prediction problem, in particular, using the sequence-to-sequence deep learning approach. We evaluate and analyze the prediction outcomes on a variety of synthetic logs and seven real-life logs and show that our approach can generate perfect predictions on synthetic logs and that deep learning techniques have the potential to be applied in real-world event log prediction tasks. We further provide practical recommendations for event log predictions grounded in the outcomes of the conducted experiments.
NECA: Network-Embedded Deep Representation Learning for Categorical Data
May 25, 2022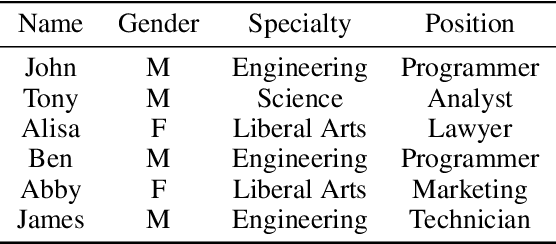
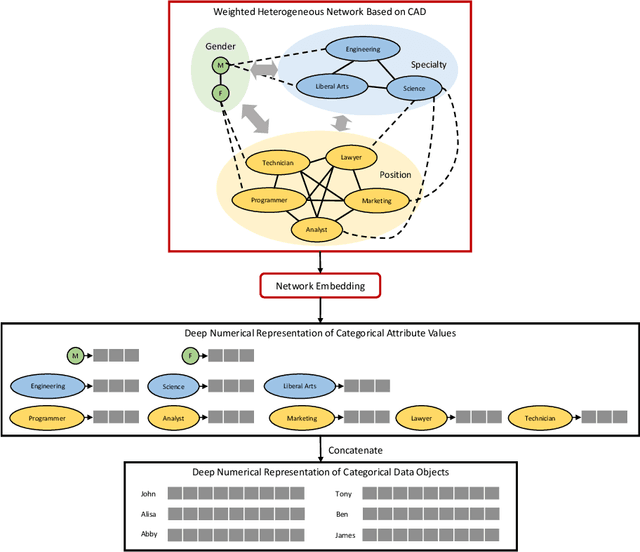
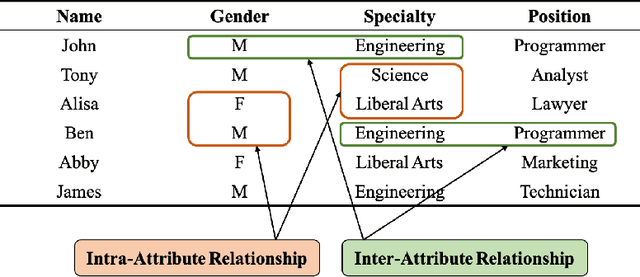
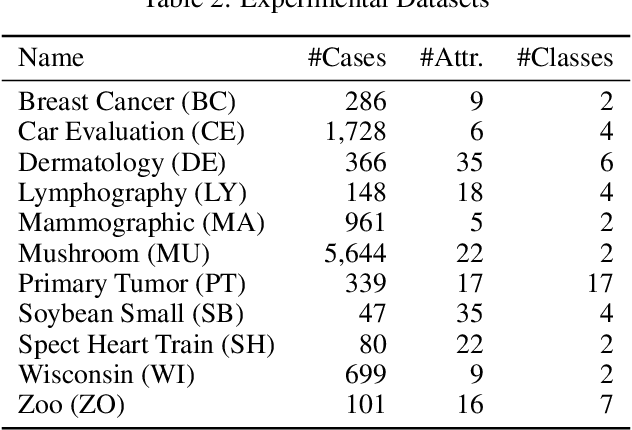
We propose NECA, a deep representation learning method for categorical data. Built upon the foundations of network embedding and deep unsupervised representation learning, NECA deeply embeds the intrinsic relationship among attribute values and explicitly expresses data objects with numeric vector representations. Designed specifically for categorical data, NECA can support important downstream data mining tasks, such as clustering. Extensive experimental analysis demonstrated the effectiveness of NECA.
Seed Stocking Via Multi-Task Learning
Jan 12, 2021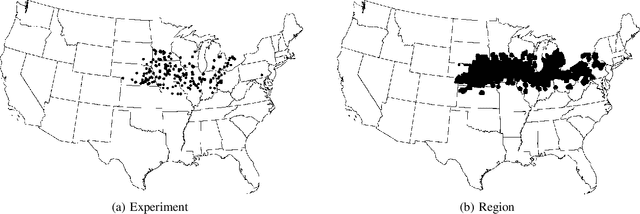
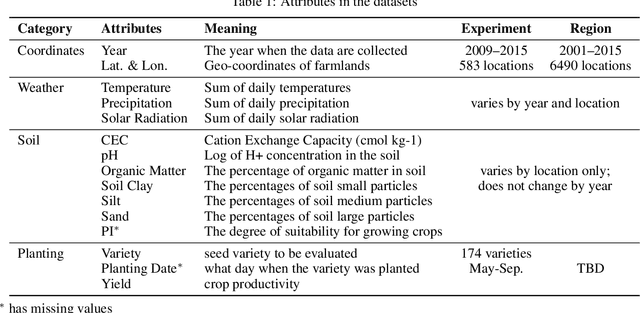

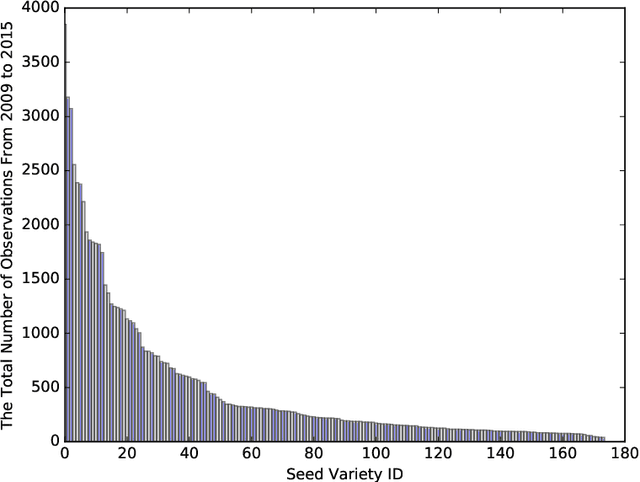
Sellers of crop seeds need to plan for the variety and quantity of seeds to stock at least a year in advance. There are a large number of seed varieties of one crop, and each can perform best under different growing conditions. Given the unpredictability of weather, farmers need to make decisions that balance high yield and low risk. A seed vendor needs to be able to anticipate the needs of farmers and have them ready. In this study, we propose an analytical framework for estimating seed demand with three major steps. First, we will estimate the yield and risk of each variety as if they were planted at each location. Since past experiments performed with different seed varieties are highly unbalanced across varieties, and the combination of growing conditions is sparse, we employ multi-task learning to borrow information from similar varieties. Second, we will determine the best mix of seeds for each location by seeking a tradeoff between yield and risk. Third, we will aggregate such mix and pick the top five varieties to re-balance the yield and risk for each growing location. We find that multi-task learning provides a viable solution for yield prediction, and our overall analytical framework has resulted in a good performance.
Co-occurrence Background Model with Superpixels for Robust Background Initialization
Mar 29, 2020
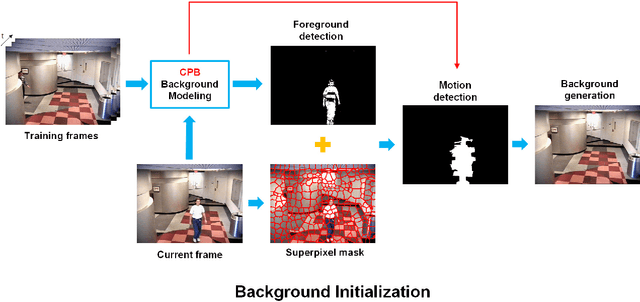
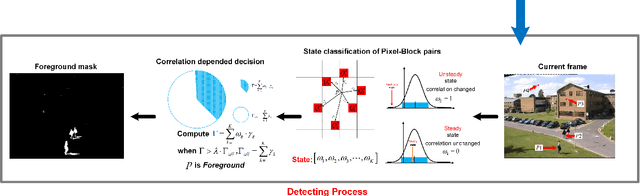

Background initialization is an important step in many high-level applications of video processing,ranging from video surveillance to video inpainting.However,this process is often affected by practical challenges such as illumination changes,background motion,camera jitter and intermittent movement,etc.In this paper,we develop a co-occurrence background model with superpixel segmentation for robust background initialization. We first introduce a novel co-occurrence background modeling method called as Co-occurrence Pixel-Block Pairs(CPB)to generate a reliable initial background model,and the superpixel segmentation is utilized to further acquire the spatial texture Information of foreground and background.Then,the initial background can be determined by combining the foreground extraction results with the superpixel segmentation information.Experimental results obtained from the dataset of the challenging benchmark(SBMnet)validate it's performance under various challenges.