 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Multi-Objective A* Using Balanced Binary Search Trees
Feb 18, 2022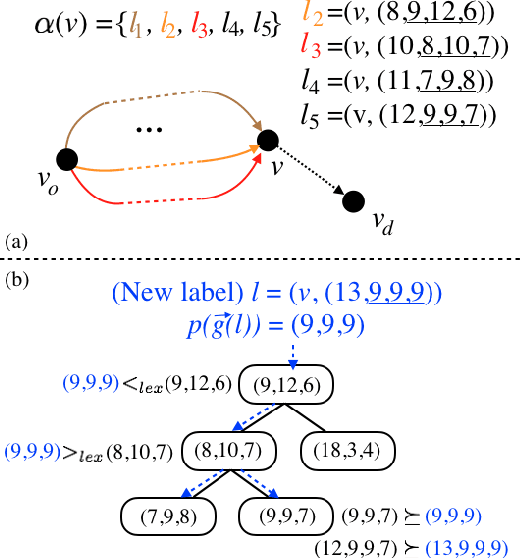

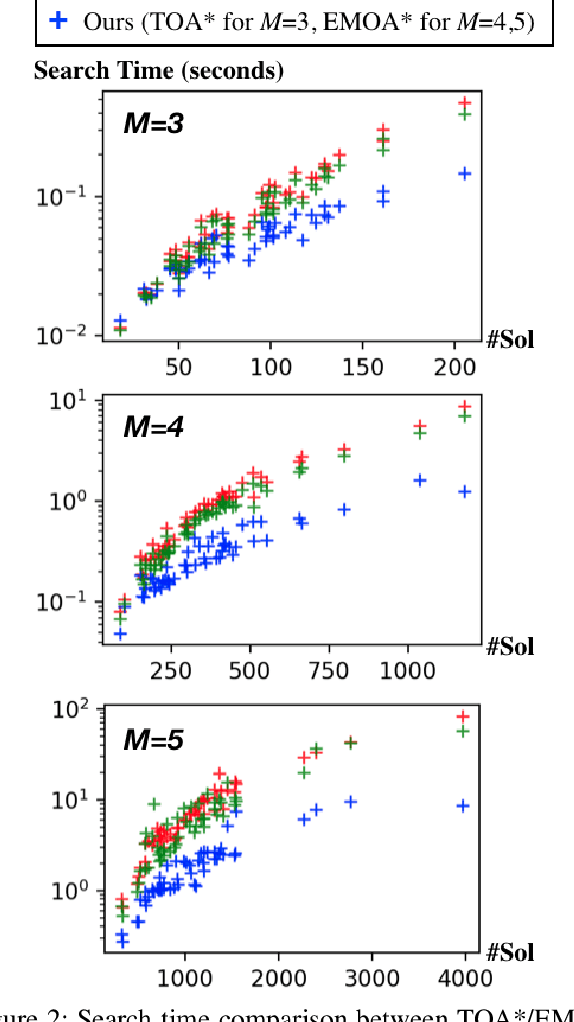
This work addresses the Multi-Objective Shortest Path Problem (MO-SPP): Given a graph where each edge is associated with a non-negative cost vector, MO-SPP aims to find all the Pareto-optimal paths connecting the given start and goal nodes. To solve MO-SPP, the popular multi-objective A* (MOA*) like algorithms maintain a "frontier" set at any node during the search to keep track of the non-dominated paths that reach that node. The computational efficiency of MOA* algorithms directly depend on how efficiently one can maintain the frontier sets. Recently, several techniques have been developed in the literature to address this issue mainly for two objectives. In this work, we introduce a new method to efficiently maintain these frontiers for multiple objectives by leveraging balanced binary search trees. We provide extensive simulation results for problems with three, four and five objectives to show that our method outperforms existing techniques by an order of magnitude in general.
A Lower Bounding Framework for Motion Planning amid Dynamic Obstacles in 2D
Feb 15, 2022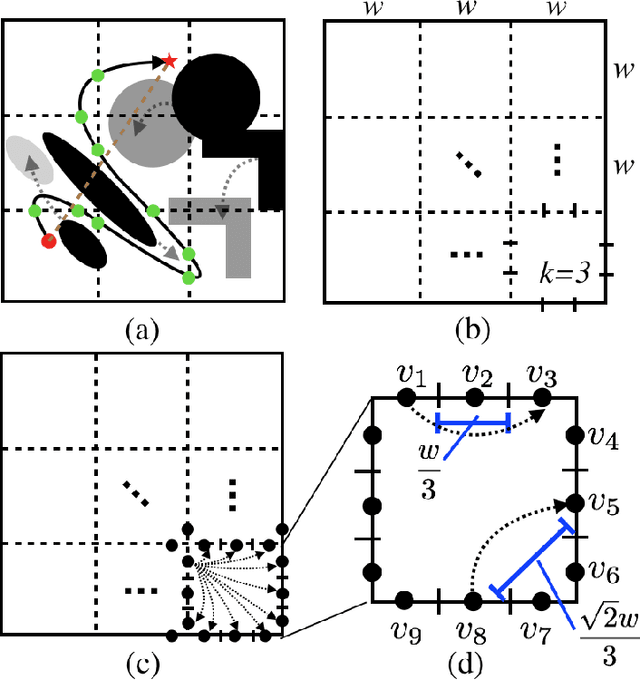
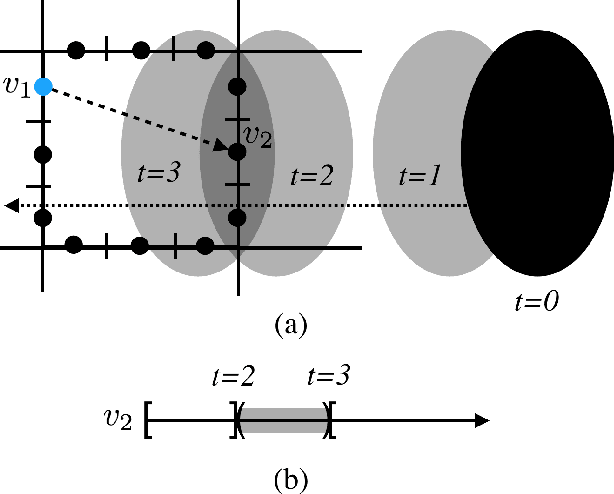
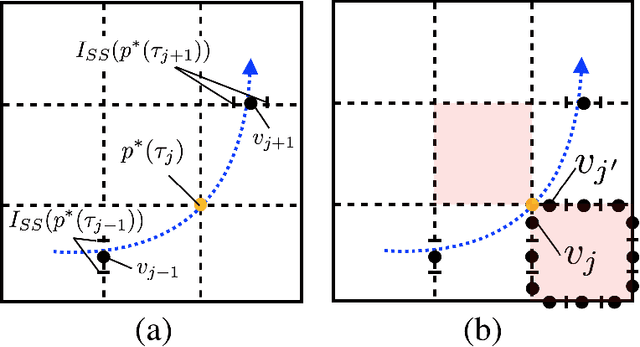
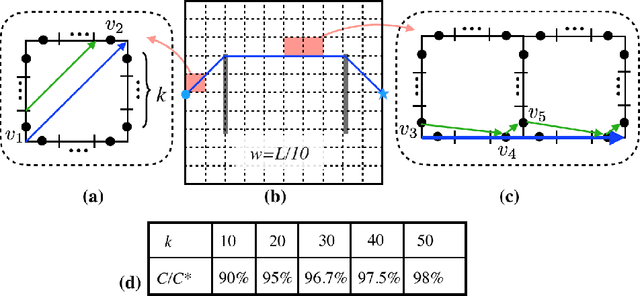
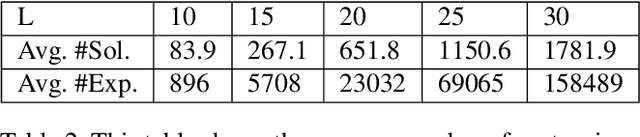
This work considers a Motion Planning Problem with Dynamic Obstacles (MPDO) in 2D that requires finding a minimum-arrival-time collision-free trajectory for a point robot between its start and goal locations amid dynamic obstacles moving along known trajectories. Existing methods, such as continuous Dijkstra paradigm, can find an optimal solution by restricting the shape of the obstacles or the motion of the robot, while this work makes no such assumptions. Other methods, such as search-based planners and sampling-based approaches can compute a feasible solution to this problem but do not provide approximation bounds. Since finding the optimum is challenging for MPDO, this paper develops a framework that can provide tight lower bounds to the optimum. These bounds acts as proxies for the optimum which can then be use to bound the deviation of a feasible solution from the optimum. To accomplish this, we develop a framework that consists of (i) a bi-level discretization approach that converts the MPDO to a relaxed path planning problem, and (ii) an algorithm that can solve the relaxed problem to obtain lower bounds. We also present preliminary numerical results to corroborate the performance of the proposed framework. These results show that the bounds obtained by our approach for some instances are three times larger than a naive baseline approach showcasing potential advantages of the proposed approach.
Generalized Omega Turn Gait Enables Agile Limbless Robot Turning in Complex Environments
Feb 03, 2022
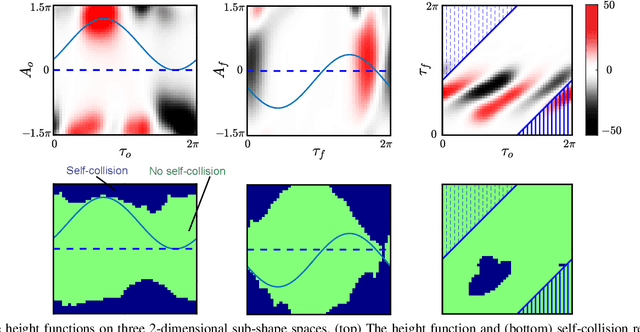
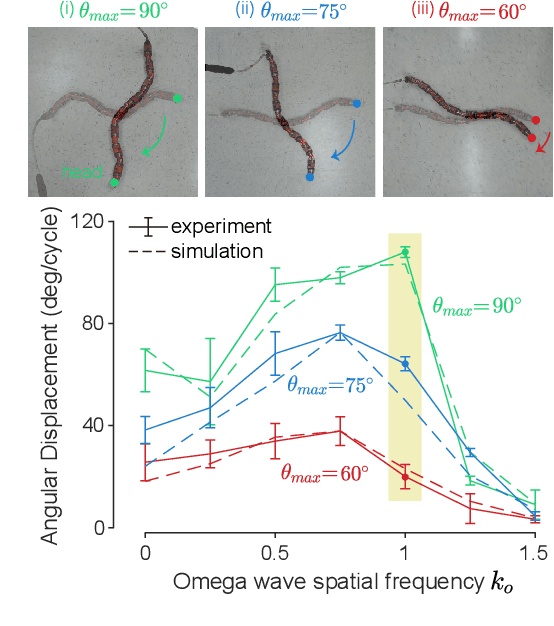
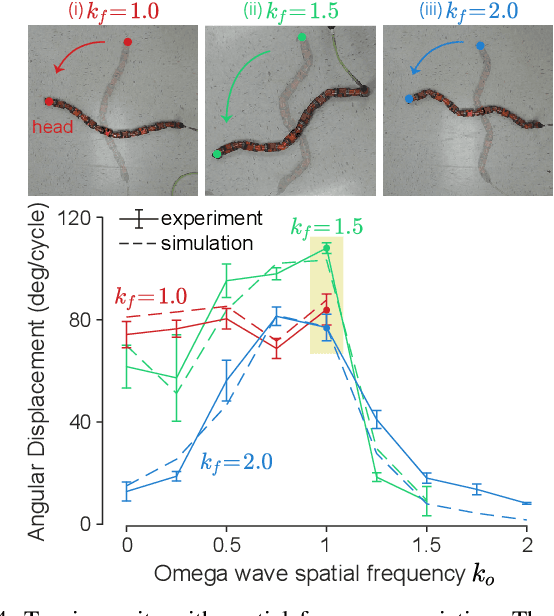
Reorientation (turning in plane) plays a critical role for all robots in any field application, especially those that in confined spaces. While important, reorientation remains a relatively unstudied problem for robots, including limbless mechanisms, often called snake robots. Instead of looking at snakes, we take inspiration from observations of the turning behavior of tiny nematode worms C. elegans. Our previous work presented an in-place and in-plane turning gait for limbless robots, called an omega turn, and prescribed it using a novel two-wave template. In this work, we advance omega turn-inspired controllers in three aspects: 1) we use geometric methods to vary joint angle amplitudes and forward wave spatial frequency in our turning equation to establish a wide and precise amplitude modulation and frequency modulation on omega turn; 2) we use this new relationship to enable robots with fewer internal degrees of freedom (i.e., fewer joints in the body) to achieve desirable performance, and 3) we apply compliant control methods to this relationship to handle unmodelled effects in the environment. We experimentally validate our approach on a limbless robot that the omega turn can produce effective and robust turning motion in various types of environments, such as granular media and rock pile.
Learning Cooperative Multi-Agent Policies with Partial Reward Decoupling
Dec 23, 2021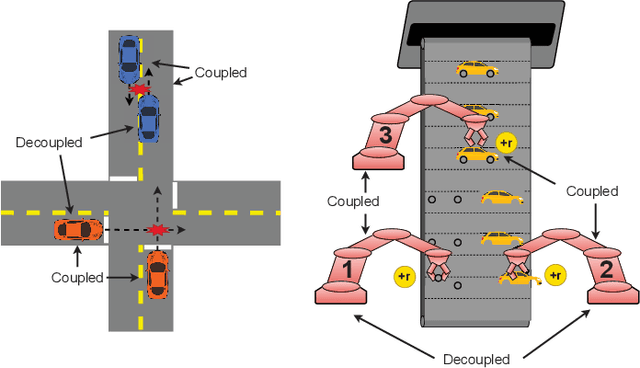
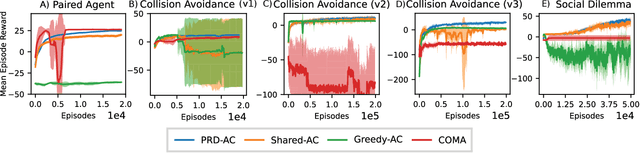
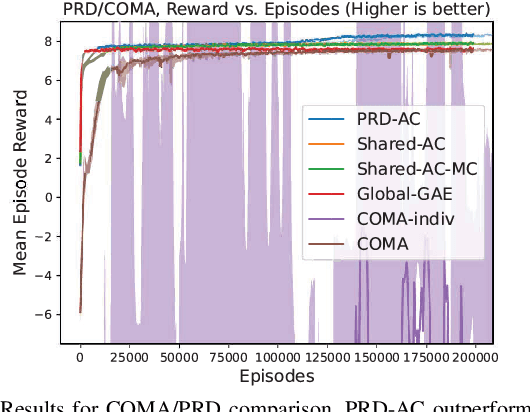
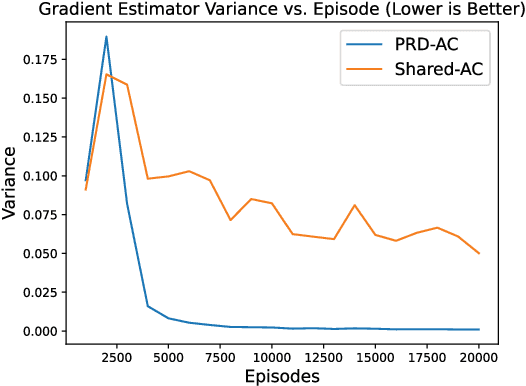
One of the preeminent obstacles to scaling multi-agent reinforcement learning to large numbers of agents is assigning credit to individual agents' actions. In this paper, we address this credit assignment problem with an approach that we call \textit{partial reward decoupling} (PRD), which attempts to decompose large cooperative multi-agent RL problems into decoupled subproblems involving subsets of agents, thereby simplifying credit assignment. We empirically demonstrate that decomposing the RL problem using PRD in an actor-critic algorithm results in lower variance policy gradient estimates, which improves data efficiency, learning stability, and asymptotic performance across a wide array of multi-agent RL tasks, compared to various other actor-critic approaches. Additionally, we relate our approach to counterfactual multi-agent policy gradient (COMA), a state-of-the-art MARL algorithm, and empirically show that our approach outperforms COMA by making better use of information in agents' reward streams, and by enabling recent advances in advantage estimation to be used.
A general locomotion control framework for serially connected multi-legged robots
Dec 01, 2021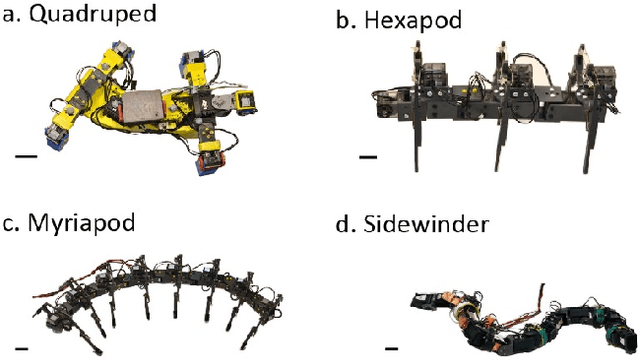

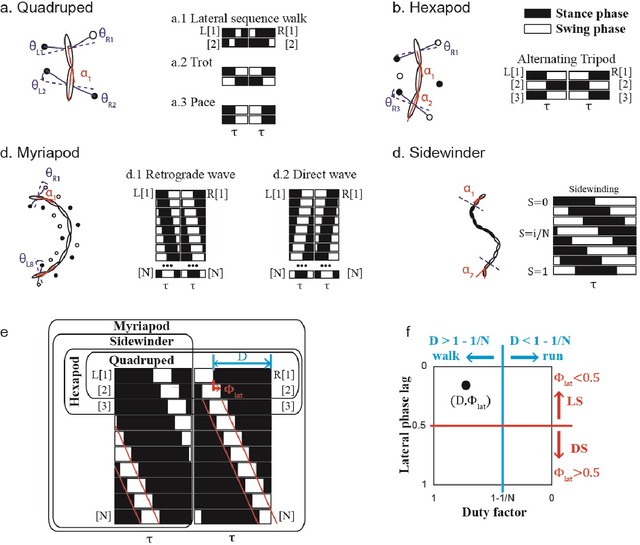
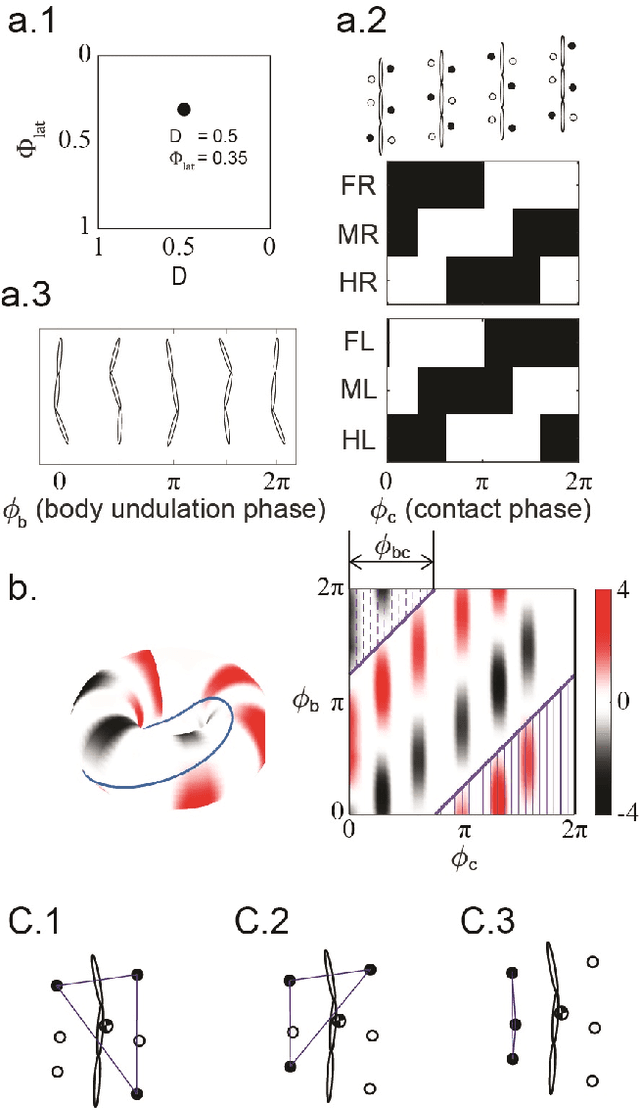
Serially connected robots are promising candidates for performing tasks in confined spaces such as search-and-rescue in large-scale disasters. Such robots are typically limbless, and we hypothesize that the addition of limbs could improve mobility. However, a challenge in designing and controlling such devices lies in the coordination of high-dimensional redundant modules in a way that improves mobility. Here we develop a general framework to control serially connected multi-legged robots. Specifically, we combine two approaches to build a general shape control scheme which can provide baseline patterns of self-deformation ("gaits") for effective locomotion in diverse robot morphologies. First, we take inspiration from a dimensionality reduction and a biological gait classification scheme to generate cyclic patterns of body deformation and foot lifting/lowering, which facilitate generation of arbitrary substrate contact patterns. Second, we use geometric mechanics methods to facilitates identification of optimal phasing of these undulations to maximize speed and/or stability. Our scheme allows the development of effective gaits in multi-legged robots locomoting on flat frictional terrain with diverse number of limbs (4, 6, 16, and even 0 limbs) and body actuation capabilities (including sidewinding gaits on limbless devices). By properly coordinating the body undulation and the leg placement, our framework combines the advantages of both limbless robots (modularity) and legged robots (mobility). We expect that our framework can provide general control schemes for the rapid deployment of general multi-legged robots, paving the ways toward machines that can traverse complex environments under real-life conditions.
Autonomous Exploration Development Environment and the Planning Algorithms
Oct 27, 2021
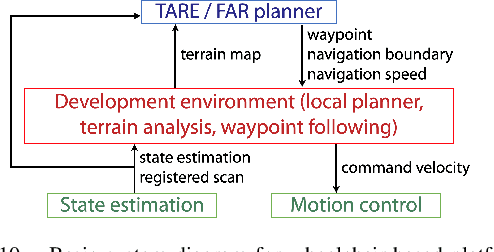
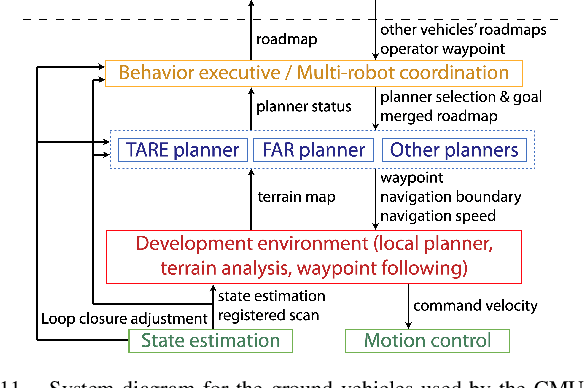
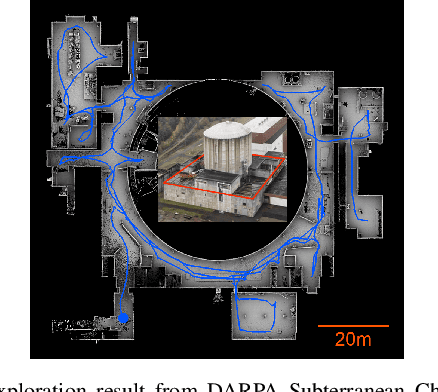
Autonomous Exploration Development Environment is an open-source repository released to facilitate the development of high-level planning algorithms and integration of complete autonomous navigation systems. The repository contains representative simulation environment models, fundamental navigation modules, e.g., local planner, terrain traversability analysis, waypoint following, and visualization tools. Together with two of our high-level planner releases -- TARE planner for exploration and FAR planner for route planning, we detail usage of the three open-source repositories and share experiences in the integration of autonomous navigation systems. We use DARPA Subterranean Challenge as a use case where the repositories together form the main navigation system of the CMU-OSU Team. In the end, we discuss a few potential use cases in extended applications.
Subdimensional Expansion Using Attention-Based Learning For Multi-Agent Path Finding
Sep 29, 2021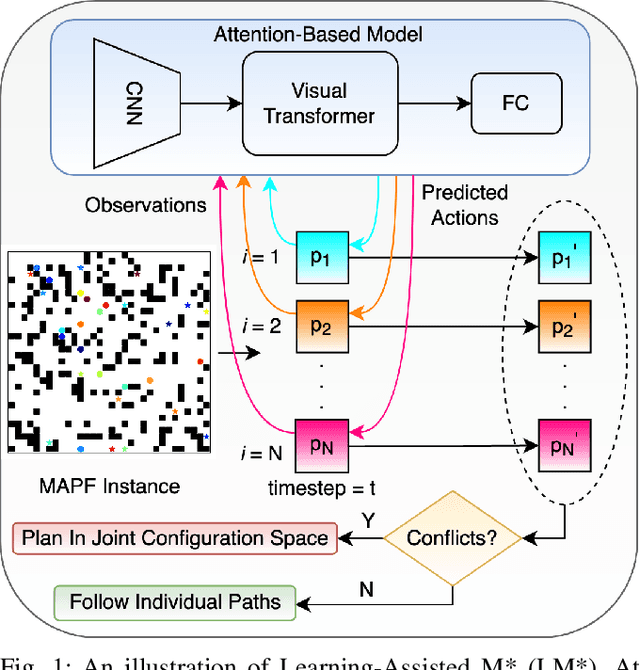
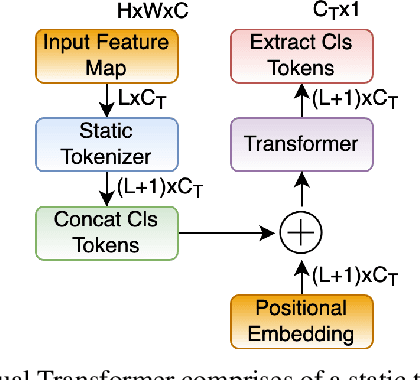
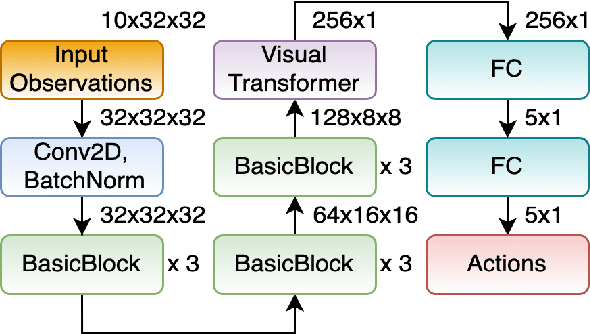
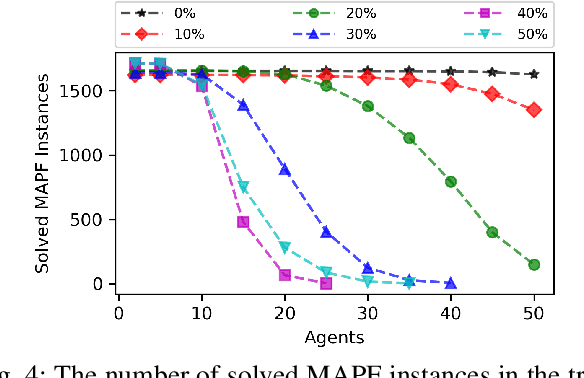
Multi-Agent Path Finding (MAPF) finds conflict-free paths for multiple agents from their respective start to goal locations. MAPF is challenging as the joint configuration space grows exponentially with respect to the number of agents. Among MAPF planners, search-based methods, such as CBS and M*, effectively bypass the curse of dimensionality by employing a dynamically-coupled strategy: agents are planned in a fully decoupled manner at first, where potential conflicts between agents are ignored; and then agents either follow their individual plans or are coupled together for planning to resolve the conflicts between them. In general, the number of conflicts to be resolved decides the run time of these planners and most of the existing work focuses on how to efficiently resolve these conflicts. In this work, we take a different view and aim to reduce the number of conflicts (and thus improve the overall search efficiency) by improving each agent's individual plan. By leveraging a Visual Transformer, we develop a learning-based single-agent planner, which plans for a single agent while paying attention to both the structure of the map and other agents with whom conflicts may happen. We then develop a novel multi-agent planner called LM* by integrating this learning-based single-agent planner with M*. Our results show that for both "seen" and "unseen" maps, in comparison with M*, LM* has fewer conflicts to be resolved and thus, runs faster and enjoys higher success rates. We empirically show that MAPF solutions computed by LM* are near-optimal. Our code is available at https://github.com/lakshayvirmani/learning-assisted-mstar .
The Geometric Structure of Externally Actuated Planar Locomoting Systems in Ambient Media
Aug 14, 2021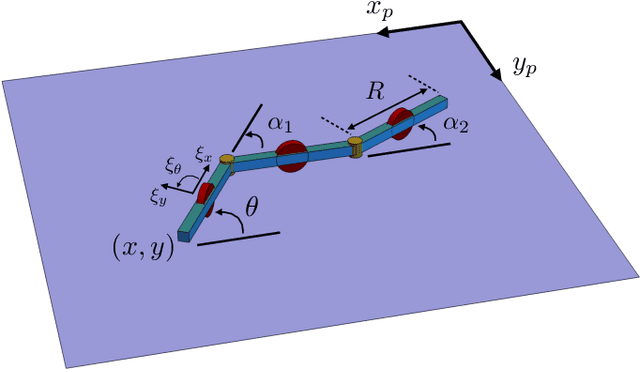
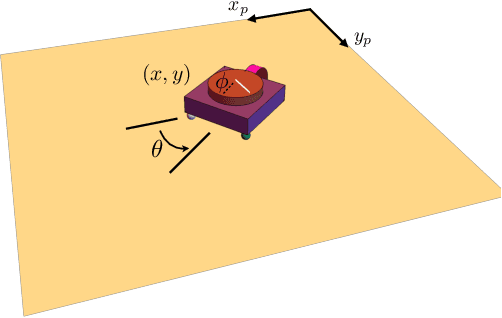
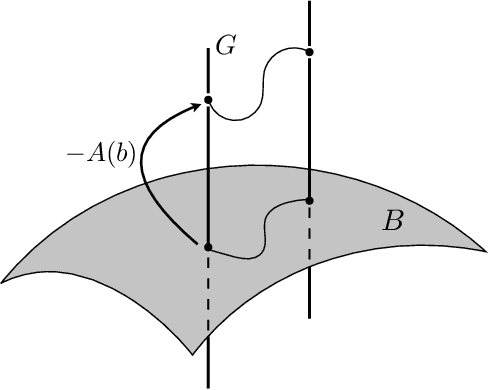
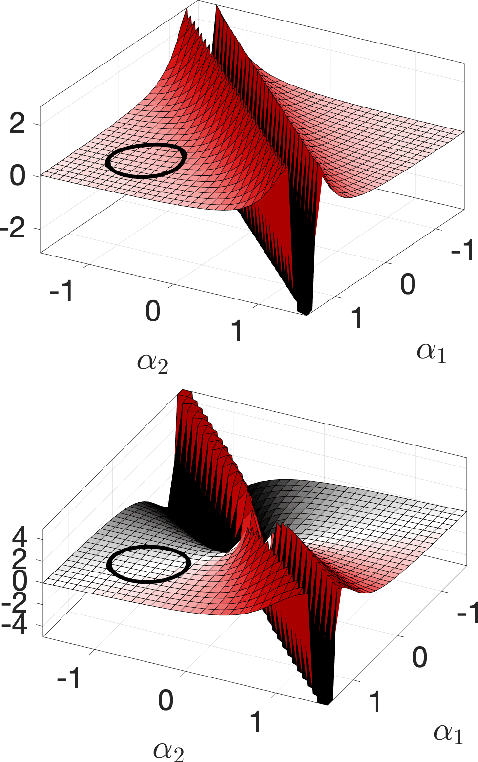
Robots often interact with the world via attached parts such as wheels, joints, or appendages. In many systems, these interactions, and the manner in which they lead to locomotion, can be understood using the machinery of geometric mechanics, explaining how inputs in the shape space of a robot affect motion in its configuration space and the configuration space of its environment. In this paper we consider an opposite type of locomotion, wherein robots are influenced actively by interactions with an externally forced ambient medium. We investigate two examples of externally actuated systems; one for which locomotion is governed by a principal connection, and is usually considered to possess no drift dynamics, and another for which no such connection exists, with drift inherent in its locomotion. For the driftless system, we develop geometric tools based on previously understood internally actuated versions of the system and demonstrate their use for motion planning under external actuation. For the system possessing drift, we employ nonholonomic reduction to obtain a reduced representation of the system dynamics, illustrate geometric features conducive to studying locomotion, and derive strategies for external actuation.
Multi-objective Conflict-based Search Using Safe-interval Path Planning
Aug 02, 2021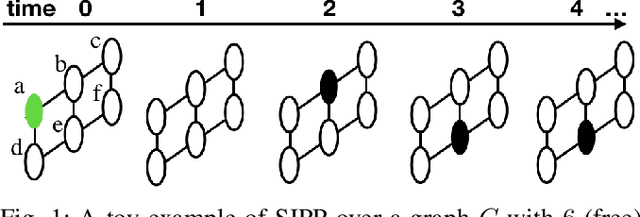
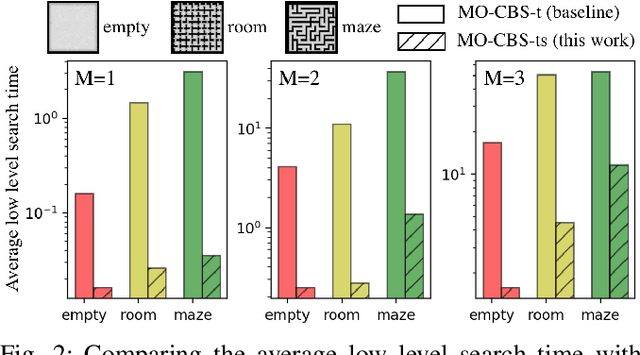
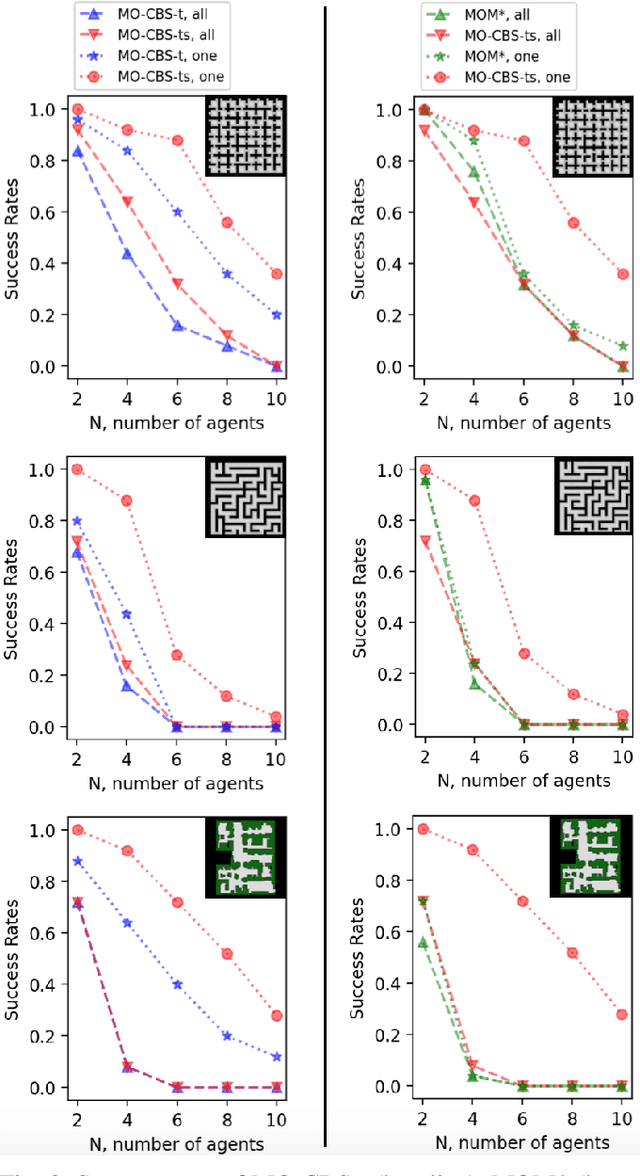
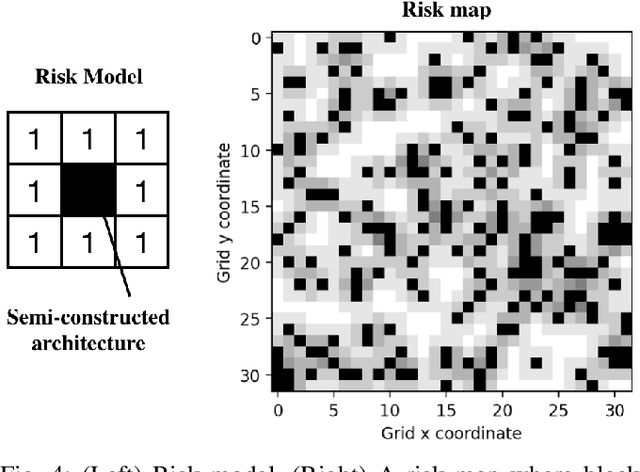
This paper addresses a generalization of the well known multi-agent path finding (MAPF) problem that optimizes multiple conflicting objectives simultaneously such as travel time and path risk. This generalization, referred to as multi-objective MAPF (MOMAPF), arises in several applications ranging from hazardous material transportation to construction site planning. In this paper, we present a new multi-objective conflict-based search (MO-CBS) approach that relies on a novel multi-objective safe interval path planning (MO-SIPP) algorithm for its low-level search. We first develop the MO-SIPP algorithm, show its properties and then embed it in MO-CBS. We present extensive numerical results to show that (1) there is an order of magnitude improvement in the average low level search time, and (2) a significant improvement in the success rates of finding the Pareto-optimal front can be obtained using the proposed approach in comparison with the state of the art. Finally, we also provide a case study to demonstrate the potential application of the proposed algorithms for construction site planning.
Multi-Objective Path-Based D* Lite
Aug 02, 2021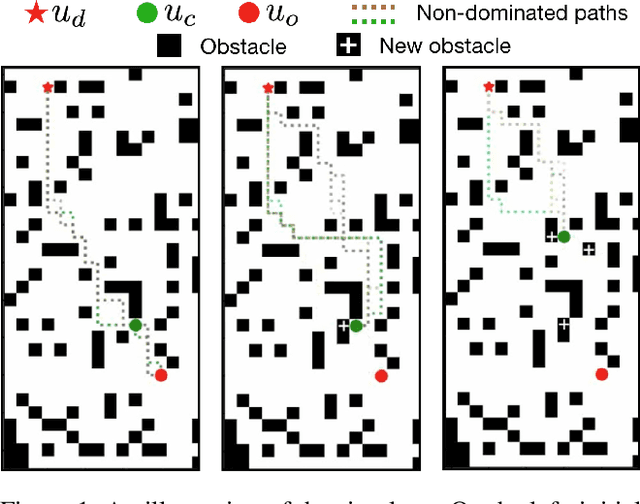
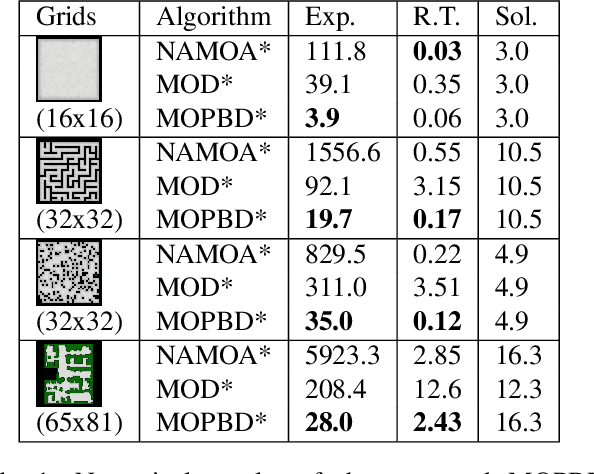
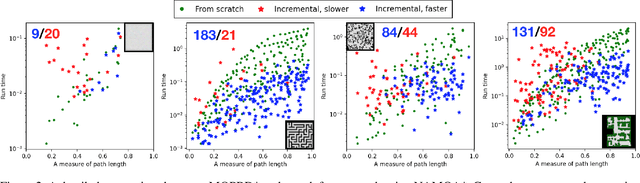
Incremental graph search algorithms, such as D* Lite, reuse previous search efforts to speed up subsequent similar path planning tasks. These algorithms have demonstrated their efficiency in comparison with search from scratch, and have been leveraged in many applications such as navigation in unknown terrain. On the other hand, path planning typically involves optimizing multiple conflicting objectives simultaneously, such as travel risk, arrival time, etc. Multi-objective path planning is challenging as the number of "Pareto-optimal" solutions can grow exponentially with respect to the size of the graph, which makes it computationally burdensome to plan from scratch each time when similar planning tasks needs to be solved. This article presents a new multi-objective incremental search algorithm called Multi-Objective Path-Based D* Lite (MOPBD*) which reuses previous search efforts to speed up subsequent planning tasks while optimizing multiple objectives. Numerical results show that MOPBD* is more efficient than search from scratch and runs an order of magnitude faster than existing incremental method for multi-objective path planning.