 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Federated Learning for Massive Models with NVIDIA FLARE
Feb 12, 2024



In the ever-evolving landscape of artificial intelligence (AI) and large language models (LLMs), handling and leveraging data effectively has become a critical challenge. Most state-of-the-art machine learning algorithms are data-centric. However, as the lifeblood of model performance, necessary data cannot always be centralized due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets. In this paper, we explore how federated learning enabled by NVIDIA FLARE can address these challenges with easy and scalable integration capabilities, enabling parameter-efficient and full supervised fine-tuning of LLMs for natural language processing and biopharmaceutical applications to enhance their accuracy and robustness.
FedBPT: Efficient Federated Black-box Prompt Tuning for Large Language Models
Oct 02, 2023



Pre-trained language models (PLM) have revolutionized the NLP landscape, achieving stellar performances across diverse tasks. These models, while benefiting from vast training data, often require fine-tuning on specific data to cater to distinct downstream tasks. However, this data adaptation process has inherent security and privacy concerns, primarily when leveraging user-generated, device-residing data. Federated learning (FL) provides a solution, allowing collaborative model fine-tuning without centralized data collection. However, applying FL to finetune PLMs is hampered by challenges, including restricted model parameter access, high computational requirements, and communication overheads. This paper introduces Federated Black-box Prompt Tuning (FedBPT), a framework designed to address these challenges. FedBPT does not require the clients to access the model parameters. By focusing on training optimal prompts and utilizing gradient-free optimization methods, FedBPT reduces the number of exchanged variables, boosts communication efficiency, and minimizes computational and storage costs. Experiments highlight the framework's ability to drastically cut communication and memory costs while maintaining competitive performance. Ultimately, FedBPT presents a promising solution for efficient, privacy-preserving fine-tuning of PLM in the age of large language models.
ConDistFL: Conditional Distillation for Federated Learning from Partially Annotated Data
Aug 08, 2023



Developing a generalized segmentation model capable of simultaneously delineating multiple organs and diseases is highly desirable. Federated learning (FL) is a key technology enabling the collaborative development of a model without exchanging training data. However, the limited access to fully annotated training data poses a major challenge to training generalizable models. We propose "ConDistFL", a framework to solve this problem by combining FL with knowledge distillation. Local models can extract the knowledge of unlabeled organs and tumors from partially annotated data from the global model with an adequately designed conditional probability representation. We validate our framework on four distinct partially annotated abdominal CT datasets from the MSD and KiTS19 challenges. The experimental results show that the proposed framework significantly outperforms FedAvg and FedOpt baselines. Moreover, the performance on an external test dataset demonstrates superior generalizability compared to models trained on each dataset separately. Our ablation study suggests that ConDistFL can perform well without frequent aggregation, reducing the communication cost of FL. Our implementation will be available at https://github.com/NVIDIA/NVFlare/tree/dev/research/condist-fl.
DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images
May 18, 2023Automatic segmentation of medical images is a key step for diagnostic and interventional tasks. However, achieving this requires large amounts of annotated volumes, which can be tedious and time-consuming task for expert annotators. In this paper, we introduce DeepEdit, a deep learning-based method for volumetric medical image annotation, that allows automatic and semi-automatic segmentation, and click-based refinement. DeepEdit combines the power of two methods: a non-interactive (i.e. automatic segmentation using nnU-Net, UNET or UNETR) and an interactive segmentation method (i.e. DeepGrow), into a single deep learning model. It allows easy integration of uncertainty-based ranking strategies (i.e. aleatoric and epistemic uncertainty computation) and active learning. We propose and implement a method for training DeepEdit by using standard training combined with user interaction simulation. Once trained, DeepEdit allows clinicians to quickly segment their datasets by using the algorithm in auto segmentation mode or by providing clicks via a user interface (i.e. 3D Slicer, OHIF). We show the value of DeepEdit through evaluation on the PROSTATEx dataset for prostate/prostatic lesions and the Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset for abdominal CT segmentation, using state-of-the-art network architectures as baseline for comparison. DeepEdit could reduce the time and effort annotating 3D medical images compared to DeepGrow alone. Source code is available at https://github.com/Project-MONAI/MONAILabel
Communication-Efficient Vertical Federated Learning with Limited Overlapping Samples
Mar 30, 2023



Federated learning is a popular collaborative learning approach that enables clients to train a global model without sharing their local data. Vertical federated learning (VFL) deals with scenarios in which the data on clients have different feature spaces but share some overlapping samples. Existing VFL approaches suffer from high communication costs and cannot deal efficiently with limited overlapping samples commonly seen in the real world. We propose a practical vertical federated learning (VFL) framework called \textbf{one-shot VFL} that can solve the communication bottleneck and the problem of limited overlapping samples simultaneously based on semi-supervised learning. We also propose \textbf{few-shot VFL} to improve the accuracy further with just one more communication round between the server and the clients. In our proposed framework, the clients only need to communicate with the server once or only a few times. We evaluate the proposed VFL framework on both image and tabular datasets. Our methods can improve the accuracy by more than 46.5\% and reduce the communication cost by more than 330$\times$ compared with state-of-the-art VFL methods when evaluated on CIFAR-10. Our code will be made publicly available at \url{https://nvidia.github.io/NVFlare/research/one-shot-vfl}.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
Warm Start Active Learning with Proxy Labels \& Selection via Semi-Supervised Fine-Tuning
Sep 13, 2022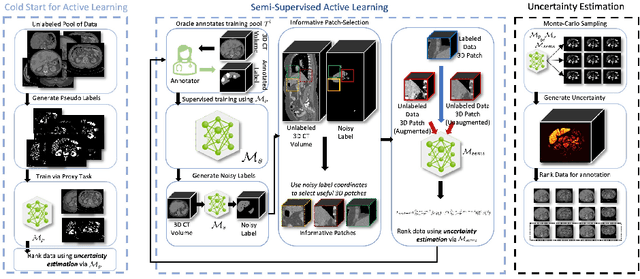
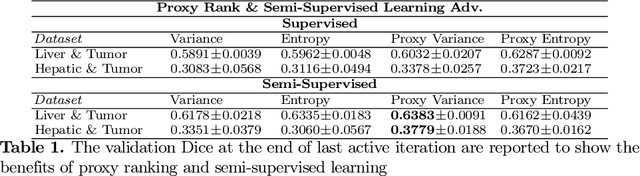
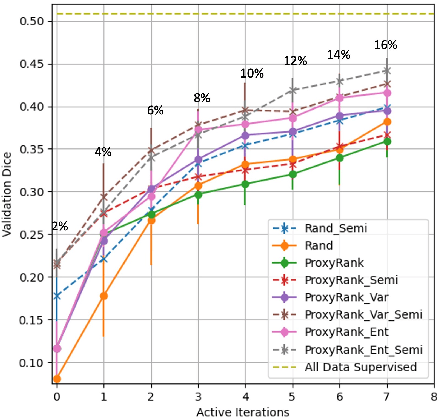
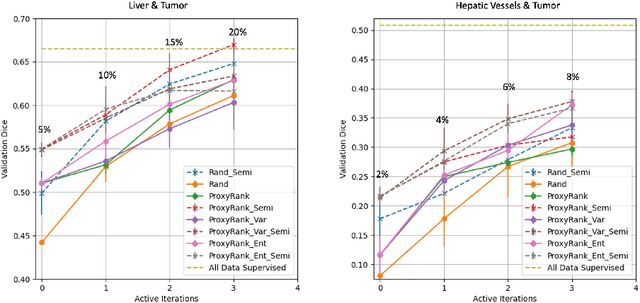
Which volume to annotate next is a challenging problem in building medical imaging datasets for deep learning. One of the promising methods to approach this question is active learning (AL). However, AL has been a hard nut to crack in terms of which AL algorithm and acquisition functions are most useful for which datasets. Also, the problem is exacerbated with which volumes to label first when there is zero labeled data to start with. This is known as the cold start problem in AL. We propose two novel strategies for AL specifically for 3D image segmentation. First, we tackle the cold start problem by proposing a proxy task and then utilizing uncertainty generated from the proxy task to rank the unlabeled data to be annotated. Second, we craft a two-stage learning framework for each active iteration where the unlabeled data is also used in the second stage as a semi-supervised fine-tuning strategy. We show the promise of our approach on two well-known large public datasets from medical segmentation decathlon. The results indicate that the initial selection of data and semi-supervised framework both showed significant improvement for several AL strategies.
Split-U-Net: Preventing Data Leakage in Split Learning for Collaborative Multi-Modal Brain Tumor Segmentation
Aug 22, 2022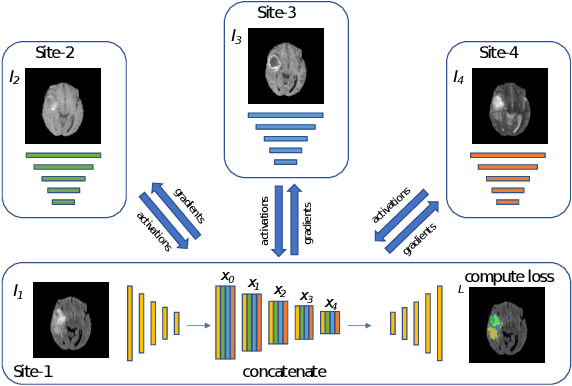

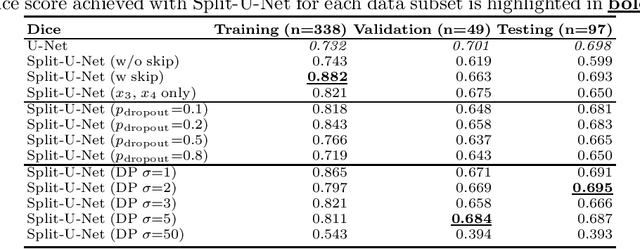
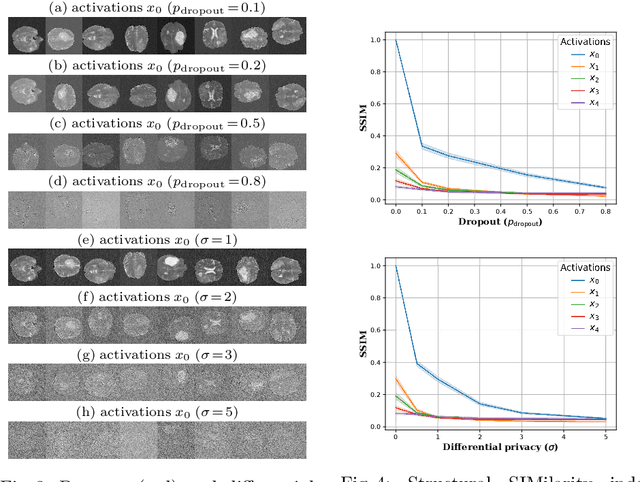
Split learning (SL) has been proposed to train deep learning models in a decentralized manner. For decentralized healthcare applications with vertical data partitioning, SL can be beneficial as it allows institutes with complementary features or images for a shared set of patients to jointly develop more robust and generalizable models. In this work, we propose "Split-U-Net" and successfully apply SL for collaborative biomedical image segmentation. Nonetheless, SL requires the exchanging of intermediate activation maps and gradients to allow training models across different feature spaces, which might leak data and raise privacy concerns. Therefore, we also quantify the amount of data leakage in common SL scenarios for biomedical image segmentation and provide ways to counteract such leakage by applying appropriate defense strategies.
MONAI Label: A framework for AI-assisted Interactive Labeling of 3D Medical Images
Mar 23, 2022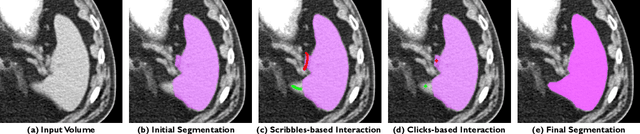
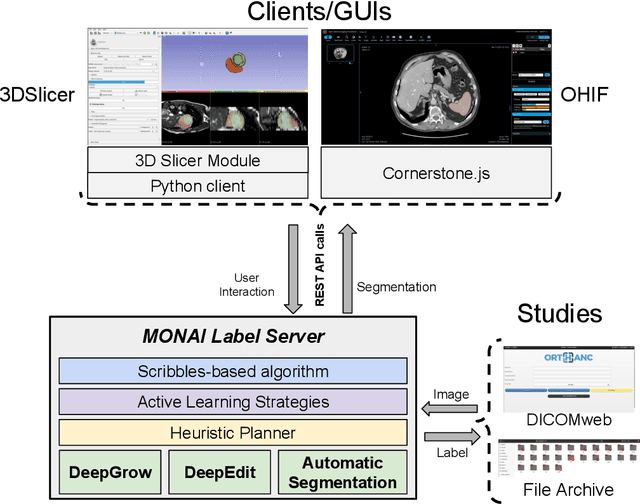
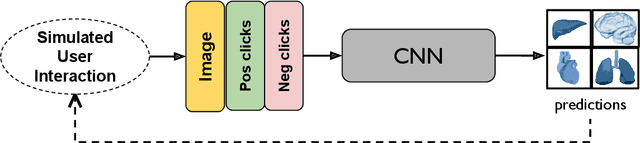
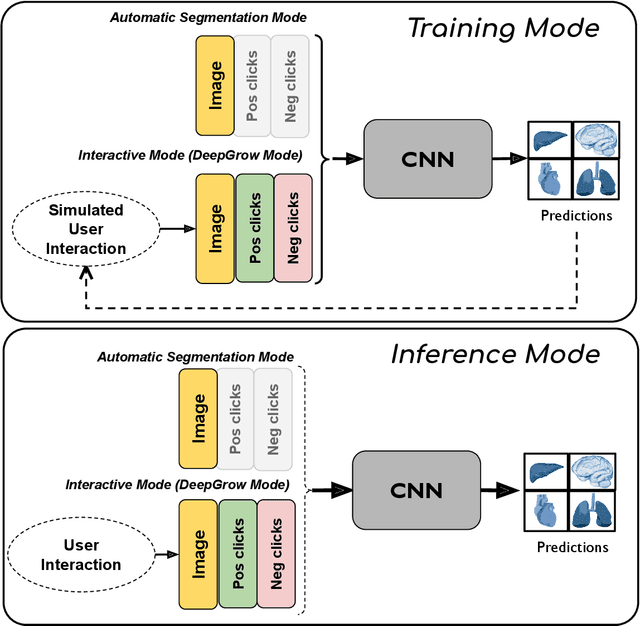
The lack of annotated datasets is a major challenge in training new task-specific supervised AI algorithms as manual annotation is expensive and time-consuming. To address this problem, we present MONAI Label, a free and open-source platform that facilitates the development of AI-based applications that aim at reducing the time required to annotate 3D medical image datasets. Through MONAI Label researchers can develop annotation applications focusing on their domain of expertise. It allows researchers to readily deploy their apps as services, which can be made available to clinicians via their preferred user-interface. Currently, MONAI Label readily supports locally installed (3DSlicer) and web-based (OHIF) frontends, and offers two Active learning strategies to facilitate and speed up the training of segmentation algorithms. MONAI Label allows researchers to make incremental improvements to their labeling apps by making them available to other researchers and clinicians alike. Lastly, MONAI Label provides sample labeling apps, namely DeepEdit and DeepGrow, demonstrating dramatically reduced annotation times.