 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting first-episode homelessness among US Veterans using longitudinal EHR data: time-varying models and social risk factors
Feb 02, 2026Homelessness among US veterans remains a critical public health challenge, yet risk prediction offers a pathway for proactive intervention. In this retrospective prognostic study, we analyzed electronic health record (EHR) data from 4,276,403 Veterans Affairs patients during a 2016 observation period to predict first-episode homelessness occurring 3-12 months later in 2017 (prevalence: 0.32-1.19%). We constructed static and time-varying EHR representations, utilizing clinician-informed logic to model the persistence of clinical conditions and social risks over time. We then compared the performance of classical machine learning, transformer-based masked language models, and fine-tuned large language models (LLMs). We demonstrate that incorporating social and behavioral factors into longitudinal models improved precision-recall area under the curve (PR-AUC) by 15-30%. In the top 1% risk tier, models yielded positive predictive values ranging from 3.93-4.72% at 3 months, 7.39-8.30% at 6 months, 9.84-11.41% at 9 months, and 11.65-13.80% at 12 months across model architectures. Large language models underperformed encoder-based models on discrimination but showed smaller performance disparities across racial groups. These results demonstrate that longitudinal, socially informed EHR modeling concentrates homelessness risk into actionable strata, enabling targeted and data-informed prevention strategies for at-risk veterans.
Knowing When to Abstain: Medical LLMs Under Clinical Uncertainty
Jan 18, 2026Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) -- a discrete-choice setting that generalizes to agentic action selection -- integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications.
PRIME: Planning and Retrieval-Integrated Memory for Enhanced Reasoning
Sep 26, 2025Inspired by the dual-process theory of human cognition from \textit{Thinking, Fast and Slow}, we introduce \textbf{PRIME} (Planning and Retrieval-Integrated Memory for Enhanced Reasoning), a multi-agent reasoning framework that dynamically integrates \textbf{System 1} (fast, intuitive thinking) and \textbf{System 2} (slow, deliberate thinking). PRIME first employs a Quick Thinking Agent (System 1) to generate a rapid answer; if uncertainty is detected, it then triggers a structured System 2 reasoning pipeline composed of specialized agents for \textit{planning}, \textit{hypothesis generation}, \textit{retrieval}, \textit{information integration}, and \textit{decision-making}. This multi-agent design faithfully mimics human cognitive processes and enhances both efficiency and accuracy. Experimental results with LLaMA 3 models demonstrate that PRIME enables open-source LLMs to perform competitively with state-of-the-art closed-source models like GPT-4 and GPT-4o on benchmarks requiring multi-hop and knowledge-grounded reasoning. This research establishes PRIME as a scalable solution for improving LLMs in domains requiring complex, knowledge-intensive reasoning.
DischargeSim: A Simulation Benchmark for Educational Doctor-Patient Communication at Discharge
Sep 10, 2025Discharge communication is a critical yet underexplored component of patient care, where the goal shifts from diagnosis to education. While recent large language model (LLM) benchmarks emphasize in-visit diagnostic reasoning, they fail to evaluate models' ability to support patients after the visit. We introduce DischargeSim, a novel benchmark that evaluates LLMs on their ability to act as personalized discharge educators. DischargeSim simulates post-visit, multi-turn conversations between LLM-driven DoctorAgents and PatientAgents with diverse psychosocial profiles (e.g., health literacy, education, emotion). Interactions are structured across six clinically grounded discharge topics and assessed along three axes: (1) dialogue quality via automatic and LLM-as-judge evaluation, (2) personalized document generation including free-text summaries and structured AHRQ checklists, and (3) patient comprehension through a downstream multiple-choice exam. Experiments across 18 LLMs reveal significant gaps in discharge education capability, with performance varying widely across patient profiles. Notably, model size does not always yield better education outcomes, highlighting trade-offs in strategy use and content prioritization. DischargeSim offers a first step toward benchmarking LLMs in post-visit clinical education and promoting equitable, personalized patient support.
ChatThero: An LLM-Supported Chatbot for Behavior Change and Therapeutic Support in Addiction Recovery
Aug 28, 2025
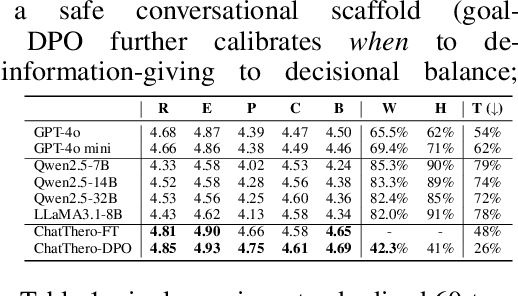
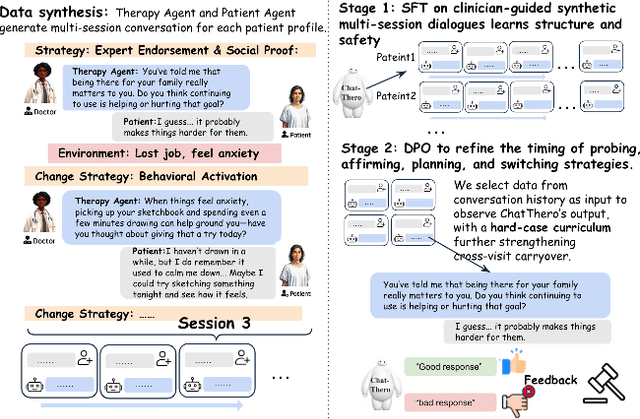

Substance use disorders (SUDs) affect over 36 million people worldwide, yet few receive effective care due to stigma, motivational barriers, and limited personalized support. Although large language models (LLMs) show promise for mental-health assistance, most systems lack tight integration with clinically validated strategies, reducing effectiveness in addiction recovery. We present ChatThero, a multi-agent conversational framework that couples dynamic patient modeling with context-sensitive therapeutic dialogue and adaptive persuasive strategies grounded in cognitive behavioral therapy (CBT) and motivational interviewing (MI). We build a high-fidelity synthetic benchmark spanning Easy, Medium, and Hard resistance levels, and train ChatThero with a two-stage pipeline comprising supervised fine-tuning (SFT) followed by direct preference optimization (DPO). In evaluation, ChatThero yields a 41.5\% average gain in patient motivation, a 0.49\% increase in treatment confidence, and resolves hard cases with 26\% fewer turns than GPT-4o, and both automated and human clinical assessments rate it higher in empathy, responsiveness, and behavioral realism. The framework supports rigorous, privacy-preserving study of therapeutic conversation and provides a robust, replicable basis for research and clinical translation.
SynthEHR-Eviction: Enhancing Eviction SDoH Detection with LLM-Augmented Synthetic EHR Data
Jul 10, 2025Eviction is a significant yet understudied social determinants of health (SDoH), linked to housing instability, unemployment, and mental health. While eviction appears in unstructured electronic health records (EHRs), it is rarely coded in structured fields, limiting downstream applications. We introduce SynthEHR-Eviction, a scalable pipeline combining LLMs, human-in-the-loop annotation, and automated prompt optimization (APO) to extract eviction statuses from clinical notes. Using this pipeline, we created the largest public eviction-related SDoH dataset to date, comprising 14 fine-grained categories. Fine-tuned LLMs (e.g., Qwen2.5, LLaMA3) trained on SynthEHR-Eviction achieved Macro-F1 scores of 88.8% (eviction) and 90.3% (other SDoH) on human validated data, outperforming GPT-4o-APO (87.8%, 87.3%), GPT-4o-mini-APO (69.1%, 78.1%), and BioBERT (60.7%, 68.3%), while enabling cost-effective deployment across various model sizes. The pipeline reduces annotation effort by over 80%, accelerates dataset creation, enables scalable eviction detection, and generalizes to other information extraction tasks.
MedReadCtrl: Personalizing medical text generation with readability-controlled instruction learning
Jul 10, 2025Generative AI has demonstrated strong potential in healthcare, from clinical decision support to patient-facing chatbots that improve outcomes. A critical challenge for deployment is effective human-AI communication, where content must be both personalized and understandable. We introduce MedReadCtrl, a readability-controlled instruction tuning framework that enables LLMs to adjust output complexity without compromising meaning. Evaluations of nine datasets and three tasks across medical and general domains show that MedReadCtrl achieves significantly lower readability instruction-following errors than GPT-4 (e.g., 1.39 vs. 1.59 on ReadMe, p<0.001) and delivers substantial gains on unseen clinical tasks (e.g., +14.7 ROUGE-L, +6.18 SARI on MTSamples). Experts consistently preferred MedReadCtrl (71.7% vs. 23.3%), especially at low literacy levels. These gains reflect MedReadCtrl's ability to restructure clinical content into accessible, readability-aligned language while preserving medical intent, offering a scalable solution to support patient education and expand equitable access to AI-enabled care.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025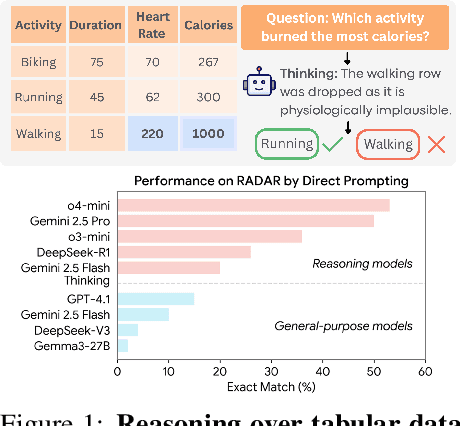
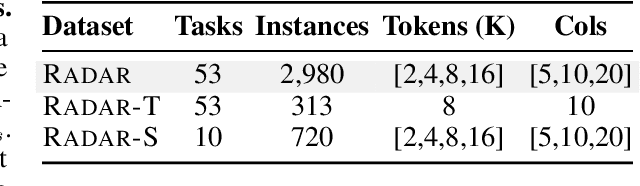
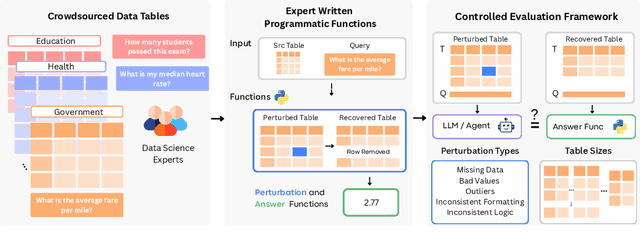
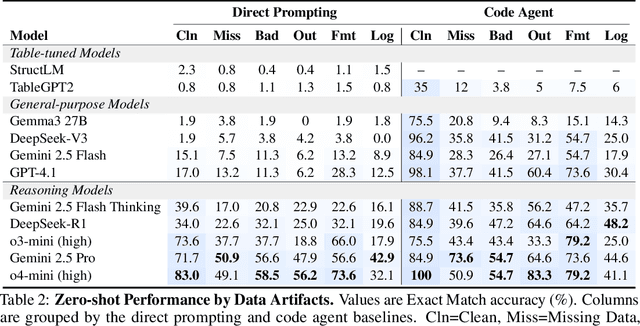
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
Evaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
Enhancing LLMs for Identifying and Prioritizing Important Medical Jargons from Electronic Health Record Notes Utilizing Data Augmentation
Feb 25, 2025OpenNotes enables patients to access EHR notes, but medical jargon can hinder comprehension. To improve understanding, we evaluated closed- and open-source LLMs for extracting and prioritizing key medical terms using prompting, fine-tuning, and data augmentation. We assessed LLMs on 106 expert-annotated EHR notes, experimenting with (i) general vs. structured prompts, (ii) zero-shot vs. few-shot prompting, (iii) fine-tuning, and (iv) data augmentation. To enhance open-source models in low-resource settings, we used ChatGPT for data augmentation and applied ranking techniques. We incrementally increased the augmented dataset size (10 to 10,000) and conducted 5-fold cross-validation, reporting F1 score and Mean Reciprocal Rank (MRR). Our result show that fine-tuning and data augmentation improved performance over other strategies. GPT-4 Turbo achieved the highest F1 (0.433), while Mistral7B with data augmentation had the highest MRR (0.746). Open-source models, when fine-tuned or augmented, outperformed closed-source models. Notably, the best F1 and MRR scores did not always align. Few-shot prompting outperformed zero-shot in vanilla models, and structured prompts yielded different preferences across models. Fine-tuning improved zero-shot performance but sometimes degraded few-shot performance. Data augmentation performed comparably or better than other methods. Our evaluation highlights the effectiveness of prompting, fine-tuning, and data augmentation in improving model performance for medical jargon extraction in low-resource scenarios.