 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthEHR-Eviction: Enhancing Eviction SDoH Detection with LLM-Augmented Synthetic EHR Data
Jul 10, 2025Eviction is a significant yet understudied social determinants of health (SDoH), linked to housing instability, unemployment, and mental health. While eviction appears in unstructured electronic health records (EHRs), it is rarely coded in structured fields, limiting downstream applications. We introduce SynthEHR-Eviction, a scalable pipeline combining LLMs, human-in-the-loop annotation, and automated prompt optimization (APO) to extract eviction statuses from clinical notes. Using this pipeline, we created the largest public eviction-related SDoH dataset to date, comprising 14 fine-grained categories. Fine-tuned LLMs (e.g., Qwen2.5, LLaMA3) trained on SynthEHR-Eviction achieved Macro-F1 scores of 88.8% (eviction) and 90.3% (other SDoH) on human validated data, outperforming GPT-4o-APO (87.8%, 87.3%), GPT-4o-mini-APO (69.1%, 78.1%), and BioBERT (60.7%, 68.3%), while enabling cost-effective deployment across various model sizes. The pipeline reduces annotation effort by over 80%, accelerates dataset creation, enables scalable eviction detection, and generalizes to other information extraction tasks.
Automated Identification of Eviction Status from Electronic Health Record Notes
Dec 06, 2022



Objective: Evictions are involved in a cascade of negative events that can lead to unemployment, homelessness, long-term poverty, and mental health problems. In this study, we developed a natural language processing system to automatically detect eviction incidences and their attributes from electronic health record (EHR) notes. Materials and Methods: We annotated eviction status in 5000 EHR notes from the Veterans Health Administration. We developed a novel model, called Knowledge Injection based on Ripple Effects of Social and Behavioral Determinants of Health (KIRESH), that has shown to substantially outperform other state-of-the-art models such as fine-tuning pre-trained language models like BioBERT and Bio_ClinicalBERT. Moreover, we designed a prompt to further improve the model performance by using the intrinsic connection between the two sub-tasks of eviction presence and period prediction. Finally, we used the Temperature Scaling-based Calibration on our KIRESH-Prompt method to avoid over-confidence issues arising from the imbalance dataset. Results: KIRESH-Prompt achieved a Macro-F1 of 0.6273 (presence) and 0.7115 (period), which was significantly higher than 0.5382 (presence) and 0.67167 (period) for just fine-tuning Bio_ClinicalBERT model. Conclusion and Future Work: KIRESH-Prompt has substantially improved eviction status classification. In future work, we will evaluate the generalizability of the model framework to other applications.
MedJEx: A Medical Jargon Extraction Model with Wiki's Hyperlink Span and Contextualized Masked Language Model Score
Oct 12, 2022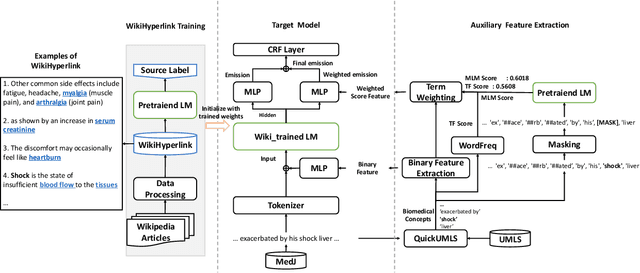

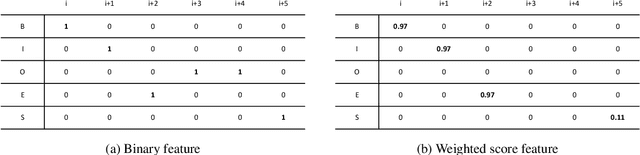
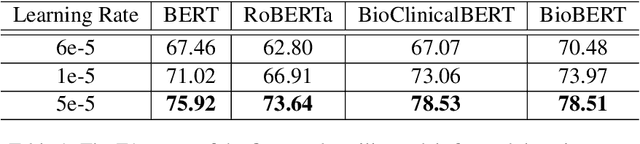
This paper proposes a new natural language processing (NLP) application for identifying medical jargon terms potentially difficult for patients to comprehend from electronic health record (EHR) notes. We first present a novel and publicly available dataset with expert-annotated medical jargon terms from 18K+ EHR note sentences ($MedJ$). Then, we introduce a novel medical jargon extraction ($MedJEx$) model which has been shown to outperform existing state-of-the-art NLP models. First, MedJEx improved the overall performance when it was trained on an auxiliary Wikipedia hyperlink span dataset, where hyperlink spans provide additional Wikipedia articles to explain the spans (or terms), and then fine-tuned on the annotated MedJ data. Secondly, we found that a contextualized masked language model score was beneficial for detecting domain-specific unfamiliar jargon terms. Moreover, our results show that training on the auxiliary Wikipedia hyperlink span datasets improved six out of eight biomedical named entity recognition benchmark datasets. Both MedJ and MedJEx are publicly available.