 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Games as Informal Training for Generalizable LLMs
Jan 09, 2026While Large Language Models (LLMs) have achieved remarkable success in formal learning tasks such as mathematics and code generation, they still struggle with the "practical wisdom" and generalizable intelligence, such as strategic creativity and social reasoning, that characterize human cognition. This gap arises from a lack of informal learning, which thrives on interactive feedback rather than goal-oriented instruction. In this paper, we propose treating Games as a primary environment for LLM informal learning, leveraging their intrinsic reward signals and abstracted complexity to cultivate diverse competencies. To address the performance degradation observed in multi-task learning, we introduce a Nested Training Framework. Unlike naive task mixing optimizing an implicit "OR" objective, our framework employs sequential task composition to enforce an explicit "AND" objective, compelling the model to master multiple abilities simultaneously to achieve maximal rewards. Using GRPO-based reinforcement learning across Matrix Games, TicTacToe, and Who's the Spy games, we demonstrate that integrating game-based informal learning not only prevents task interference but also significantly bolsters the model's generalization across broad ability-oriented benchmarks. The framework and implementation are publicly available.
Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain Generalization
Jan 08, 2026Supervised fine-tuning (SFT) on chain-of-thought (CoT) trajectories demonstrations is a common approach for enabling reasoning in large language models. Standard practices typically only retain trajectories with correct final answers (positives) while ignoring the rest (negatives). We argue that this paradigm discards substantial supervision and exacerbates overfitting, limiting out-of-domain (OOD) generalization. Specifically, we surprisingly find that incorporating negative trajectories into SFT yields substantial OOD generalization gains over positive-only training, as these trajectories often retain valid intermediate reasoning despite incorrect final answers. To understand this effect in depth, we systematically analyze data, training dynamics, and inference behavior, identifying 22 recurring patterns in negative chains that serve a dual role: they moderate loss descent to mitigate overfitting during training and boost policy entropy by 35.67% during inference to facilitate exploration. Motivated by these observations, we further propose Gain-based LOss Weighting (GLOW), an adaptive, sample-aware scheme that exploits such distinctive training dynamics by rescaling per-sample loss based on inter-epoch progress. Empirically, GLOW efficiently leverages unfiltered trajectories, yielding a 5.51% OOD gain over positive-only SFT on Qwen2.5-7B and boosting MMLU from 72.82% to 76.47% as an RL initialization.
Fine-tuning Done Right in Model Editing
Sep 26, 2025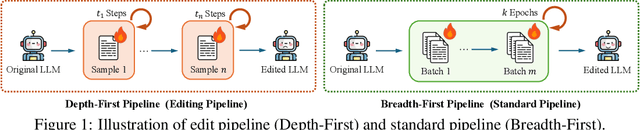

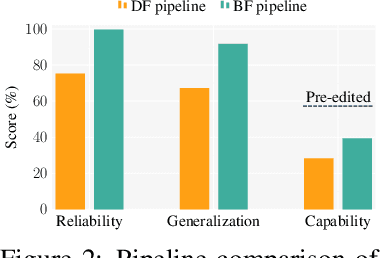

Fine-tuning, a foundational method for adapting large language models, has long been considered ineffective for model editing. Here, we challenge this belief, arguing that the reported failure arises not from the inherent limitation of fine-tuning itself, but from adapting it to the sequential nature of the editing task, a single-pass depth-first pipeline that optimizes each sample to convergence before moving on. While intuitive, this depth-first pipeline coupled with sample-wise updating over-optimizes each edit and induces interference across edits. Our controlled experiments reveal that simply restoring fine-tuning to the standard breadth-first (i.e., epoch-based) pipeline with mini-batch optimization substantially improves its effectiveness for model editing. Moreover, fine-tuning in editing also suffers from suboptimal tuning parameter locations inherited from prior methods. Through systematic analysis of tuning locations, we derive LocFT-BF, a simple and effective localized editing method built on the restored fine-tuning framework. Extensive experiments across diverse LLMs and datasets demonstrate that LocFT-BF outperforms state-of-the-art methods by large margins. Notably, to our knowledge, it is the first to sustain 100K edits and 72B-parameter models,10 x beyond prior practice, without sacrificing general capabilities. By clarifying a long-standing misconception and introducing a principled localized tuning strategy, we advance fine-tuning from an underestimated baseline to a leading method for model editing, establishing a solid foundation for future research.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
LLM4MEA: Data-free Model Extraction Attacks on Sequential Recommenders via Large Language Models
Jul 22, 2025Recent studies have demonstrated the vulnerability of sequential recommender systems to Model Extraction Attacks (MEAs). MEAs collect responses from recommender systems to replicate their functionality, enabling unauthorized deployments and posing critical privacy and security risks. Black-box attacks in prior MEAs are ineffective at exposing recommender system vulnerabilities due to random sampling in data selection, which leads to misaligned synthetic and real-world distributions. To overcome this limitation, we propose LLM4MEA, a novel model extraction method that leverages Large Language Models (LLMs) as human-like rankers to generate data. It generates data through interactions between the LLM ranker and target recommender system. In each interaction, the LLM ranker analyzes historical interactions to understand user behavior, and selects items from recommendations with consistent preferences to extend the interaction history, which serves as training data for MEA. Extensive experiments demonstrate that LLM4MEA significantly outperforms existing approaches in data quality and attack performance, reducing the divergence between synthetic and real-world data by up to 64.98% and improving MEA performance by 44.82% on average. From a defensive perspective, we propose a simple yet effective defense strategy and identify key hyperparameters of recommender systems that can mitigate the risk of MEAs.
From Outcomes to Processes: Guiding PRM Learning from ORM for Inference-Time Alignment
Jun 14, 2025



Inference-time alignment methods have gained significant attention for their efficiency and effectiveness in aligning large language models (LLMs) with human preferences. However, existing dominant approaches using reward-guided search (RGS) primarily rely on outcome reward models (ORMs), which suffer from a critical granularity mismatch: ORMs are designed to provide outcome rewards for complete responses, while RGS methods rely on process rewards to guide the policy, leading to inconsistent scoring and suboptimal alignment. To address this challenge, we introduce process reward models (PRMs) into RGS and argue that an ideal PRM should satisfy two objectives: Score Consistency, ensuring coherent evaluation across partial and complete responses, and Preference Consistency, aligning partial sequence assessments with human preferences. Based on these, we propose SP-PRM, a novel dual-consistency framework integrating score consistency-based and preference consistency-based partial evaluation modules without relying on human annotation. Extensive experiments on dialogue, summarization, and reasoning tasks demonstrate that SP-PRM substantially enhances existing RGS methods, achieving a 3.6%-10.3% improvement in GPT-4 evaluation scores across all tasks.
Inference-time Alignment in Continuous Space
May 26, 2025Aligning large language models with human feedback at inference time has received increasing attention due to its flexibility. Existing methods rely on generating multiple responses from the base policy for search using a reward model, which can be considered as searching in a discrete response space. However, these methods struggle to explore informative candidates when the base policy is weak or the candidate set is small, resulting in limited effectiveness. In this paper, to address this problem, we propose Simple Energy Adaptation ($\textbf{SEA}$), a simple yet effective algorithm for inference-time alignment. In contrast to expensive search over the discrete space, SEA directly adapts original responses from the base policy toward the optimal one via gradient-based sampling in continuous latent space. Specifically, SEA formulates inference as an iterative optimization procedure on an energy function over actions in the continuous space defined by the optimal policy, enabling simple and effective alignment. For instance, despite its simplicity, SEA outperforms the second-best baseline with a relative improvement of up to $ \textbf{77.51%}$ on AdvBench and $\textbf{16.36%}$ on MATH. Our code is publicly available at https://github.com/yuanyige/SEA
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
InfoNCE is a Free Lunch for Semantically guided Graph Contrastive Learning
May 07, 2025



As an important graph pre-training method, Graph Contrastive Learning (GCL) continues to play a crucial role in the ongoing surge of research on graph foundation models or LLM as enhancer for graphs. Traditional GCL optimizes InfoNCE by using augmentations to define self-supervised tasks, treating augmented pairs as positive samples and others as negative. However, this leads to semantically similar pairs being classified as negative, causing significant sampling bias and limiting performance. In this paper, we argue that GCL is essentially a Positive-Unlabeled (PU) learning problem, where the definition of self-supervised tasks should be semantically guided, i.e., augmented samples with similar semantics are considered positive, while others, with unknown semantics, are treated as unlabeled. From this perspective, the key lies in how to extract semantic information. To achieve this, we propose IFL-GCL, using InfoNCE as a "free lunch" to extract semantic information. Specifically, We first prove that under InfoNCE, the representation similarity of node pairs aligns with the probability that the corresponding contrastive sample is positive. Then we redefine the maximum likelihood objective based on the corrected samples, leading to a new InfoNCE loss function. Extensive experiments on both the graph pretraining framework and LLM as an enhancer show significantly improvements of IFL-GCL in both IID and OOD scenarios, achieving up to a 9.05% improvement, validating the effectiveness of semantically guided. Code for IFL-GCL is publicly available at: https://github.com/Camel-Prince/IFL-GCL.