 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-CAISR: Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation
Feb 09, 2026Sequential recommendation (SR) aims to predict a user's next action by learning from their historical interaction sequences. In real-world applications, these models require periodic updates to adapt to new interactions and evolving user preferences. While incremental learning methods facilitate these updates, they face significant challenges. Replay-based approaches incur high memory and computational costs, and regularization-based methods often struggle to discard outdated or conflicting knowledge. To overcome these challenges, we propose SA-CAISR, a Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation framework. As a buffer-free framework, SA-CAISR operates using only the old model and new data, directly addressing the high costs of replay-based techniques. SA-CAISR introduces a novel Fisher-weighted knowledge-screening mechanism that dynamically identifies outdated knowledge by estimating parameter-level conflicts between the old model and new data, allowing our approach to selectively remove obsolete knowledge while preserving compatible historical patterns. This dynamic balance between stability and adaptability allows our method to achieve a new state-of-the-art performance in incremental SR. Specifically, SA-CAISR improves Recall@20 by 2.0%, MRR@20 by 1.2%, and NDCG@20 by 1.4% on average across datasets, while reducing memory usage by 97.5% and training time by 46.9% compared to the best baselines. This efficiency allows real-world systems to rapidly update user profiles with minimal computational overhead, ensuring more timely and accurate recommendations.
Wizard of Search Engine: Access to Information Through Conversations with Search Engines
May 18, 2021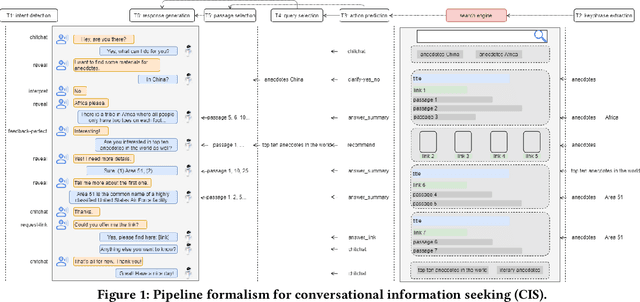

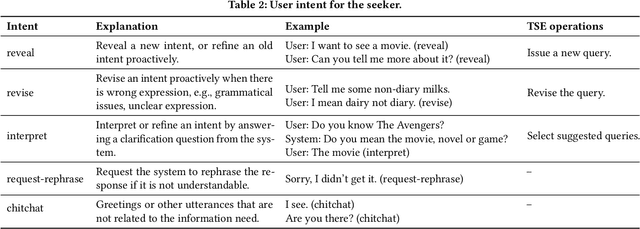
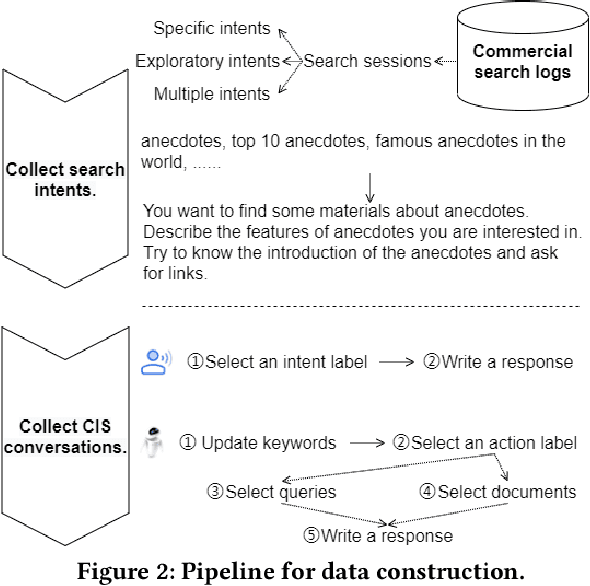
Conversational information seeking (CIS) is playing an increasingly important role in connecting people to information. Due to the lack of suitable resource, previous studies on CIS are limited to the study of theoretical/conceptual frameworks, laboratory-based user studies, or a particular aspect of CIS (e.g., asking clarifying questions). In this work, we make efforts to facilitate research on CIS from three aspects. (1) We formulate a pipeline for CIS with six sub-tasks: intent detection (ID), keyphrase extraction (KE), action prediction (AP), query selection (QS), passage selection (PS), and response generation (RG). (2) We release a benchmark dataset, called wizard of search engine (WISE), which allows for comprehensive and in-depth research on all aspects of CIS. (3) We design a neural architecture capable of training and evaluating both jointly and separately on the six sub-tasks, and devise a pre-train/fine-tune learning scheme, that can reduce the requirements of WISE in scale by making full use of available data. We report some useful characteristics of CIS based on statistics of WISE. We also show that our best performing model variant isable to achieve effective CIS as indicated by several metrics. We release the dataset, the code, as well as the evaluation scripts to facilitate future research by measuring further improvements in this important research direction.