 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-synchronous Training for Monotonic Attention Model
May 17, 2020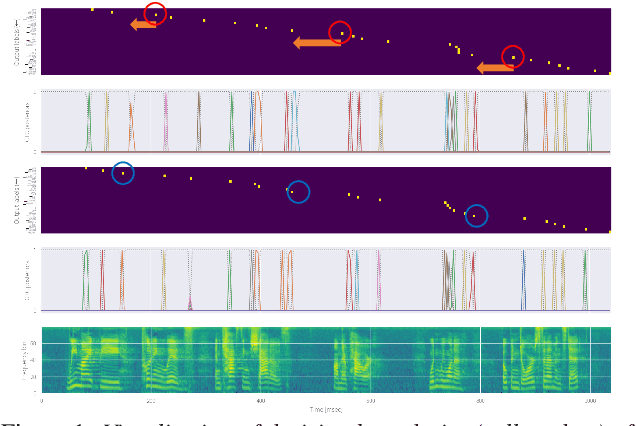

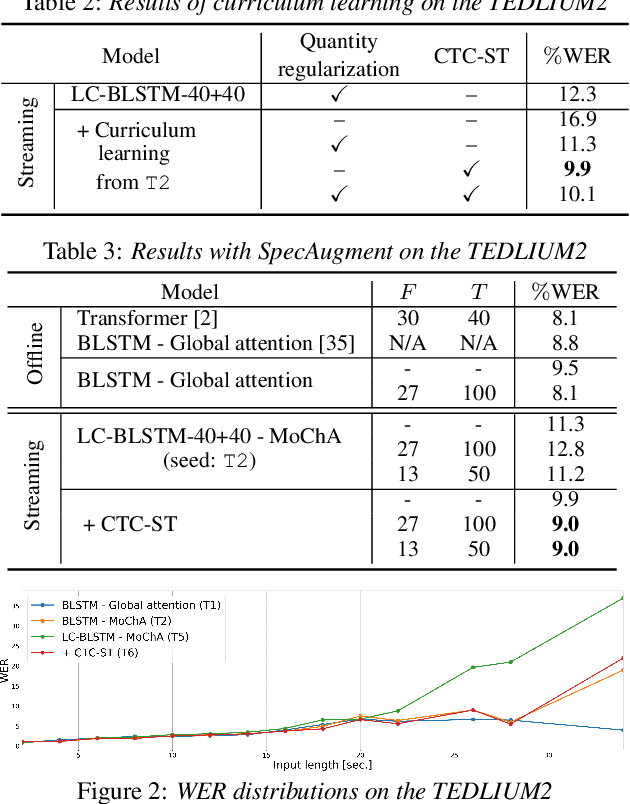
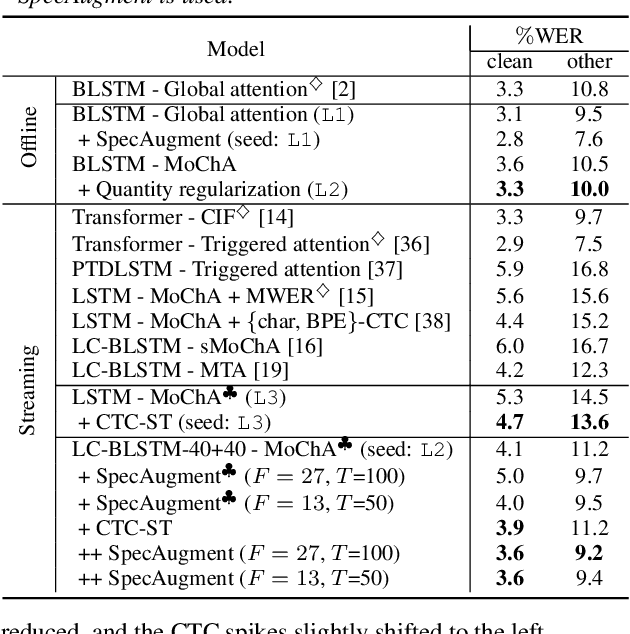
Monotonic chunkwise attention (MoChA) has been studied for the online streaming automatic speech recognition (ASR) based on a sequence-to-sequence framework. In contrast to connectionist temporal classification (CTC), backward probabilities cannot be leveraged in the alignment marginalization process during training due to left-to-right dependency in the decoder. This results in the error propagation of alignments to subsequent token generation. To address this problem, we propose CTC-synchronous training (CTC-ST), in which MoChA uses CTC alignments to learn optimal monotonic alignments. Reference CTC alignments are extracted from a CTC branch sharing the same encoder. The entire model is jointly optimized so that the expected boundaries from MoChA are synchronized with the alignments. Experimental evaluations of the TEDLIUM release-2 and Librispeech corpora show that the proposed method significantly improves recognition, especially for long utterances. We also show that CTC-ST can bring out the full potential of SpecAugment for MoChA.
Minimum Latency Training Strategies for Streaming Sequence-to-Sequence ASR
May 15, 2020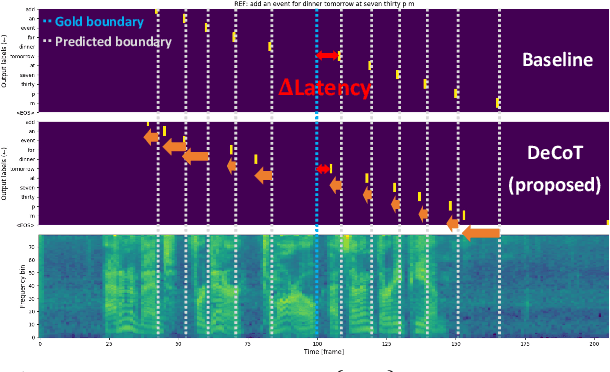

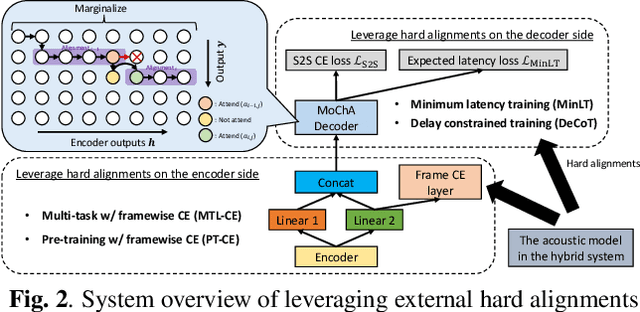
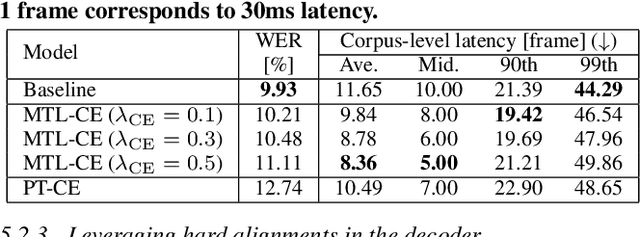
Recently, a few novel streaming attention-based sequence-to-sequence (S2S) models have been proposed to perform online speech recognition with linear-time decoding complexity. However, in these models, the decisions to generate tokens are delayed compared to the actual acoustic boundaries since their unidirectional encoders lack future information. This leads to an inevitable latency during inference. To alleviate this issue and reduce latency, we propose several strategies during training by leveraging external hard alignments extracted from the hybrid model. We investigate to utilize the alignments in both the encoder and the decoder. On the encoder side, (1) multi-task learning and (2) pre-training with the framewise classification task are studied. On the decoder side, we (3) remove inappropriate alignment paths beyond an acceptable latency during the alignment marginalization, and (4) directly minimize the differentiable expected latency loss. Experiments on the Cortana voice search task demonstrate that our proposed methods can significantly reduce the latency, and even improve the recognition accuracy in certain cases on the decoder side. We also present some analysis to understand the behaviors of streaming S2S models.
End-to-end speech-to-dialog-act recognition
Apr 23, 2020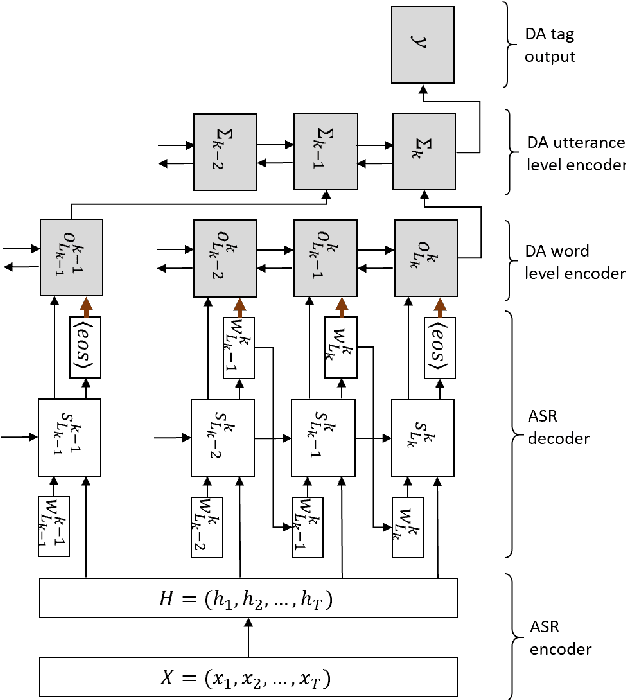
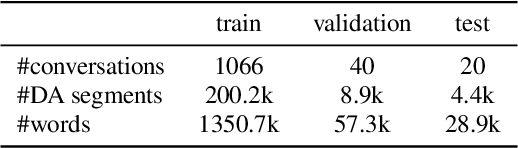
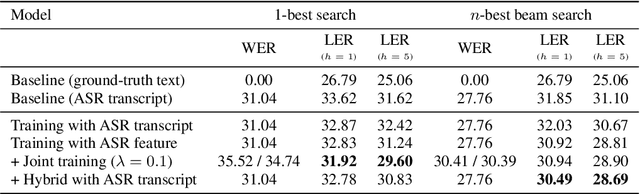
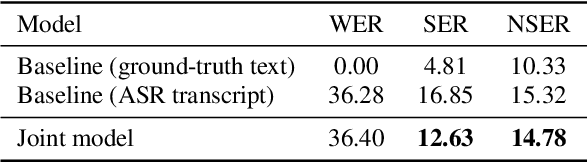
Spoken language understanding, which extracts intents and/or semantic concepts in utterances, is conventionally formulated as a post-processing of automatic speech recognition. It is usually trained with oracle transcripts, but needs to deal with errors by ASR. Moreover, there are acoustic features which are related with intents but not represented with the transcripts. In this paper, we present an end-to-end model which directly converts speech into dialog acts without the deterministic transcription process. In the proposed model, the dialog act recognition network is conjunct with an acoustic-to-word ASR model at its latent layer before the softmax layer, which provides a distributed representation of word-level ASR decoding information. Then, the entire network is fine-tuned in an end-to-end manner. This allows for stable training as well as robustness against ASR errors. The model is further extended to conduct DA segmentation jointly. Evaluations with the Switchboard corpus demonstrate that the proposed method significantly improves dialog act recognition accuracy from the conventional pipeline framework.
ESPnet-ST: All-in-One Speech Translation Toolkit
Apr 21, 2020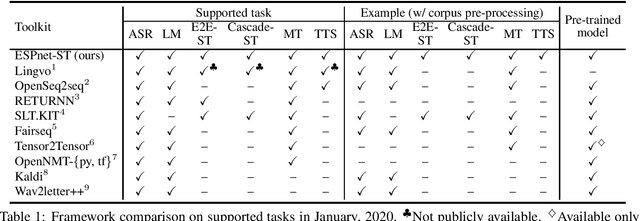
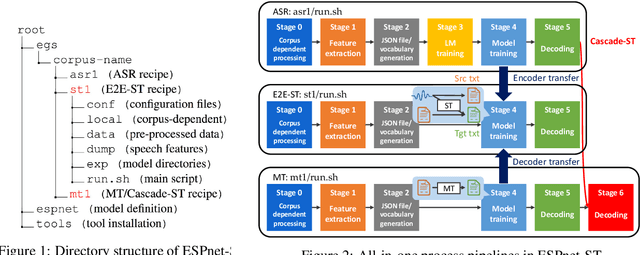


We present ESPnet-ST, which is designed for the quick development of speech-to-speech translation systems in a single framework. ESPnet-ST is a new project inside end-to-end speech processing toolkit, ESPnet, which integrates or newly implements automatic speech recognition, machine translation, and text-to-speech functions for speech translation. We provide all-in-one recipes including data pre-processing, feature extraction, training, and decoding pipelines for a wide range of benchmark datasets. Our reproducible results can match or even outperform the current state-of-the-art performances; these pre-trained models are downloadable. The toolkit is publicly available at https://github.com/espnet/espnet.
Multilingual End-to-End Speech Translation
Oct 31, 2019
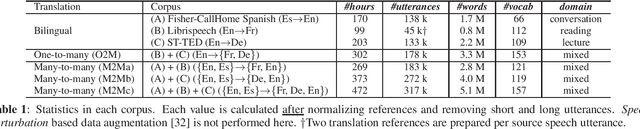
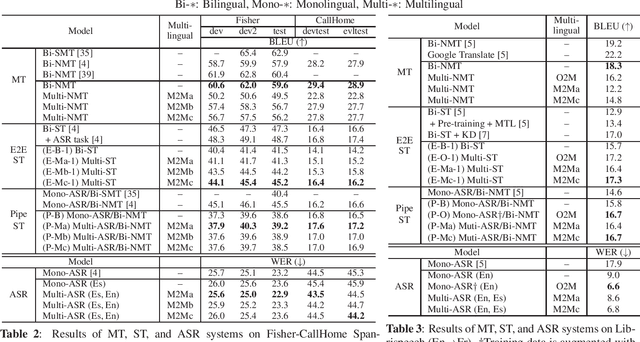
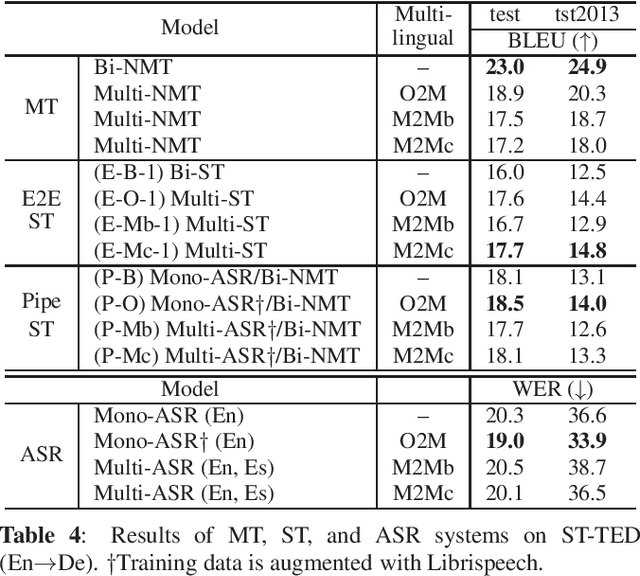
In this paper, we propose a simple yet effective framework for multilingual end-to-end speech translation (ST), in which speech utterances in source languages are directly translated to the desired target languages with a universal sequence-to-sequence architecture. While multilingual models have shown to be useful for automatic speech recognition (ASR) and machine translation (MT), this is the first time they are applied to the end-to-end ST problem. We show the effectiveness of multilingual end-to-end ST in two scenarios: one-to-many and many-to-many translations with publicly available data. We experimentally confirm that multilingual end-to-end ST models significantly outperform bilingual ones in both scenarios. The generalization of multilingual training is also evaluated in a transfer learning scenario to a very low-resource language pair. All of our codes and the database are publicly available to encourage further research in this emergent multilingual ST topic.
A Comparative Study on Transformer vs RNN in Speech Applications
Sep 28, 2019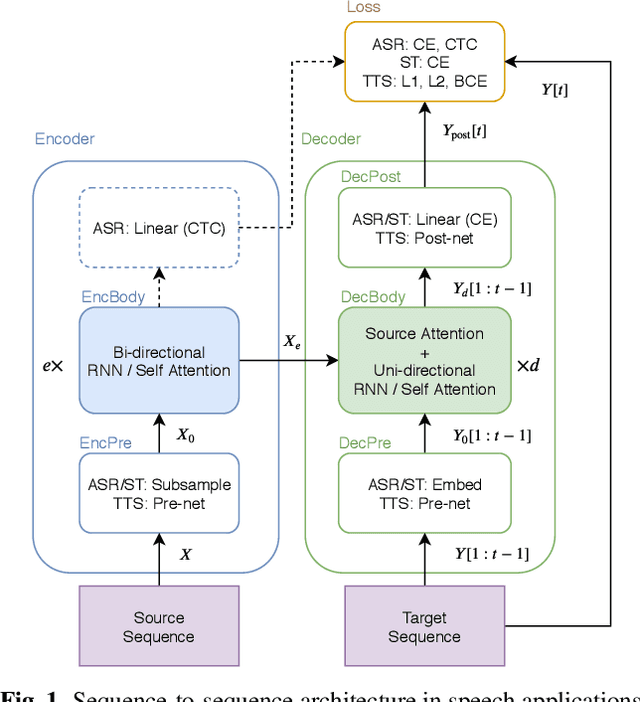
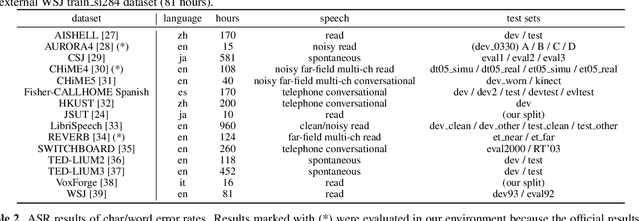
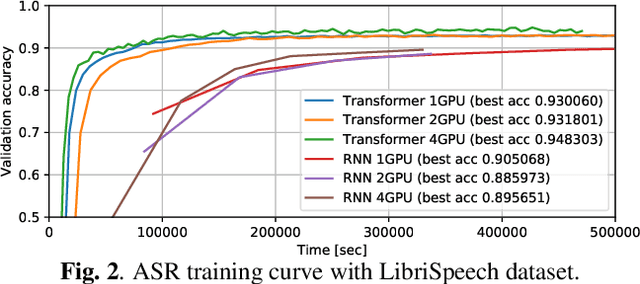
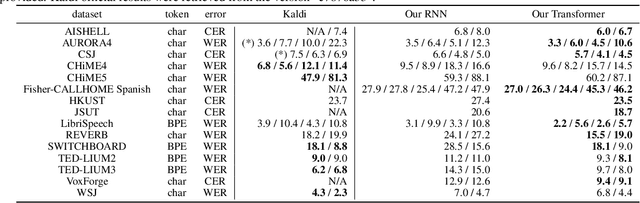
Sequence-to-sequence models have been widely used in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). This paper focuses on an emergent sequence-to-sequence model called Transformer, which achieves state-of-the-art performance in neural machine translation and other natural language processing applications. We undertook intensive studies in which we experimentally compared and analyzed Transformer and conventional recurrent neural networks (RNN) in a total of 15 ASR, one multilingual ASR, one ST, and two TTS benchmarks. Our experiments revealed various training tips and significant performance benefits obtained with Transformer for each task including the surprising superiority of Transformer in 13/15 ASR benchmarks in comparison with RNN. We are preparing to release Kaldi-style reproducible recipes using open source and publicly available datasets for all the ASR, ST, and TTS tasks for the community to succeed our exciting outcomes.
* Accepted at ASRU 2019
Improving OOV Detection and Resolution with External Language Models in Acoustic-to-Word ASR
Sep 22, 2019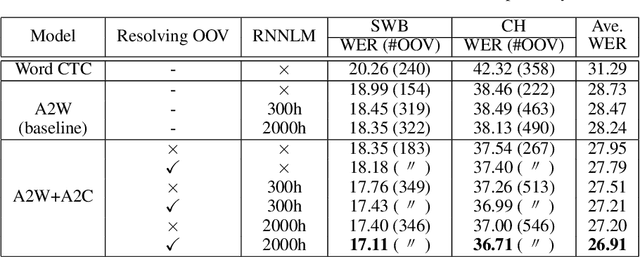
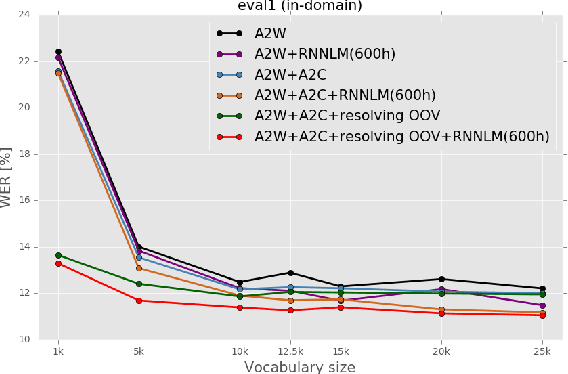
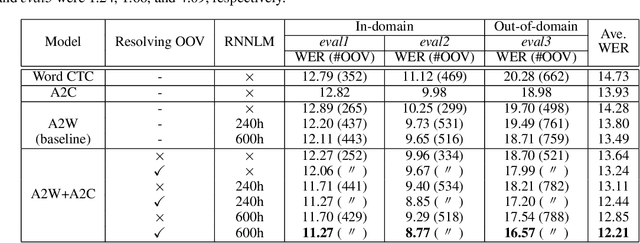
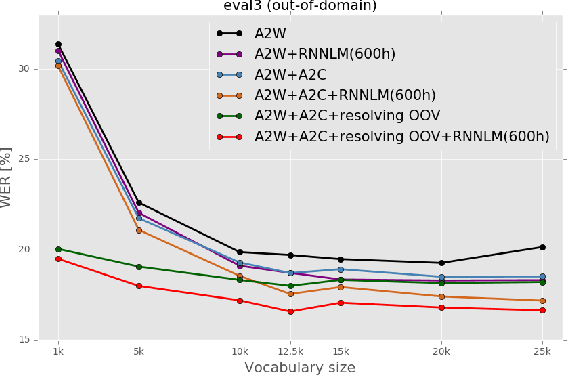
Acoustic-to-word (A2W) end-to-end automatic speech recognition (ASR) systems have attracted attention because of an extremely simplified architecture and fast decoding. To alleviate data sparseness issues due to infrequent words, the combination with an acoustic-to-character (A2C) model is investigated. Moreover, the A2C model can be used to recover out-of-vocabulary (OOV) words that are not covered by the A2W model, but this requires accurate detection of OOV words. A2W models learn contexts with both acoustic and transcripts; therefore they tend to falsely recognize OOV words as words in the vocabulary. In this paper, we tackle this problem by using external language models (LM), which are trained only with transcriptions and have better linguistic information to detect OOV words. The A2C model is used to resolve these OOV words. Experimental evaluations show that external LMs have the effects of not only reducing errors but also increasing the number of detected OOV words, and the proposed method significantly improves performances in English conversational and Japanese lecture corpora, especially for out-of-domain scenario. We also investigate the impact of the vocabulary size of A2W models and the data size for training LMs. Moreover, our approach can reduce the vocabulary size several times with marginal performance degradation.
Transfer learning of language-independent end-to-end ASR with language model fusion
Nov 06, 2018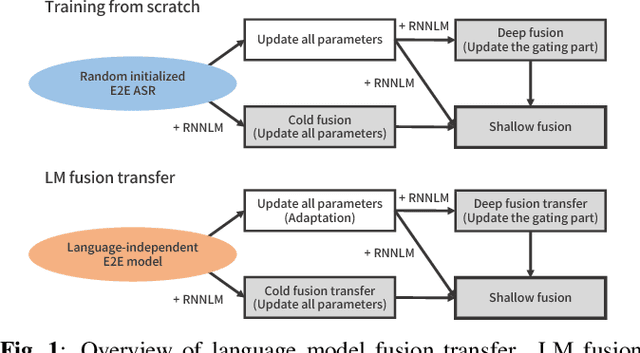
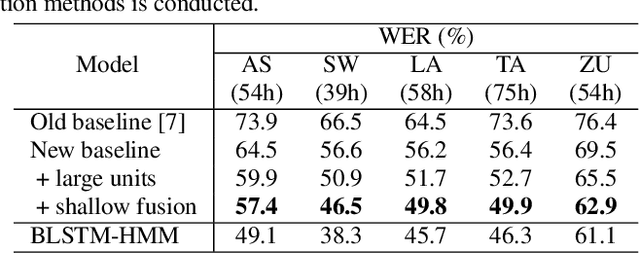
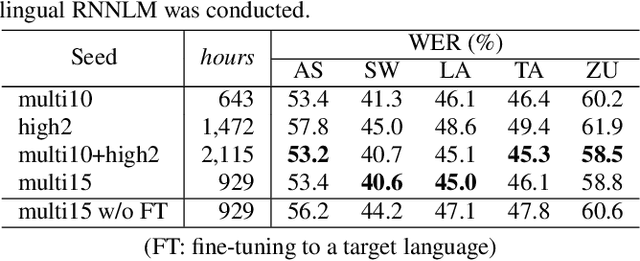
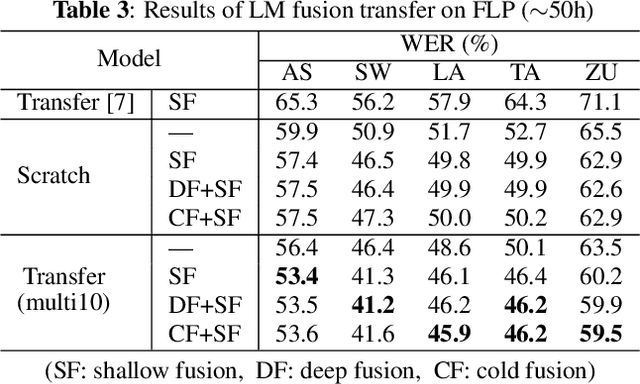
This work explores better adaptation methods to low-resource languages using an external language model (LM) under the framework of transfer learning. We first build a language-independent ASR system in a unified sequence-to-sequence (S2S) architecture with a shared vocabulary among all languages. During adaptation, we perform LM fusion transfer, where an external LM is integrated into the decoder network of the attention-based S2S model in the whole adaptation stage, to effectively incorporate linguistic context of the target language. We also investigate various seed models for transfer learning. Experimental evaluations using the IARPA BABEL data set show that LM fusion transfer improves performances on all target five languages compared with simple transfer learning when the external text data is available. Our final system drastically reduces the performance gap from the hybrid systems.