 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspGPT: Leveraging Semantic Knowledge from a Large Language Model for Task-Oriented Grasping
Jul 30, 2023



Task-oriented grasping (TOG) refers to the problem of predicting grasps on an object that enable subsequent manipulation tasks. To model the complex relationships between objects, tasks, and grasps, existing methods incorporate semantic knowledge as priors into TOG pipelines. However, the existing semantic knowledge is typically constructed based on closed-world concept sets, restraining the generalization to novel concepts out of the pre-defined sets. To address this issue, we propose GraspGPT, a large language model (LLM) based TOG framework that leverages the open-end semantic knowledge from an LLM to achieve zero-shot generalization to novel concepts. We conduct experiments on Language Augmented TaskGrasp (LA-TaskGrasp) dataset and demonstrate that GraspGPT outperforms existing TOG methods on different held-out settings when generalizing to novel concepts out of the training set. The effectiveness of GraspGPT is further validated in real-robot experiments. Our code, data, appendix, and video are publicly available at https://sites.google.com/view/graspgpt/.
DPSeq: A Novel and Efficient Digital Pathology Classifier for Predicting Cancer Biomarkers using Sequencer Architecture
May 03, 2023In digital pathology tasks, transformers have achieved state-of-the-art results, surpassing convolutional neural networks (CNNs). However, transformers are usually complex and resource intensive. In this study, we developed a novel and efficient digital pathology classifier called DPSeq, to predict cancer biomarkers through fine-tuning a sequencer architecture integrating horizon and vertical bidirectional long short-term memory (BiLSTM) networks. Using hematoxylin and eosin (H&E)-stained histopathological images of colorectal cancer (CRC) from two international datasets: The Cancer Genome Atlas (TCGA) and Molecular and Cellular Oncology (MCO), the predictive performance of DPSeq was evaluated in series of experiments. DPSeq demonstrated exceptional performance for predicting key biomarkers in CRC (MSI status, Hypermutation, CIMP status, BRAF mutation, TP53 mutation and chromosomal instability [CING]), outperforming most published state-of-the-art classifiers in a within-cohort internal validation and a cross-cohort external validation. Additionally, under the same experimental conditions using the same set of training and testing datasets, DPSeq surpassed 4 CNN (ResNet18, ResNet50, MobileNetV2, and EfficientNet) and 2 transformer (ViT and Swin-T) models, achieving the highest AUROC and AUPRC values in predicting MSI status, BRAF mutation, and CIMP status. Furthermore, DPSeq required less time for both training and prediction due to its simple architecture. Therefore, DPSeq appears to be the preferred choice over transformer and CNN models for predicting cancer biomarkers.
NPR: Nocturnal Place Recognition in Streets
Apr 17, 2023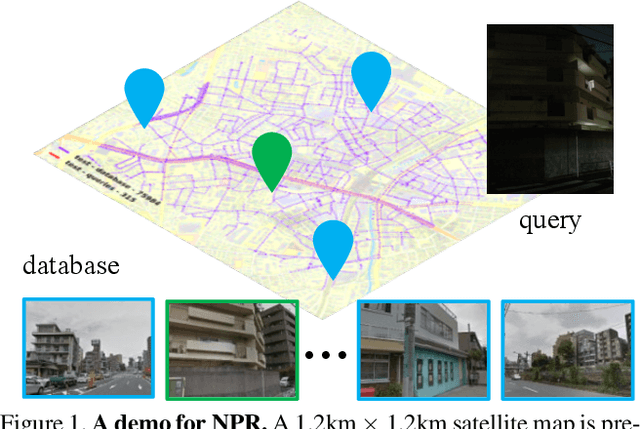
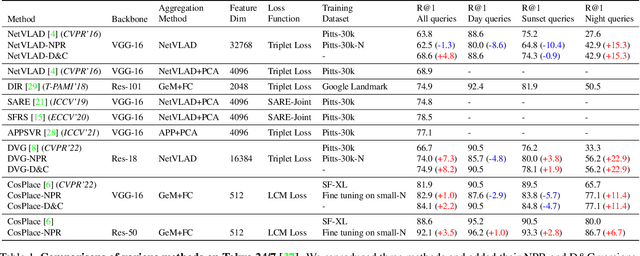


Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
Wearing Masks Implies Refuting Trump?: Towards Target-specific User Stance Prediction across Events in COVID-19 and US Election 2020
Mar 21, 2023



People who share similar opinions towards controversial topics could form an echo chamber and may share similar political views toward other topics as well. The existence of such connections, which we call connected behavior, gives researchers a unique opportunity to predict how one would behave for a future event given their past behaviors. In this work, we propose a framework to conduct connected behavior analysis. Neural stance detection models are trained on Twitter data collected on three seemingly independent topics, i.e., wearing a mask, racial equality, and Trump, to detect people's stance, which we consider as their online behavior in each topic-related event. Our results reveal a strong connection between the stances toward the three topical events and demonstrate the power of past behaviors in predicting one's future behavior.
DSDP: A Blind Docking Strategy Accelerated by GPUs
Mar 16, 2023



Virtual screening, including molecular docking, plays an essential role in drug discovery. Many traditional and machine-learning based methods are available to fulfil the docking task. The traditional docking methods are normally extensively time-consuming, and their performance in blind docking remains to be improved. Although the runtime of docking based on machine learning is significantly decreased, their accuracy is still limited. In this study, we take the advantage of both traditional and machine-learning based methods, and present a method Deep Site and Docking Pose (DSDP) to improve the performance of blind docking. For the traditional blind docking, the entire protein is covered by a cube, and the initial positions of ligands are randomly generated in the cube. In contract, DSDP can predict the binding site of proteins and provide an accurate searching space and initial positions for the further conformational sampling. The docking task of DSDP makes use of the score function and a similar but modified searching strategy of AutoDock Vina, accelerated by implementation in GPUs. We systematically compare its performance with the state-of-the-art methods, including Autodock Vina, GNINA, QuickVina, SMINA, and DiffDock. DSDP reaches a 29.8% top-1 success rate (RMSD < 2 {\AA}) on an unbiased and challenging test dataset with 1.2 s wall-clock computational time per system. Its performances on DUD-E dataset and the time-split PDBBind dataset used in EquiBind, TankBind, and DiffDock are also effective, presenting a 57.2% and 41.8% top-1 success rate with 0.8 s and 1.0 s per system, respectively.
Prediction of SLAM ATE Using an Ensemble Learning Regression Model and 1-D Global Pooling of Data Characterization
Mar 01, 2023Robustness and resilience of simultaneous localization and mapping (SLAM) are critical requirements for modern autonomous robotic systems. One of the essential steps to achieve robustness and resilience is the ability of SLAM to have an integrity measure for its localization estimates, and thus, have internal fault tolerance mechanisms to deal with performance degradation. In this work, we introduce a novel method for predicting SLAM localization error based on the characterization of raw sensor inputs. The proposed method relies on using a random forest regression model trained on 1-D global pooled features that are generated from characterized raw sensor data. The model is validated by using it to predict the performance of ORB-SLAM3 on three different datasets running on four different operating modes, resulting in an average prediction accuracy of up to 94.7\%. The paper also studies the impact of 12 different 1-D global pooling functions on regression quality, and the superiority of 1-D global averaging is quantitatively proven. Finally, the paper studies the quality of prediction with limited training data, and proves that we are able to maintain proper prediction quality when only 20 \% of the training examples are used for training, which highlights how the proposed model can optimize the evaluation footprint of SLAM systems.
Task-Oriented Grasp Prediction with Visual-Language Inputs
Feb 28, 2023



To perform household tasks, assistive robots receive commands in the form of user language instructions for tool manipulation. The initial stage involves selecting the intended tool (i.e., object grounding) and grasping it in a task-oriented manner (i.e., task grounding). Nevertheless, prior researches on visual-language grasping (VLG) focus on object grounding, while disregarding the fine-grained impact of tasks on object grasping. Task-incompatible grasping of a tool will inevitably limit the success of subsequent manipulation steps. Motivated by this problem, this paper proposes GraspCLIP, which addresses the challenge of task grounding in addition to object grounding to enable task-oriented grasp prediction with visual-language inputs. Evaluation on a custom dataset demonstrates that GraspCLIP achieves superior performance over established baselines with object grounding only. The effectiveness of the proposed method is further validated on an assistive robotic arm platform for grasping previously unseen kitchen tools given the task specification. Our presentation video is available at: https://www.youtube.com/watch?v=e1wfYQPeAXU.
Robot Person Following Under Partial Occlusion
Feb 27, 2023



Robot person following (RPF) is a capability that supports many useful human-robot-interaction (HRI) applications. However, existing solutions to person following often assume full observation of the tracked person. As a consequence, they cannot track the person reliably under partial occlusion where the assumption of full observation is not satisfied. In this paper, we focus on the problem of robot person following under partial occlusion caused by a limited field of view of a monocular camera. Based on the key insight that it is possible to locate the target person when one or more of his/her joints are visible, we propose a method in which each visible joint contributes a location estimate of the followed person. Experiments on a public person-following dataset show that, even under partial occlusion, the proposed method can still locate the person more reliably than the existing SOTA methods. As well, the application of our method is demonstrated in real experiments on a mobile robot.
A Convolutional-Transformer Network for Crack Segmentation with Boundary Awareness
Feb 23, 2023Cracks play a crucial role in assessing the safety and durability of manufactured buildings. However, the long and sharp topological features and complex background of cracks make the task of crack segmentation extremely challenging. In this paper, we propose a novel convolutional-transformer network based on encoder-decoder architecture to solve this challenge. Particularly, we designed a Dilated Residual Block (DRB) and a Boundary Awareness Module (BAM). The DRB pays attention to the local detail of cracks and adjusts the feature dimension for other blocks as needed. And the BAM learns the boundary features from the dilated crack label. Furthermore, the DRB is combined with a lightweight transformer that captures global information to serve as an effective encoder. Experimental results show that the proposed network performs better than state-of-the-art algorithms on two typical datasets. Datasets, code, and trained models are available for research at https://github.com/HqiTao/CT-crackseg.
Time to Embrace Natural Language Processing (NLP)-based Digital Pathology: Benchmarking NLP- and Convolutional Neural Network-based Deep Learning Pipelines
Feb 21, 2023

NLP-based computer vision models, particularly vision transformers, have been shown to outperform CNN models in many imaging tasks. However, most digital pathology artificial-intelligence models are based on CNN architectures, probably owing to a lack of data regarding NLP models for pathology images. In this study, we developed digital pathology pipelines to benchmark the five most recently proposed NLP models (vision transformer (ViT), Swin Transformer, MobileViT, CMT, and Sequencer2D) and four popular CNN models (ResNet18, ResNet50, MobileNetV2, and EfficientNet) to predict biomarkers in colorectal cancer (microsatellite instability, CpG island methylator phenotype, and BRAF mutation). Hematoxylin and eosin-stained whole-slide images from Molecular and Cellular Oncology and The Cancer Genome Atlas were used as training and external validation datasets, respectively. Cross-study external validations revealed that the NLP-based models significantly outperformed the CNN-based models in biomarker prediction tasks, improving the overall prediction and precision up to approximately 10% and 26%, respectively. Notably, compared with existing models in the current literature using large training datasets, our NLP models achieved state-of-the-art predictions for all three biomarkers using a relatively small training dataset, suggesting that large training datasets are not a prerequisite for NLP models or transformers, and NLP may be more suitable for clinical studies in which small training datasets are commonly collected. The superior performance of Sequencer2D suggests that further research and innovation on both transformer and bidirectional long short-term memory architectures are warranted in the field of digital pathology. NLP models can replace classic CNN architectures and become the new workhorse backbone in the field of digital pathology.