 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-wise Contrastive Learning for Neural Dialogue Generation
Oct 13, 2020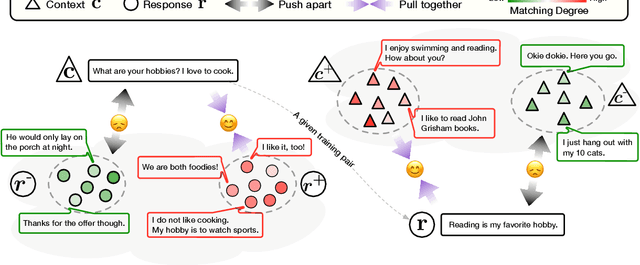
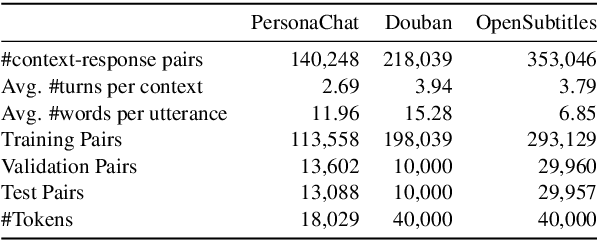
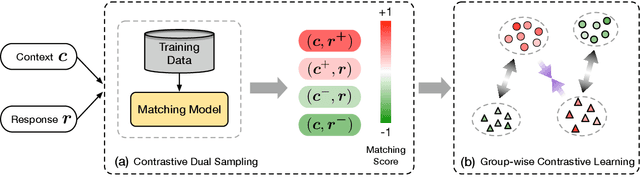
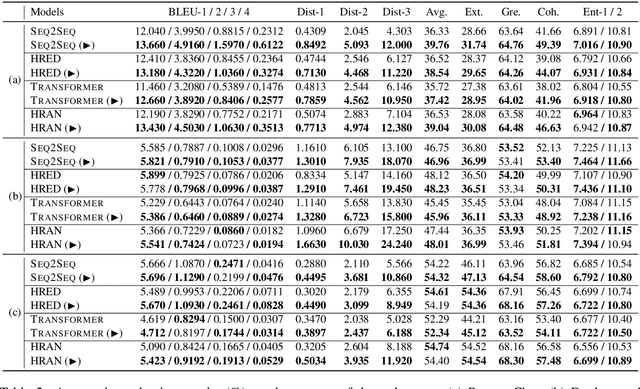
Neural dialogue response generation has gained much popularity in recent years. Maximum Likelihood Estimation (MLE) objective is widely adopted in existing dialogue model learning. However, models trained with MLE objective function are plagued by the low-diversity issue when it comes to the open-domain conversational setting. Inspired by the observation that humans not only learn from the positive signals but also benefit from correcting behaviors of undesirable actions, in this work, we introduce contrastive learning into dialogue generation, where the model explicitly perceives the difference between the well-chosen positive and negative utterances. Specifically, we employ a pretrained baseline model as a reference. During contrastive learning, the target dialogue model is trained to give higher conditional probabilities for the positive samples, and lower conditional probabilities for those negative samples, compared to the reference model. To manage the multi-mapping relations prevailed in human conversation, we augment contrastive dialogue learning with group-wise dual sampling. Extensive experimental results show that the proposed group-wise contrastive learning framework is suited for training a wide range of neural dialogue generation models with very favorable performance over the baseline training approaches.
Regularizing Dialogue Generation by Imitating Implicit Scenarios
Oct 06, 2020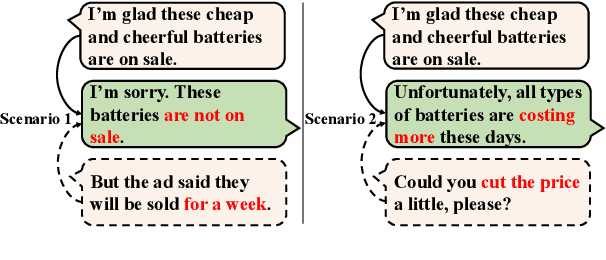
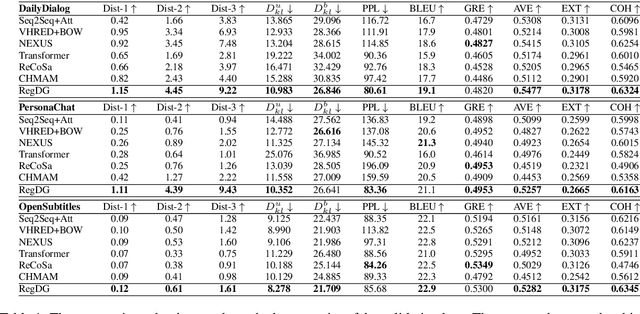
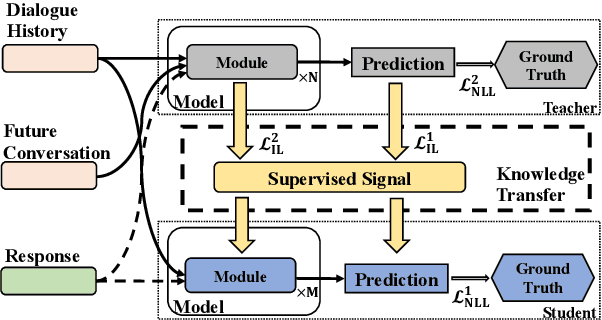
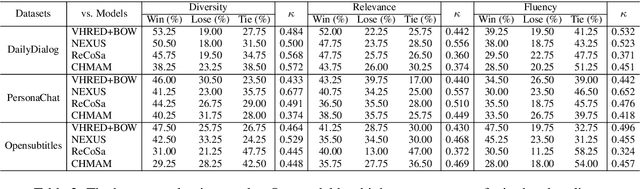
Human dialogues are scenario-based and appropriate responses generally relate to the latent context knowledge entailed by the specific scenario. To enable responses that are more meaningful and context-specific, we propose to improve generative dialogue systems from the scenario perspective, where both dialogue history and future conversation are taken into account to implicitly reconstruct the scenario knowledge. More importantly, the conversation scenarios are further internalized using imitation learning framework, where the conventional dialogue model that has no access to future conversations is effectively regularized by transferring the scenario knowledge contained in hierarchical supervising signals from the scenario-based dialogue model, so that the future conversation is not required in actual inference. Extensive evaluations show that our approach significantly outperforms state-of-the-art baselines on diversity and relevance, and expresses scenario-specific knowledge.
Modeling Topical Relevance for Multi-Turn Dialogue Generation
Sep 27, 2020
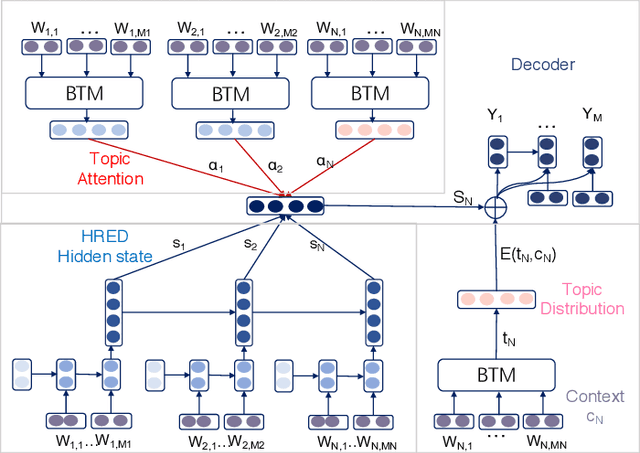
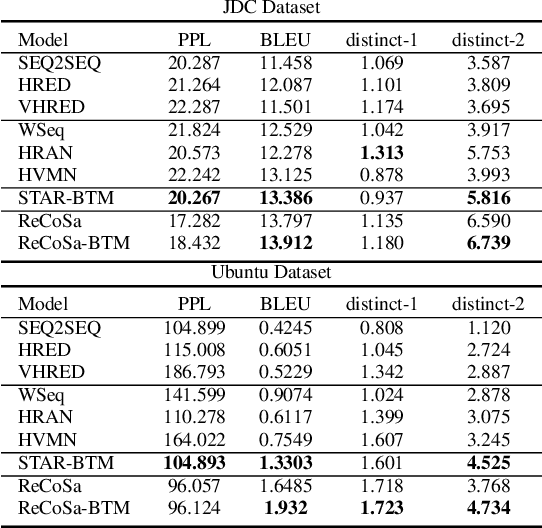
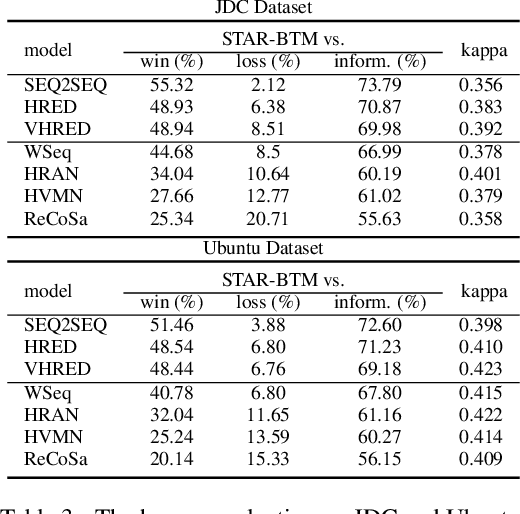
Topic drift is a common phenomenon in multi-turn dialogue. Therefore, an ideal dialogue generation models should be able to capture the topic information of each context, detect the relevant context, and produce appropriate responses accordingly. However, existing models usually use word or sentence level similarities to detect the relevant contexts, which fail to well capture the topical level relevance. In this paper, we propose a new model, named STAR-BTM, to tackle this problem. Firstly, the Biterm Topic Model is pre-trained on the whole training dataset. Then, the topic level attention weights are computed based on the topic representation of each context. Finally, the attention weights and the topic distribution are utilized in the decoding process to generate the corresponding responses. Experimental results on both Chinese customer services data and English Ubuntu dialogue data show that STAR-BTM significantly outperforms several state-of-the-art methods, in terms of both metric-based and human evaluations.
Collaborative Group Learning
Sep 16, 2020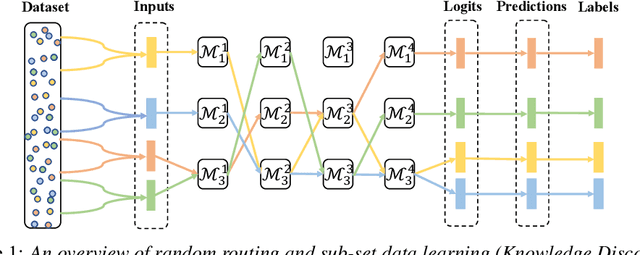


Collaborative learning has successfully applied knowledge transfer to guiding a pool of small student networks towards robust local minima. However, previous approaches typically struggle with drastically aggravated student homogenization and rapidly growing computational complexity when the number of students rises. In this paper, we propose Collaborative Group Learning, an efficient framework that aims to maximize student population without sacrificing generalization performance and computational efficiency. First, each student is established by randomly routing on a modular neural network, which is not only parameter-efficient but also facilitates flexible knowledge communication between students due to random levels of representation sharing and branching. Second, to resist homogenization and further reduce the computational cost, students first compose diverse feature sets by exploiting the inductive bias from sub-sets of training data, and then aggregate and distill supplementary knowledge by choosing a random sub-group of students at each time step. Empirical evaluations on both image and text tasks indicate that our method significantly outperforms various state-of-the-art collaborative approaches whilst enhancing computational efficiency.
Data Manipulation: Towards Effective Instance Learning for Neural Dialogue Generation via Learning to Augment and Reweight
Apr 07, 2020
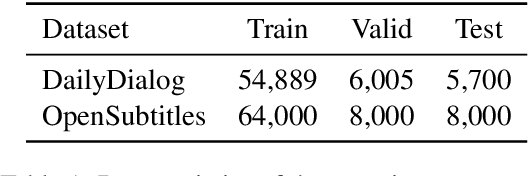
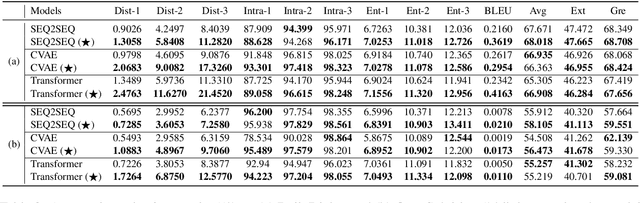
Current state-of-the-art neural dialogue models learn from human conversations following the data-driven paradigm. As such, a reliable training corpus is the crux of building a robust and well-behaved dialogue model. However, due to the open-ended nature of human conversations, the quality of user-generated training data varies greatly, and effective training samples are typically insufficient while noisy samples frequently appear. This impedes the learning of those data-driven neural dialogue models. Therefore, effective dialogue learning requires not only more reliable learning samples, but also fewer noisy samples. In this paper, we propose a data manipulation framework to proactively reshape the data distribution towards reliable samples by augmenting and highlighting effective learning samples as well as reducing the effect of inefficient samples simultaneously. In particular, the data manipulation model selectively augments the training samples and assigns an importance weight to each instance to reform the training data. Note that, the proposed data manipulation framework is fully data-driven and learnable. It not only manipulates training samples to optimize the dialogue generation model, but also learns to increase its manipulation skills through gradient descent with validation samples. Extensive experiments show that our framework can improve the dialogue generation performance with respect to 13 automatic evaluation metrics and human judgments.
Learning from Easy to Complex: Adaptive Multi-curricula Learning for Neural Dialogue Generation
Mar 16, 2020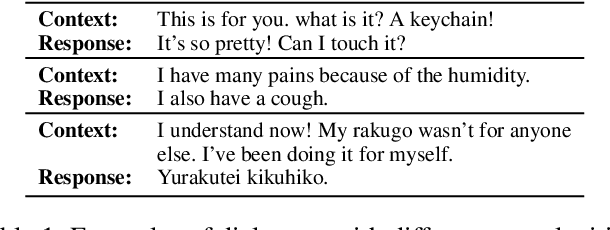
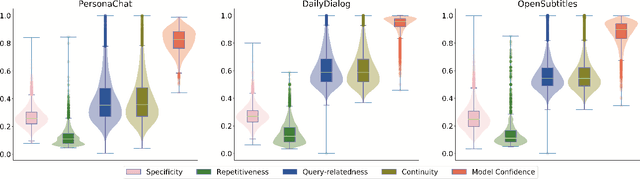
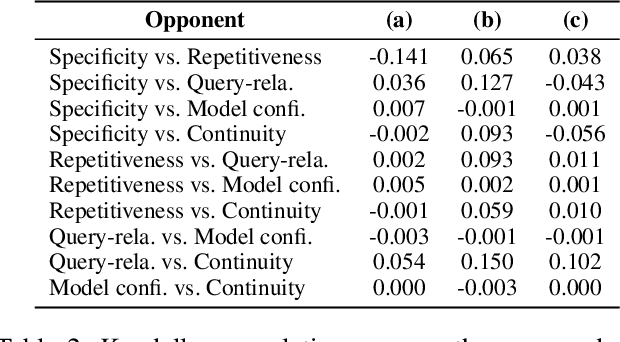
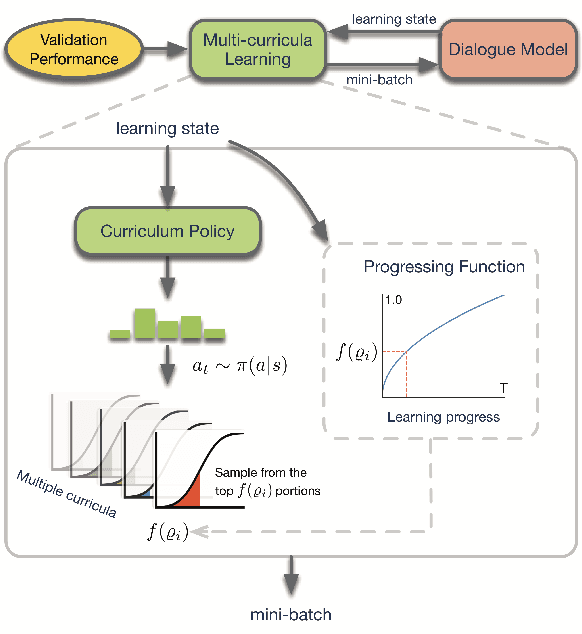
Current state-of-the-art neural dialogue systems are mainly data-driven and are trained on human-generated responses. However, due to the subjectivity and open-ended nature of human conversations, the complexity of training dialogues varies greatly. The noise and uneven complexity of query-response pairs impede the learning efficiency and effects of the neural dialogue generation models. What is more, so far, there are no unified dialogue complexity measurements, and the dialogue complexity embodies multiple aspects of attributes---specificity, repetitiveness, relevance, etc. Inspired by human behaviors of learning to converse, where children learn from easy dialogues to complex ones and dynamically adjust their learning progress, in this paper, we first analyze five dialogue attributes to measure the dialogue complexity in multiple perspectives on three publicly available corpora. Then, we propose an adaptive multi-curricula learning framework to schedule a committee of the organized curricula. The framework is established upon the reinforcement learning paradigm, which automatically chooses different curricula at the evolving learning process according to the learning status of the neural dialogue generation model. Extensive experiments conducted on five state-of-the-art models demonstrate its learning efficiency and effectiveness with respect to 13 automatic evaluation metrics and human judgments.
Posterior-GAN: Towards Informative and Coherent Response Generation with Posterior Generative Adversarial Network
Mar 04, 2020
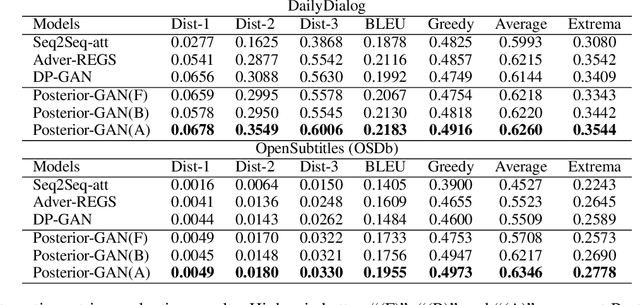

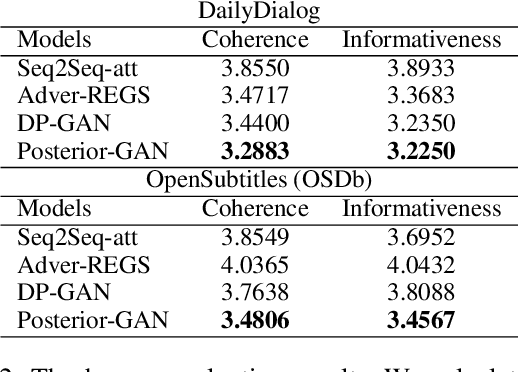
Neural conversational models learn to generate responses by taking into account the dialog history. These models are typically optimized over the query-response pairs with a maximum likelihood estimation objective. However, the query-response tuples are naturally loosely coupled, and there exist multiple responses that can respond to a given query, which leads the conversational model learning burdensome. Besides, the general dull response problem is even worsened when the model is confronted with meaningless response training instances. Intuitively, a high-quality response not only responds to the given query but also links up to the future conversations, in this paper, we leverage the query-response-future turn triples to induce the generated responses that consider both the given context and the future conversations. To facilitate the modeling of these triples, we further propose a novel encoder-decoder based generative adversarial learning framework, Posterior Generative Adversarial Network (Posterior-GAN), which consists of a forward and a backward generative discriminator to cooperatively encourage the generated response to be informative and coherent by two complementary assessment perspectives. Experimental results demonstrate that our method effectively boosts the informativeness and coherence of the generated response on both automatic and human evaluation, which verifies the advantages of considering two assessment perspectives.
Adaptive Parameterization for Neural Dialogue Generation
Jan 18, 2020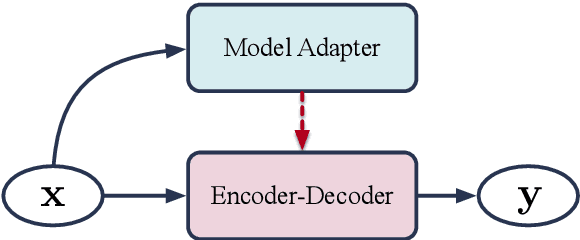
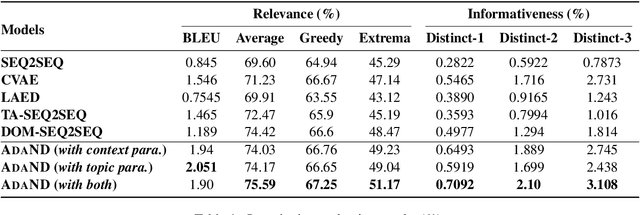
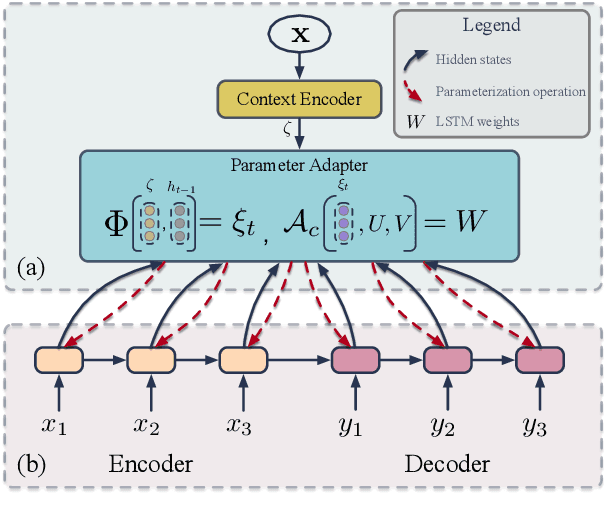
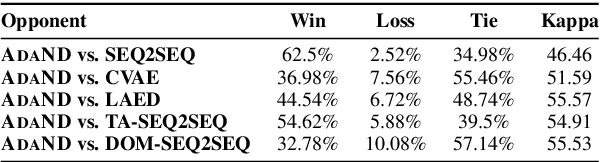
Neural conversation systems generate responses based on the sequence-to-sequence (SEQ2SEQ) paradigm. Typically, the model is equipped with a single set of learned parameters to generate responses for given input contexts. When confronting diverse conversations, its adaptability is rather limited and the model is hence prone to generate generic responses. In this work, we propose an {\bf Ada}ptive {\bf N}eural {\bf D}ialogue generation model, \textsc{AdaND}, which manages various conversations with conversation-specific parameterization. For each conversation, the model generates parameters of the encoder-decoder by referring to the input context. In particular, we propose two adaptive parameterization mechanisms: a context-aware and a topic-aware parameterization mechanism. The context-aware parameterization directly generates the parameters by capturing local semantics of the given context. The topic-aware parameterization enables parameter sharing among conversations with similar topics by first inferring the latent topics of the given context and then generating the parameters with respect to the distributional topics. Extensive experiments conducted on a large-scale real-world conversational dataset show that our model achieves superior performance in terms of both quantitative metrics and human evaluations.
EmpGAN: Multi-resolution Interactive Empathetic Dialogue Generation
Nov 20, 2019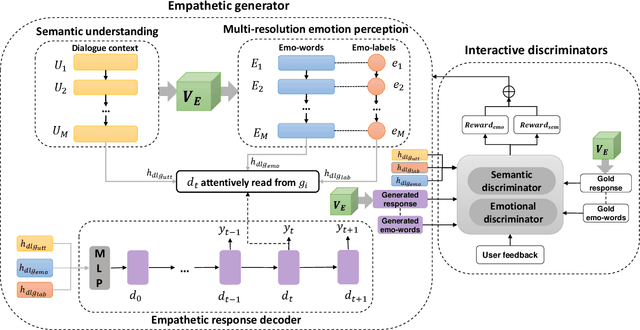
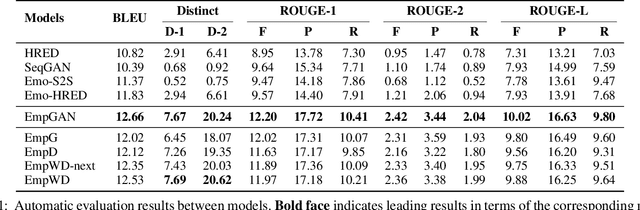
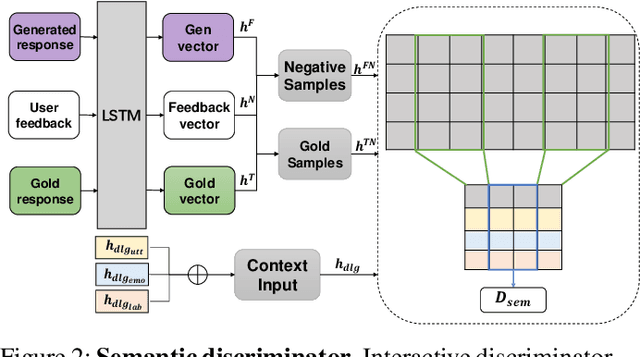
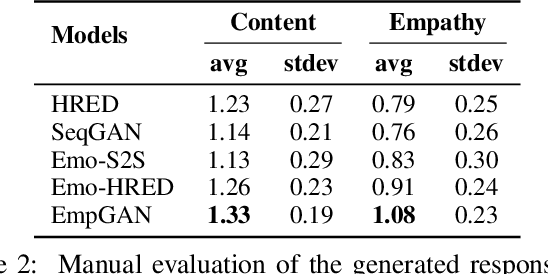
Conventional emotional dialogue system focuses on generating emotion-rich replies. Studies on emotional intelligence suggest that constructing a more empathetic dialogue system, which is sensitive to the users' expressed emotion, is a crucial step towards a more humanized human-machine conversation. However, obstacles to establishing such an empathetic conversational system are still far beyond current progress: 1) Simply considering the sentence-level emotions while neglecting the more precise token-level emotions may lead to insufficient emotion perceptivity. 2) Merely relying on the dialogue history but overlooking the potential of user feedback for the generated responses further aggravates the insufficient emotion perceptivity deficiencies. To address the above challenges, we propose the EmpGAN, a multi-resolution adversarial empathetic dialogue generation model to generate more appropriate and empathetic responses. To capture the nuances of user feelings sufficiently, EmpGAN generates responses by jointly taking both the coarse-grained sentence-level and fine-grained token-level emotions into account. Moreover, an interactive adversarial learning framework is introduced to further identify whether the generated responses evoke emotion perceptivity in dialogues regarding both the dialogue history and user feedback. Experiments show that our model outperforms the state-of-the-art baseline by a significant margin in terms of both content quality as well as the emotion perceptivity. In particular, the distinctiveness on the DailyDialog dataset is increased up to 129%.
Explicit State Tracking with Semi-Supervision for Neural Dialogue Generation
Aug 31, 2018
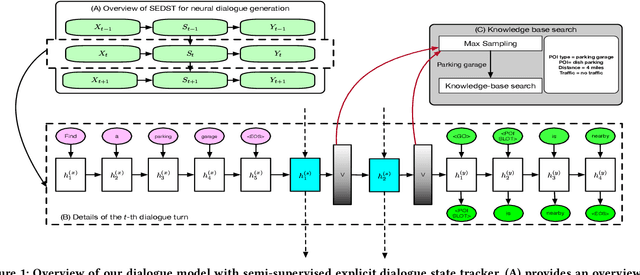
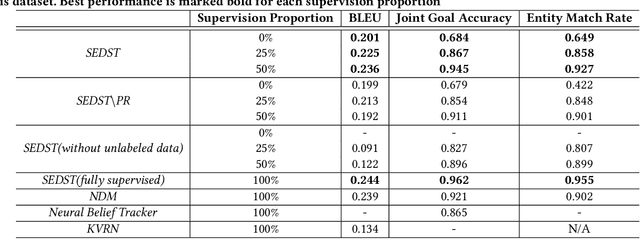
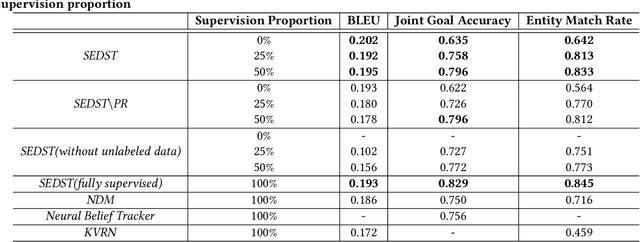
The task of dialogue generation aims to automatically provide responses given previous utterances. Tracking dialogue states is an important ingredient in dialogue generation for estimating users' intention. However, the \emph{expensive nature of state labeling} and the \emph{weak interpretability} make the dialogue state tracking a challenging problem for both task-oriented and non-task-oriented dialogue generation: For generating responses in task-oriented dialogues, state tracking is usually learned from manually annotated corpora, where the human annotation is expensive for training; for generating responses in non-task-oriented dialogues, most of existing work neglects the explicit state tracking due to the unlimited number of dialogue states. In this paper, we propose the \emph{semi-supervised explicit dialogue state tracker} (SEDST) for neural dialogue generation. To this end, our approach has two core ingredients: \emph{CopyFlowNet} and \emph{posterior regularization}. Specifically, we propose an encoder-decoder architecture, named \emph{CopyFlowNet}, to represent an explicit dialogue state with a probabilistic distribution over the vocabulary space. To optimize the training procedure, we apply a posterior regularization strategy to integrate indirect supervision. Extensive experiments conducted on both task-oriented and non-task-oriented dialogue corpora demonstrate the effectiveness of our proposed model. Moreover, we find that our proposed semi-supervised dialogue state tracker achieves a comparable performance as state-of-the-art supervised learning baselines in state tracking procedure.