 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-policy Learning for Multiple Loggers
Aug 05, 2019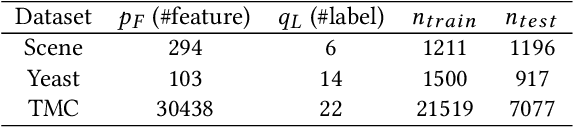
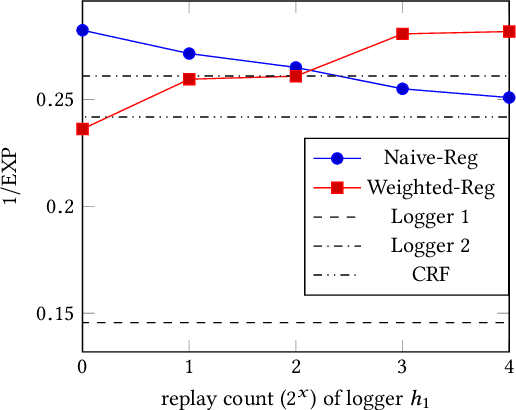
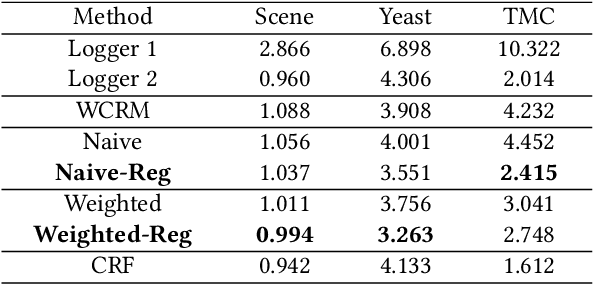
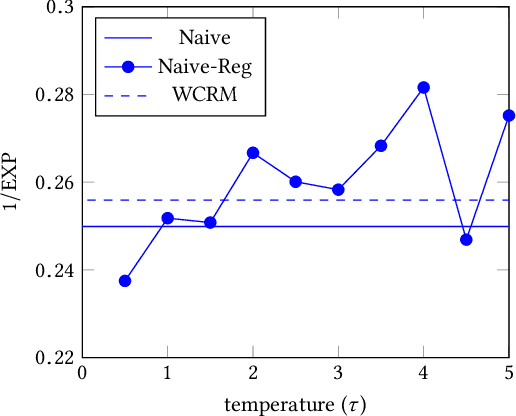
It is well known that the historical logs are used for evaluating and learning policies in interactive systems, e.g. recommendation, search, and online advertising. Since direct online policy learning usually harms user experiences, it is more crucial to apply off-policy learning in real-world applications instead. Though there have been some existing works, most are focusing on learning with one single historical policy. However, in practice, usually a number of parallel experiments, e.g. multiple AB tests, are performed simultaneously. To make full use of such historical data, learning policies from multiple loggers becomes necessary. Motivated by this, in this paper, we investigate off-policy learning when the training data coming from multiple historical policies. Specifically, policies, e.g. neural networks, can be learned directly from multi-logger data, with counterfactual estimators. In order to understand the generalization ability of such estimator better, we conduct generalization error analysis for the empirical risk minimization problem. We then introduce the generalization error bound as the new risk function, which can be reduced to a constrained optimization problem. Finally, we give the corresponding learning algorithm for the new constrained problem, where we can appeal to the minimax problems to control the constraints. Extensive experiments on benchmark datasets demonstrate that the proposed methods achieve better performances than the state-of-the-arts.
Explicit State Tracking with Semi-Supervision for Neural Dialogue Generation
Aug 31, 2018
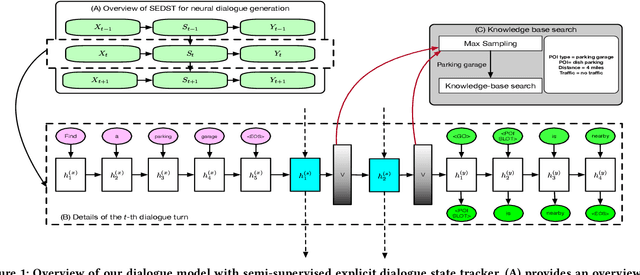
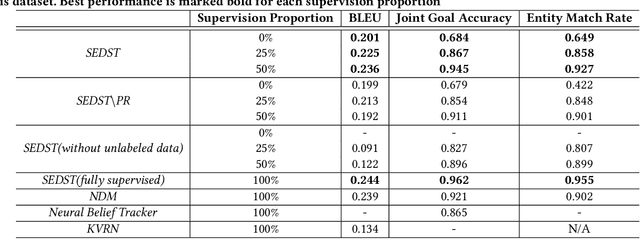
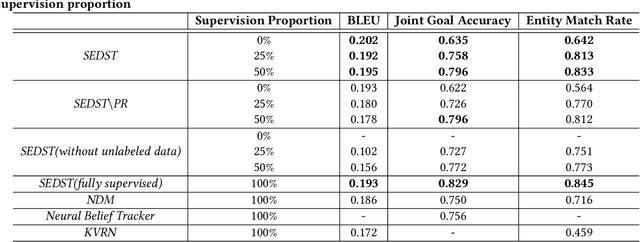
The task of dialogue generation aims to automatically provide responses given previous utterances. Tracking dialogue states is an important ingredient in dialogue generation for estimating users' intention. However, the \emph{expensive nature of state labeling} and the \emph{weak interpretability} make the dialogue state tracking a challenging problem for both task-oriented and non-task-oriented dialogue generation: For generating responses in task-oriented dialogues, state tracking is usually learned from manually annotated corpora, where the human annotation is expensive for training; for generating responses in non-task-oriented dialogues, most of existing work neglects the explicit state tracking due to the unlimited number of dialogue states. In this paper, we propose the \emph{semi-supervised explicit dialogue state tracker} (SEDST) for neural dialogue generation. To this end, our approach has two core ingredients: \emph{CopyFlowNet} and \emph{posterior regularization}. Specifically, we propose an encoder-decoder architecture, named \emph{CopyFlowNet}, to represent an explicit dialogue state with a probabilistic distribution over the vocabulary space. To optimize the training procedure, we apply a posterior regularization strategy to integrate indirect supervision. Extensive experiments conducted on both task-oriented and non-task-oriented dialogue corpora demonstrate the effectiveness of our proposed model. Moreover, we find that our proposed semi-supervised dialogue state tracker achieves a comparable performance as state-of-the-art supervised learning baselines in state tracking procedure.
Deep Reinforcement Learning for List-wise Recommendations
Jan 05, 2018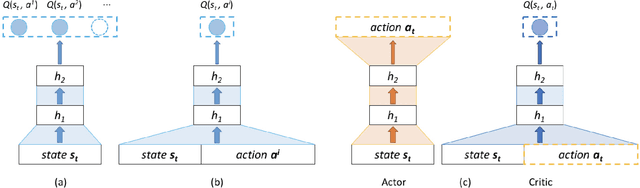
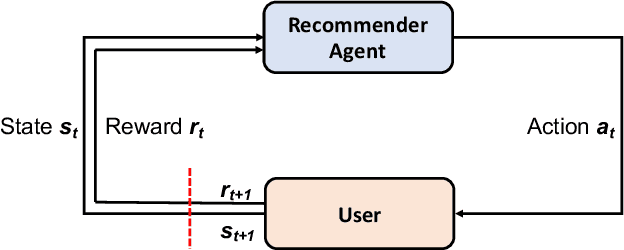
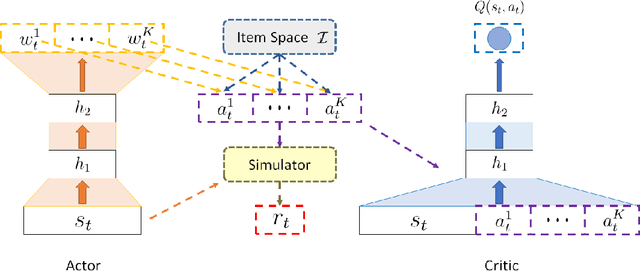
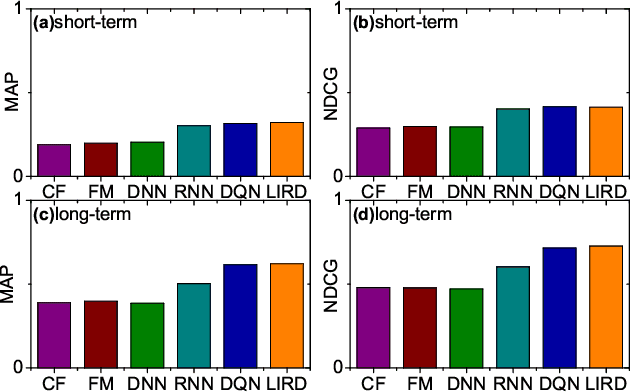
Recommender systems play a crucial role in mitigating the problem of information overload by suggesting users' personalized items or services. The vast majority of traditional recommender systems consider the recommendation procedure as a static process and make recommendations following a fixed strategy. In this paper, we propose a novel recommender system with the capability of continuously improving its strategies during the interactions with users. We model the sequential interactions between users and a recommender system as a Markov Decision Process (MDP) and leverage Reinforcement Learning (RL) to automatically learn the optimal strategies via recommending trial-and-error items and receiving reinforcements of these items from users' feedbacks. In particular, we introduce an online user-agent interacting environment simulator, which can pre-train and evaluate model parameters offline before applying the model online. Moreover, we validate the importance of list-wise recommendations during the interactions between users and agent, and develop a novel approach to incorporate them into the proposed framework LIRD for list-wide recommendations. The experimental results based on a real-world e-commerce dataset demonstrate the effectiveness of the proposed framework.