 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Dense Endoscopic Reconstruction with Gaussian Splatting-driven Surface Normal-aware Tracking and Mapping
Jan 31, 2025



Simultaneous Localization and Mapping (SLAM) is essential for precise surgical interventions and robotic tasks in minimally invasive procedures. While recent advancements in 3D Gaussian Splatting (3DGS) have improved SLAM with high-quality novel view synthesis and fast rendering, these systems struggle with accurate depth and surface reconstruction due to multi-view inconsistencies. Simply incorporating SLAM and 3DGS leads to mismatches between the reconstructed frames. In this work, we present Endo-2DTAM, a real-time endoscopic SLAM system with 2D Gaussian Splatting (2DGS) to address these challenges. Endo-2DTAM incorporates a surface normal-aware pipeline, which consists of tracking, mapping, and bundle adjustment modules for geometrically accurate reconstruction. Our robust tracking module combines point-to-point and point-to-plane distance metrics, while the mapping module utilizes normal consistency and depth distortion to enhance surface reconstruction quality. We also introduce a pose-consistent strategy for efficient and geometrically coherent keyframe sampling. Extensive experiments on public endoscopic datasets demonstrate that Endo-2DTAM achieves an RMSE of $1.87\pm 0.63$ mm for depth reconstruction of surgical scenes while maintaining computationally efficient tracking, high-quality visual appearance, and real-time rendering. Our code will be released at github.com/lastbasket/Endo-2DTAM.
EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
Jan 20, 2025



Recently, Multimodal Large Language Models (MLLMs) have demonstrated their immense potential in computer-aided diagnosis and decision-making. In the context of robotic-assisted surgery, MLLMs can serve as effective tools for surgical training and guidance. However, there is still a lack of MLLMs specialized for surgical scene understanding in clinical applications. In this work, we introduce EndoChat to address various dialogue paradigms and subtasks in surgical scene understanding that surgeons encounter. To train our EndoChat, we construct the Surg-396K dataset through a novel pipeline that systematically extracts surgical information and generates structured annotations based on collected large-scale endoscopic surgery datasets. Furthermore, we introduce a multi-scale visual token interaction mechanism and a visual contrast-based reasoning mechanism to enhance the model's representation learning and reasoning capabilities. Our model achieves state-of-the-art performance across five dialogue paradigms and eight surgical scene understanding tasks. Additionally, we conduct evaluations with professional surgeons, most of whom provide positive feedback on collaborating with EndoChat. Overall, these results demonstrate that our EndoChat has great potential to significantly advance training and automation in robotic-assisted surgery.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024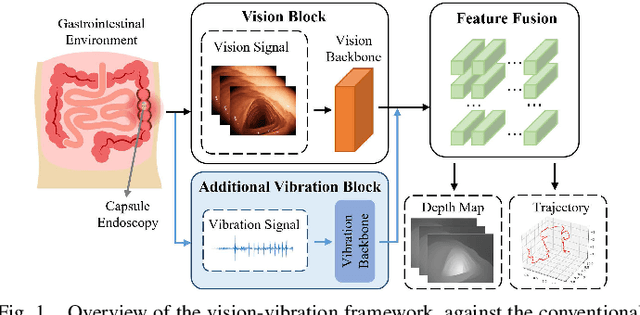
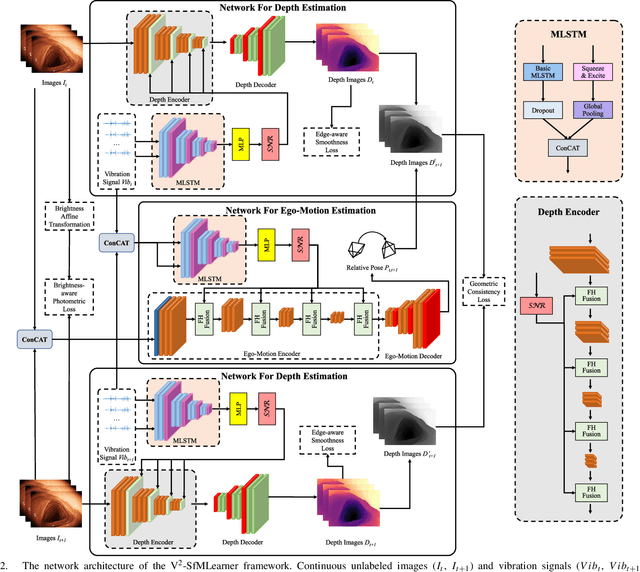
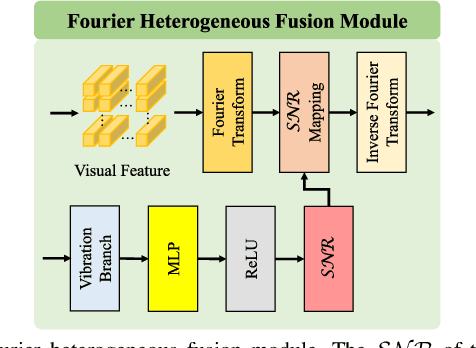
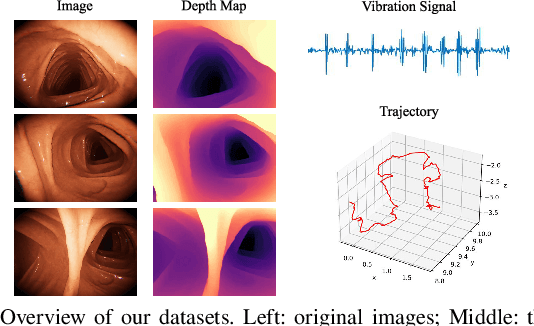
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
SurgSora: Decoupled RGBD-Flow Diffusion Model for Controllable Surgical Video Generation
Dec 18, 2024Medical video generation has transformative potential for enhancing surgical understanding and pathology insights through precise and controllable visual representations. However, current models face limitations in controllability and authenticity. To bridge this gap, we propose SurgSora, a motion-controllable surgical video generation framework that uses a single input frame and user-controllable motion cues. SurgSora consists of three key modules: the Dual Semantic Injector (DSI), which extracts object-relevant RGB and depth features from the input frame and integrates them with segmentation cues to capture detailed spatial features of complex anatomical structures; the Decoupled Flow Mapper (DFM), which fuses optical flow with semantic-RGB-D features at multiple scales to enhance temporal understanding and object spatial dynamics; and the Trajectory Controller (TC), which allows users to specify motion directions and estimates sparse optical flow, guiding the video generation process. The fused features are used as conditions for a frozen Stable Diffusion model to produce realistic, temporally coherent surgical videos. Extensive evaluations demonstrate that SurgSora outperforms state-of-the-art methods in controllability and authenticity, showing its potential to advance surgical video generation for medical education, training, and research.
ETSM: Automating Dissection Trajectory Suggestion and Confidence Map-Based Safety Margin Prediction for Robot-assisted Endoscopic Submucosal Dissection
Nov 28, 2024Robot-assisted Endoscopic Submucosal Dissection (ESD) improves the surgical procedure by providing a more comprehensive view through advanced robotic instruments and bimanual operation, thereby enhancing dissection efficiency and accuracy. Accurate prediction of dissection trajectories is crucial for better decision-making, reducing intraoperative errors, and improving surgical training. Nevertheless, predicting these trajectories is challenging due to variable tumor margins and dynamic visual conditions. To address this issue, we create the ESD Trajectory and Confidence Map-based Safety Margin (ETSM) dataset with $1849$ short clips, focusing on submucosal dissection with a dual-arm robotic system. We also introduce a framework that combines optimal dissection trajectory prediction with a confidence map-based safety margin, providing a more secure and intelligent decision-making tool to minimize surgical risks for ESD procedures. Additionally, we propose the Regression-based Confidence Map Prediction Network (RCMNet), which utilizes a regression approach to predict confidence maps for dissection areas, thereby delineating various levels of safety margins. We evaluate our RCMNet using three distinct experimental setups: in-domain evaluation, robustness assessment, and out-of-domain evaluation. Experimental results show that our approach excels in the confidence map-based safety margin prediction task, achieving a mean absolute error (MAE) of only $3.18$. To the best of our knowledge, this is the first study to apply a regression approach for visual guidance concerning delineating varying safety levels of dissection areas. Our approach bridges gaps in current research by improving prediction accuracy and enhancing the safety of the dissection process, showing great clinical significance in practice.
PDZSeg: Adapting the Foundation Model for Dissection Zone Segmentation with Visual Prompts in Robot-assisted Endoscopic Submucosal Dissection
Nov 27, 2024Purpose: Endoscopic surgical environments present challenges for dissection zone segmentation due to unclear boundaries between tissue types, leading to segmentation errors where models misidentify or overlook edges. This study aims to provide precise dissection zone suggestions during endoscopic submucosal dissection (ESD) procedures, enhancing ESD safety. Methods: We propose the Prompted-based Dissection Zone Segmentation (PDZSeg) model, designed to leverage diverse visual prompts such as scribbles and bounding boxes. By overlaying these prompts onto images and fine-tuning a foundational model on a specialized dataset, our approach improves segmentation performance and user experience through flexible input methods. Results: The PDZSeg model was validated using three experimental setups: in-domain evaluation, variability in visual prompt availability, and robustness assessment. Using the ESD-DZSeg dataset, results show that our method outperforms state-of-the-art segmentation approaches. This is the first study to integrate visual prompt design into dissection zone segmentation. Conclusion: The PDZSeg model effectively utilizes visual prompts to enhance segmentation performance and user experience, supported by the novel ESD-DZSeg dataset as a benchmark for dissection zone segmentation in ESD. Our work establishes a foundation for future research.
Transferring Knowledge from High-Quality to Low-Quality MRI for Adult Glioma Diagnosis
Oct 24, 2024Glioma, a common and deadly brain tumor, requires early diagnosis for improved prognosis. However, low-quality Magnetic Resonance Imaging (MRI) technology in Sub-Saharan Africa (SSA) hinders accurate diagnosis. This paper presents our work in the BraTS Challenge on SSA Adult Glioma. We adopt the model from the BraTS-GLI 2021 winning solution and utilize it with three training strategies: (1) initially training on the BraTS-GLI 2021 dataset with fine-tuning on the BraTS-Africa dataset, (2) training solely on the BraTS-Africa dataset, and (3) training solely on the BraTS-Africa dataset with 2x super-resolution enhancement. Results show that initial training on the BraTS-GLI 2021 dataset followed by fine-tuning on the BraTS-Africa dataset has yielded the best results. This suggests the importance of high-quality datasets in providing prior knowledge during training. Our top-performing model achieves Dice scores of 0.882, 0.840, and 0.926, and Hausdorff Distance (95%) scores of 15.324, 37.518, and 13.971 for enhancing tumor, tumor core, and whole tumor, respectively, in the validation phase. In the final phase of the competition, our approach successfully secured second place overall, reflecting the strength and effectiveness of our model and training strategies. Our approach provides insights into improving glioma diagnosis in SSA, showing the potential of deep learning in resource-limited settings and the importance of transfer learning from high-quality datasets.
CoPESD: A Multi-Level Surgical Motion Dataset for Training Large Vision-Language Models to Co-Pilot Endoscopic Submucosal Dissection
Oct 10, 2024



submucosal dissection (ESD) enables rapid resection of large lesions, minimizing recurrence rates and improving long-term overall survival. Despite these advantages, ESD is technically challenging and carries high risks of complications, necessitating skilled surgeons and precise instruments. Recent advancements in Large Visual-Language Models (LVLMs) offer promising decision support and predictive planning capabilities for robotic systems, which can augment the accuracy of ESD and reduce procedural risks. However, existing datasets for multi-level fine-grained ESD surgical motion understanding are scarce and lack detailed annotations. In this paper, we design a hierarchical decomposition of ESD motion granularity and introduce a multi-level surgical motion dataset (CoPESD) for training LVLMs as the robotic \textbf{Co}-\textbf{P}ilot of \textbf{E}ndoscopic \textbf{S}ubmucosal \textbf{D}issection. CoPESD includes 17,679 images with 32,699 bounding boxes and 88,395 multi-level motions, from over 35 hours of ESD videos for both robot-assisted and conventional surgeries. CoPESD enables granular analysis of ESD motions, focusing on the complex task of submucosal dissection. Extensive experiments on the LVLMs demonstrate the effectiveness of CoPESD in training LVLMs to predict following surgical robotic motions. As the first multimodal ESD motion dataset, CoPESD supports advanced research in ESD instruction-following and surgical automation. The dataset is available at \href{https://github.com/gkw0010/CoPESD}{https://github.com/gkw0010/CoPESD.}}
Benchmarking Robustness of Endoscopic Depth Estimation with Synthetically Corrupted Data
Sep 24, 2024Accurate depth perception is crucial for patient outcomes in endoscopic surgery, yet it is compromised by image distortions common in surgical settings. To tackle this issue, our study presents a benchmark for assessing the robustness of endoscopic depth estimation models. We have compiled a comprehensive dataset that reflects real-world conditions, incorporating a range of synthetically induced corruptions at varying severity levels. To further this effort, we introduce the Depth Estimation Robustness Score (DERS), a novel metric that combines measures of error, accuracy, and robustness to meet the multifaceted requirements of surgical applications. This metric acts as a foundational element for evaluating performance, establishing a new paradigm for the comparative analysis of depth estimation technologies. Additionally, we set forth a benchmark focused on robustness for the evaluation of depth estimation in endoscopic surgery, with the aim of driving progress in model refinement. A thorough analysis of two monocular depth estimation models using our framework reveals crucial information about their reliability under adverse conditions. Our results emphasize the essential need for algorithms that can tolerate data corruption, thereby advancing discussions on improving model robustness. The impact of this research transcends theoretical frameworks, providing concrete gains in surgical precision and patient safety. This study establishes a benchmark for the robustness of depth estimation and serves as a foundation for developing more resilient surgical support technologies. Code is available at https://github.com/lofrienger/EndoDepthBenchmark.
Fine-grained Classification of Port Wine Stains Using Optical Coherence Tomography Angiography
Aug 29, 2024



Accurate classification of port wine stains (PWS, vascular malformations present at birth), is critical for subsequent treatment planning. However, the current method of classifying PWS based on the external skin appearance rarely reflects the underlying angiopathological heterogeneity of PWS lesions, resulting in inconsistent outcomes with the common vascular-targeted photodynamic therapy (V-PDT) treatments. Conversely, optical coherence tomography angiography (OCTA) is an ideal tool for visualizing the vascular malformations of PWS. Previous studies have shown no significant correlation between OCTA quantitative metrics and the PWS subtypes determined by the current classification approach. This study proposes a new classification approach for PWS using both OCT and OCTA. By examining the hypodermic histopathology and vascular structure of PWS, we have devised a fine-grained classification method that subdivides PWS into five distinct types. To assess the angiopathological differences of various PWS subtypes, we have analyzed six metrics related to vascular morphology and depth information of PWS lesions. The five PWS types present significant differences across all metrics compared to the conventional subtypes. Our findings suggest that an angiopathology-based classification accurately reflects the heterogeneity in PWS lesions. This research marks the first attempt to classify PWS based on angiopathology, potentially guiding more effective subtyping and treatment strategies for PWS.