 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANGO: A Benchmark for Evaluating Mapping and Navigation Abilities of Large Language Models
Mar 29, 2024



Large language models such as ChatGPT and GPT-4 have recently achieved astonishing performance on a variety of natural language processing tasks. In this paper, we propose MANGO, a benchmark to evaluate their capabilities to perform text-based mapping and navigation. Our benchmark includes 53 mazes taken from a suite of textgames: each maze is paired with a walkthrough that visits every location but does not cover all possible paths. The task is question-answering: for each maze, a large language model reads the walkthrough and answers hundreds of mapping and navigation questions such as "How should you go to Attic from West of House?" and "Where are we if we go north and east from Cellar?". Although these questions are easy to humans, it turns out that even GPT-4, the best-to-date language model, performs poorly at answering them. Further, our experiments suggest that a strong mapping and navigation ability would benefit large language models in performing relevant downstream tasks, such as playing textgames. Our MANGO benchmark will facilitate future research on methods that improve the mapping and navigation capabilities of language models. We host our leaderboard, data, code, and evaluation program at https://mango.ttic.edu and https://github.com/oaklight/mango/.
WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
Aug 30, 2023



We present WeaverBird, an intelligent dialogue system designed specifically for the finance domain. Our system harnesses a large language model of GPT architecture that has been tuned using extensive corpora of finance-related text. As a result, our system possesses the capability to understand complex financial queries, such as "How should I manage my investments during inflation?", and provide informed responses. Furthermore, our system incorporates a local knowledge base and a search engine to retrieve relevant information. The final responses are conditioned on the search results and include proper citations to the sources, thus enjoying an enhanced credibility. Through a range of finance-related questions, we have demonstrated the superior performance of our system compared to other models. To experience our system firsthand, users can interact with our live demo at https://weaverbird.ttic.edu, as well as watch our 2-min video illustration at https://www.youtube.com/watch?v=fyV2qQkX6Tc.
EasyTPP: Towards Open Benchmarking the Temporal Point Processes
Jul 16, 2023Continuous-time event sequences play a vital role in real-world domains such as healthcare, finance, online shopping, social networks, and so on. To model such data, temporal point processes (TPPs) have emerged as the most advanced generative models, making a significant impact in both academic and application communities. Despite the emergence of many powerful models in recent years, there is still no comprehensive benchmark to evaluate them. This lack of standardization impedes researchers and practitioners from comparing methods and reproducing results, potentially slowing down progress in this field. In this paper, we present EasyTPP, which aims to establish a central benchmark for evaluating TPPs. Compared to previous work that also contributed datasets, our EasyTPP has three unique contributions to the community: (i) a comprehensive implementation of eight highly cited neural TPPs with the integration of commonly used evaluation metrics and datasets; (ii) a standardized benchmarking pipeline for a transparent and thorough comparison of different methods on different datasets; (iii) a universal framework supporting multiple ML libraries (e.g., PyTorch and TensorFlow) as well as custom implementations. Our benchmark is open-sourced: all the data and implementation can be found at this \href{https://github.com/ant-research/EasyTemporalPointProcess}{\textcolor{blue}{Github repository}}\footnote{\url{https://github.com/ant-research/EasyTemporalPointProcess}.}. We will actively maintain this benchmark and welcome contributions from other researchers and practitioners. Our benchmark will help promote reproducible research in this field, thus accelerating research progress as well as making more significant real-world impacts.
Statler: State-Maintaining Language Models for Embodied Reasoning
Jul 03, 2023



Large language models (LLMs) provide a promising tool that enable robots to perform complex robot reasoning tasks. However, the limited context window of contemporary LLMs makes reasoning over long time horizons difficult. Embodied tasks such as those that one might expect a household robot to perform typically require that the planner consider information acquired a long time ago (e.g., properties of the many objects that the robot previously encountered in the environment). Attempts to capture the world state using an LLM's implicit internal representation is complicated by the paucity of task- and environment-relevant information available in a robot's action history, while methods that rely on the ability to convey information via the prompt to the LLM are subject to its limited context window. In this paper, we propose Statler, a framework that endows LLMs with an explicit representation of the world state as a form of ``memory'' that is maintained over time. Integral to Statler is its use of two instances of general LLMs -- a world-model reader and a world-model writer -- that interface with and maintain the world state. By providing access to this world state ``memory'', Statler improves the ability of existing LLMs to reason over longer time horizons without the constraint of context length. We evaluate the effectiveness of our approach on three simulated table-top manipulation domains and a real robot domain, and show that it improves the state-of-the-art in LLM-based robot reasoning. Project website: https://statler-lm.github.io/
Language Models Can Improve Event Prediction by Few-Shot Abductive Reasoning
May 26, 2023Large language models have shown astonishing performance on a wide range of reasoning tasks. In this paper, we investigate whether they could reason about real-world events and help improve the prediction accuracy of event sequence models. We design a modeling and prediction framework where a large language model performs abductive reasoning to assist an event sequence model: the event model proposes predictions on future events given the past; instructed by a few expert-annotated demonstrations, the language model learns to suggest possible causes for each proposal; a search module finds out the previous events that match the causes; a scoring function learns to examine whether the retrieved events could actually cause the proposal. Through extensive experiments on two challenging real-world datasets (Amazon Review and GDELT), we demonstrate that our framework -- thanks to the reasoning ability of language models -- could significantly outperform the state-of-the-art event sequence models.
Autoregressive Modeling with Lookahead Attention
May 20, 2023To predict the next token, autoregressive models ordinarily examine the past. Could they also benefit from also examining hypothetical futures? We consider a novel Transformer-based autoregressive architecture that estimates the next-token distribution by extrapolating multiple continuations of the past, according to some proposal distribution, and attending to these extended strings. This architecture draws insights from classical AI systems such as board game players: when making a local decision, a policy may benefit from exploring possible future trajectories and analyzing them. On multiple tasks including morphological inflection and Boolean satisfiability, our lookahead model is able to outperform the ordinary Transformer model of comparable size. However, on some tasks, it appears to be benefiting from the extra computation without actually using the lookahead information. We discuss possible variant architectures as well as future speedups.
Can Large Language Models Play Text Games Well? Current State-of-the-Art and Open Questions
Apr 06, 2023Large language models (LLMs) such as ChatGPT and GPT-4 have recently demonstrated their remarkable abilities of communicating with human users. In this technical report, we take an initiative to investigate their capacities of playing text games, in which a player has to understand the environment and respond to situations by having dialogues with the game world. Our experiments show that ChatGPT performs competitively compared to all the existing systems but still exhibits a low level of intelligence. Precisely, ChatGPT can not construct the world model by playing the game or even reading the game manual; it may fail to leverage the world knowledge that it already has; it cannot infer the goal of each step as the game progresses. Our results open up new research questions at the intersection of artificial intelligence, machine learning, and natural language processing.
Explicit Planning Helps Language Models in Logical Reasoning
Mar 28, 2023



Language models have been shown to perform remarkably well on a wide range of natural language processing tasks. In this paper, we propose a novel system that uses language models to perform multi-step logical reasoning. Our system incorporates explicit planning into its inference procedure, thus able to make more informed reasoning decisions at each step by looking ahead into their future effects. In our experiments, our full system significantly outperforms other competing systems. On a multiple-choice question answering task, our system performs competitively compared to GPT-3-davinci despite having only around 1.5B parameters. We conduct several ablation studies to demonstrate that explicit planning plays a crucial role in the system's performance.
Hidden State Variability of Pretrained Language Models Can Guide Computation Reduction for Transfer Learning
Oct 19, 2022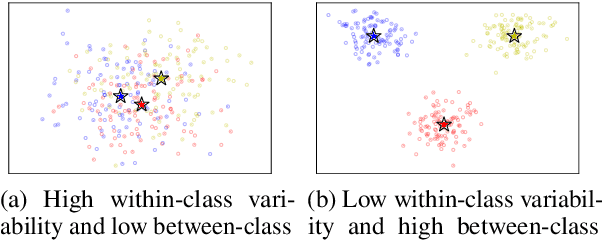
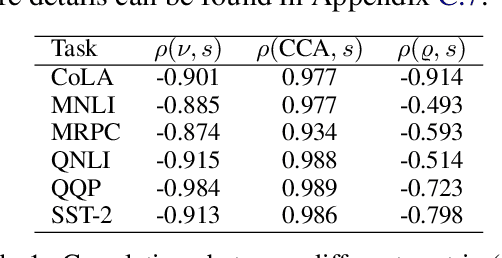
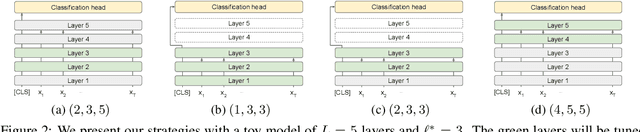
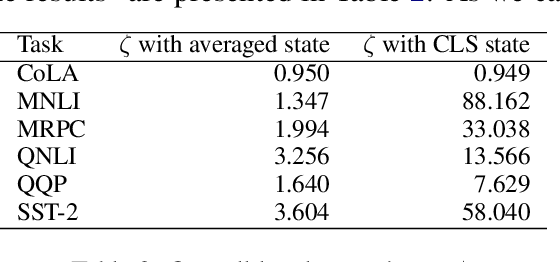
While transferring a pretrained language model, common approaches conventionally attach their task-specific classifiers to the top layer and adapt all the pretrained layers. We investigate whether one could make a task-specific selection on which subset of the layers to adapt and where to place the classifier. The goal is to reduce the computation cost of transfer learning methods (e.g. fine-tuning or adapter-tuning) without sacrificing its performance. We propose to select layers based on the variability of their hidden states given a task-specific corpus. We say a layer is already "well-specialized" in a task if the within-class variability of its hidden states is low relative to the between-class variability. Our variability metric is cheap to compute and doesn't need any training or hyperparameter tuning. It is robust to data imbalance and data scarcity. Extensive experiments on the GLUE benchmark demonstrate that selecting layers based on our metric can yield significantly stronger performance than using the same number of top layers and often match the performance of fine-tuning or adapter-tuning the entire language model.
HYPRO: A Hybridly Normalized Probabilistic Model for Long-Horizon Prediction of Event Sequences
Oct 04, 2022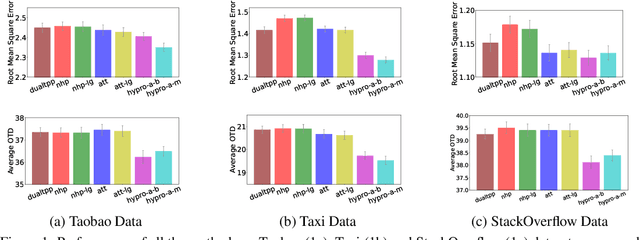

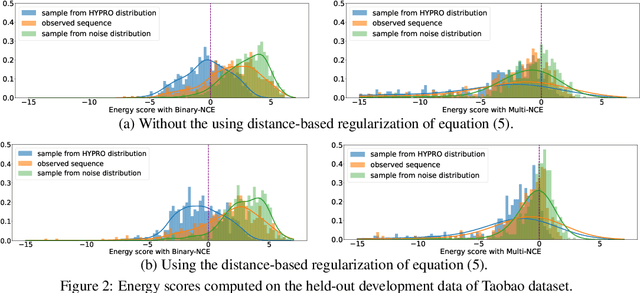
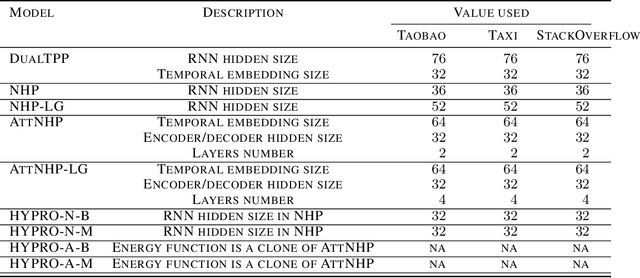
In this paper, we tackle the important yet under-investigated problem of making long-horizon prediction of event sequences. Existing state-of-the-art models do not perform well at this task due to their autoregressive structure. We propose HYPRO, a hybridly normalized probabilistic model that naturally fits this task: its first part is an autoregressive base model that learns to propose predictions; its second part is an energy function that learns to reweight the proposals such that more realistic predictions end up with higher probabilities. We also propose efficient training and inference algorithms for this model. Experiments on multiple real-world datasets demonstrate that our proposed HYPRO model can significantly outperform previous models at making long-horizon predictions of future events. We also conduct a range of ablation studies to investigate the effectiveness of each component of our proposed methods.