 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: Self-Generating and Self-Validating Multi-Dimensional Assessment for LLMs' Mathematical Problem Solving
May 22, 2025



Large Language Models have achieved remarkable results on a variety of mathematical benchmarks. However, concerns remain as to whether these successes reflect genuine mathematical reasoning or superficial pattern recognition. Common evaluation metrics, such as final answer accuracy, fail to disentangle the underlying competencies involved, offering limited diagnostic value. To address these limitations, we introduce SMART: a Self-Generating and Self-Validating Multi-Dimensional Assessment Framework. SMART decomposes mathematical problem solving into four distinct dimensions: understanding, reasoning, arithmetic, and reflection \& refinement. Each dimension is evaluated independently through tailored tasks, enabling interpretable and fine-grained analysis of LLM behavior. Crucially, SMART integrates an automated self-generating and self-validating mechanism to produce and verify benchmark data, ensuring both scalability and reliability. We apply SMART to 21 state-of-the-art open- and closed-source LLMs, uncovering significant discrepancies in their abilities across different dimensions. Our findings demonstrate the inadequacy of final answer accuracy as a sole metric and motivate a new holistic metric to better capture true problem-solving capabilities. Code and benchmarks will be released upon acceptance.
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes
Apr 07, 2025Detecting deepfakes has been an increasingly important topic, especially given the rapid development of AI generation techniques. In this paper, we ask: How can we build a universal detection framework that is effective for most facial deepfakes? One significant challenge is the wide variety of deepfake generators available, resulting in varying forgery artifacts (e.g., lighting inconsistency, color mismatch, etc). But should we ``teach" the detector to learn all these artifacts separately? It is impossible and impractical to elaborate on them all. So the core idea is to pinpoint the more common and general artifacts across different deepfakes. Accordingly, we categorize deepfake artifacts into two distinct yet complementary types: Face Inconsistency Artifacts (FIA) and Up-Sampling Artifacts (USA). FIA arise from the challenge of generating all intricate details, inevitably causing inconsistencies between the complex facial features and relatively uniform surrounding areas. USA, on the other hand, are the inevitable traces left by the generator's decoder during the up-sampling process. This categorization stems from the observation that all existing deepfakes typically exhibit one or both of these artifacts. To achieve this, we propose a new data-level pseudo-fake creation framework that constructs fake samples with only the FIA and USA, without introducing extra less-general artifacts. Specifically, we employ a super-resolution to simulate the USA, while design a Blender module that uses image-level self-blending on diverse facial regions to create the FIA. We surprisingly found that, with this intuitive design, a standard image classifier trained only with our pseudo-fake data can non-trivially generalize well to unseen deepfakes.
Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
Sep 01, 2024



Stance detection, which aims to identify public opinion towards specific targets using social media data, is an important yet challenging task. With the proliferation of diverse multimodal social media content including text, and images multimodal stance detection (MSD) has become a crucial research area. However, existing MSD studies have focused on modeling stance within individual text-image pairs, overlooking the multi-party conversational contexts that naturally occur on social media. This limitation stems from a lack of datasets that authentically capture such conversational scenarios, hindering progress in conversational MSD. To address this, we introduce a new multimodal multi-turn conversational stance detection dataset (called MmMtCSD). To derive stances from this challenging dataset, we propose a novel multimodal large language model stance detection framework (MLLM-SD), that learns joint stance representations from textual and visual modalities. Experiments on MmMtCSD show state-of-the-art performance of our proposed MLLM-SD approach for multimodal stance detection. We believe that MmMtCSD will contribute to advancing real-world applications of stance detection research.
Core Knowledge Learning Framework for Graph Adaptation and Scalability Learning
Jul 02, 2024



Graph classification is a pivotal challenge in machine learning, especially within the realm of graph-based data, given its importance in numerous real-world applications such as social network analysis, recommendation systems, and bioinformatics. Despite its significance, graph classification faces several hurdles, including adapting to diverse prediction tasks, training across multiple target domains, and handling small-sample prediction scenarios. Current methods often tackle these challenges individually, leading to fragmented solutions that lack a holistic approach to the overarching problem. In this paper, we propose an algorithm aimed at addressing the aforementioned challenges. By incorporating insights from various types of tasks, our method aims to enhance adaptability, scalability, and generalizability in graph classification. Motivated by the recognition that the underlying subgraph plays a crucial role in GNN prediction, while the remainder is task-irrelevant, we introduce the Core Knowledge Learning (\method{}) framework for graph adaptation and scalability learning. \method{} comprises several key modules, including the core subgraph knowledge submodule, graph domain adaptation module, and few-shot learning module for downstream tasks. Each module is tailored to tackle specific challenges in graph classification, such as domain shift, label inconsistencies, and data scarcity. By learning the core subgraph of the entire graph, we focus on the most pertinent features for task relevance. Consequently, our method offers benefits such as improved model performance, increased domain adaptability, and enhanced robustness to domain variations. Experimental results demonstrate significant performance enhancements achieved by our method compared to state-of-the-art approaches.
More is Better: Deep Domain Adaptation with Multiple Sources
May 01, 2024In many practical applications, it is often difficult and expensive to obtain large-scale labeled data to train state-of-the-art deep neural networks. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) aims to address this problem by aligning the distributions between the source and target domains. Multi-source domain adaptation (MDA) is a powerful and practical extension in which the labeled data may be collected from multiple sources with different distributions. In this survey, we first define various MDA strategies. Then we systematically summarize and compare modern MDA methods in the deep learning era from different perspectives, followed by commonly used datasets and a brief benchmark. Finally, we discuss future research directions for MDA that are worth investigating.
A Logically Consistent Chain-of-Thought Approach for Stance Detection
Dec 26, 2023Zero-shot stance detection (ZSSD) aims to detect stances toward unseen targets. Incorporating background knowledge to enhance transferability between seen and unseen targets constitutes the primary approach of ZSSD. However, these methods often struggle with a knowledge-task disconnect and lack logical consistency in their predictions. To address these issues, we introduce a novel approach named Logically Consistent Chain-of-Thought (LC-CoT) for ZSSD, which improves stance detection by ensuring relevant and logically sound knowledge extraction. LC-CoT employs a three-step process. Initially, it assesses whether supplementary external knowledge is necessary. Subsequently, it uses API calls to retrieve this knowledge, which can be processed by a separate LLM. Finally, a manual exemplar guides the LLM to infer stance categories, using an if-then logical structure to maintain relevance and logical coherence. This structured approach to eliciting background knowledge enhances the model's capability, outperforming traditional supervised methods without relying on labeled data.
Investigating Chain-of-thought with ChatGPT for Stance Detection on Social Media
Apr 06, 2023Stance detection predicts attitudes towards targets in texts and has gained attention with the rise of social media. Traditional approaches include conventional machine learning, early deep neural networks, and pre-trained fine-tuning models. However, with the evolution of very large pre-trained language models (VLPLMs) like ChatGPT (GPT-3.5), traditional methods face deployment challenges. The parameter-free Chain-of-Thought (CoT) approach, not requiring backpropagation training, has emerged as a promising alternative. This paper examines CoT's effectiveness in stance detection tasks, demonstrating its superior accuracy and discussing associated challenges.
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021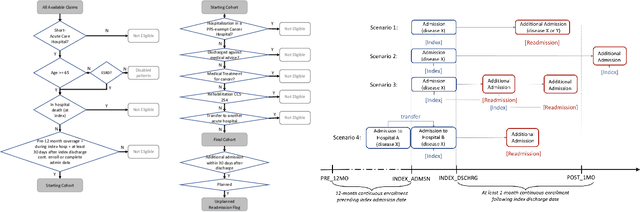
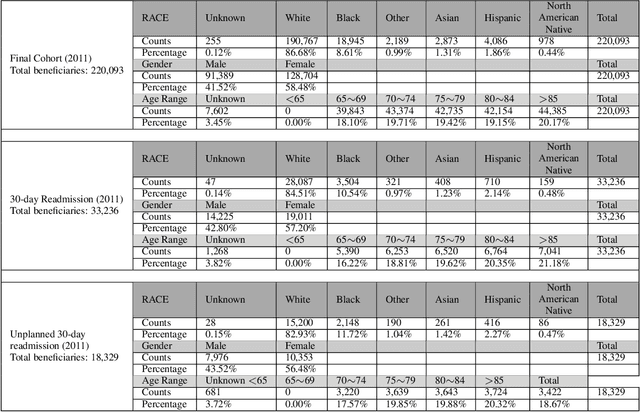
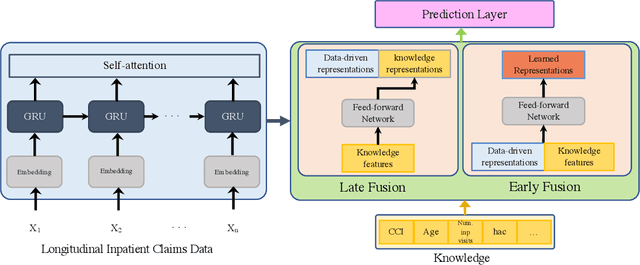

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.