 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAD-free Streaming Hybrid CTC/Attention ASR for Unsegmented Recording
Jul 15, 2021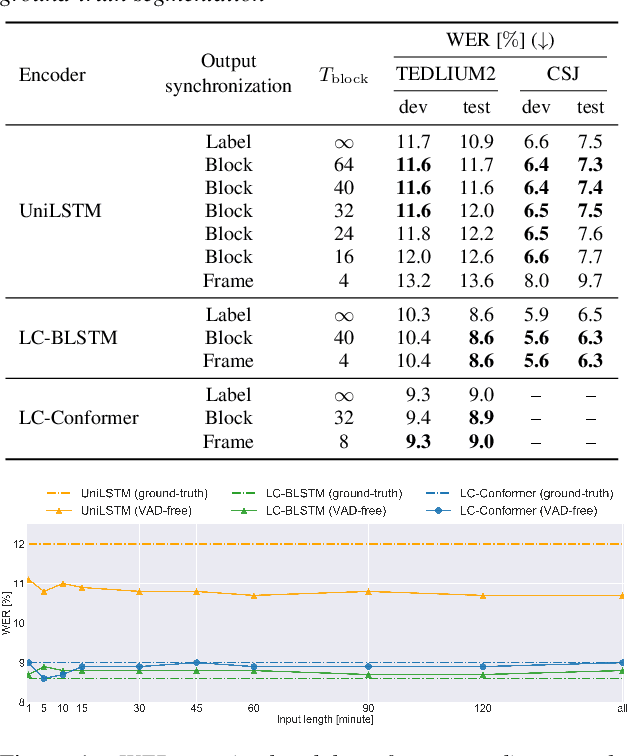
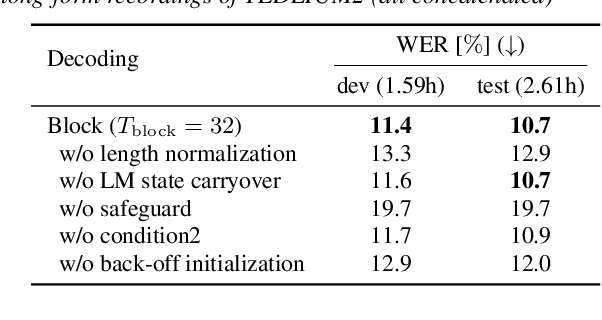
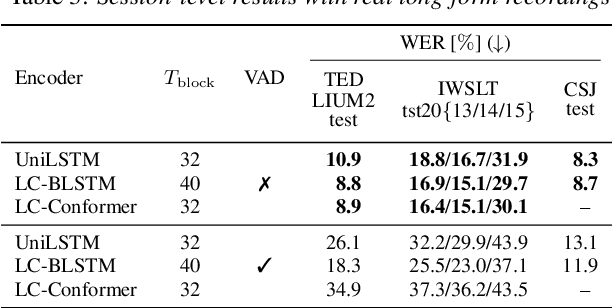
In this work, we propose novel decoding algorithms to enable streaming automatic speech recognition (ASR) on unsegmented long-form recordings without voice activity detection (VAD), based on monotonic chunkwise attention (MoChA) with an auxiliary connectionist temporal classification (CTC) objective. We propose a block-synchronous beam search decoding to take advantage of efficient batched output-synchronous and low-latency input-synchronous searches. We also propose a VAD-free inference algorithm that leverages CTC probabilities to determine a suitable timing to reset the model states to tackle the vulnerability to long-form data. Experimental evaluations demonstrate that the block-synchronous decoding achieves comparable accuracy to the label-synchronous one. Moreover, the VAD-free inference can recognize long-form speech robustly for up to a few hours.
StableEmit: Selection Probability Discount for Reducing Emission Latency of Streaming Monotonic Attention ASR
Jul 15, 2021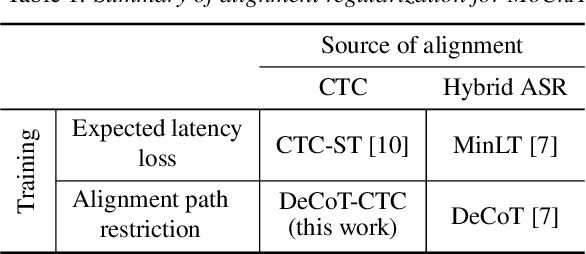
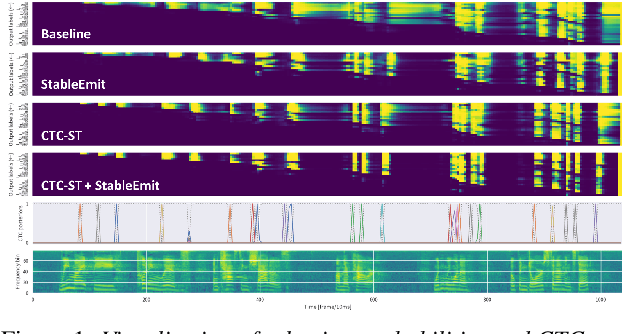

While attention-based encoder-decoder (AED) models have been successfully extended to the online variants for streaming automatic speech recognition (ASR), such as monotonic chunkwise attention (MoChA), the models still have a large label emission latency because of the unconstrained end-to-end training objective. Previous works tackled this problem by leveraging alignment information to control the timing to emit tokens during training. In this work, we propose a simple alignment-free regularization method, StableEmit, to encourage MoChA to emit tokens earlier. StableEmit discounts the selection probabilities in hard monotonic attention for token boundary detection by a constant factor and regularizes them to recover the total attention mass during training. As a result, the scale of the selection probabilities is increased, and the values can reach a threshold for token emission earlier, leading to a reduction of emission latency and deletion errors. Moreover, StableEmit can be combined with methods that constraint alignments to further improve the accuracy and latency. Experimental evaluations with LSTM and Conformer encoders demonstrate that StableEmit significantly reduces the recognition errors and the emission latency simultaneously. We also show that the use of alignment information is complementary in both metrics.
ESPnet-ST IWSLT 2021 Offline Speech Translation System
Jul 06, 2021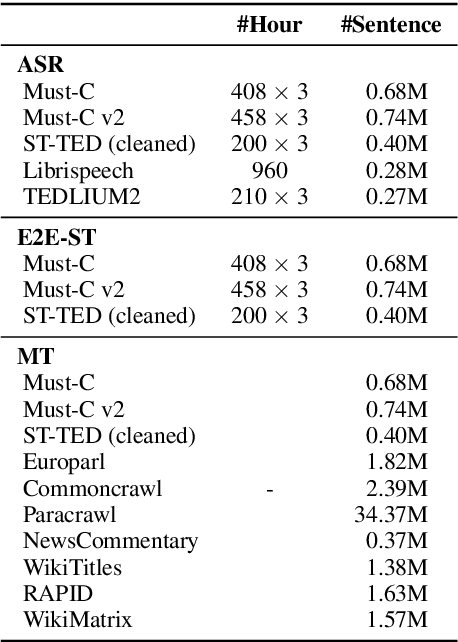
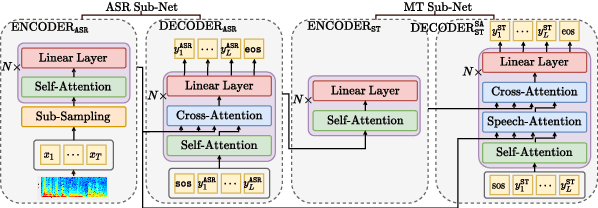
This paper describes the ESPnet-ST group's IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
Source and Target Bidirectional Knowledge Distillation for End-to-end Speech Translation
Apr 13, 2021
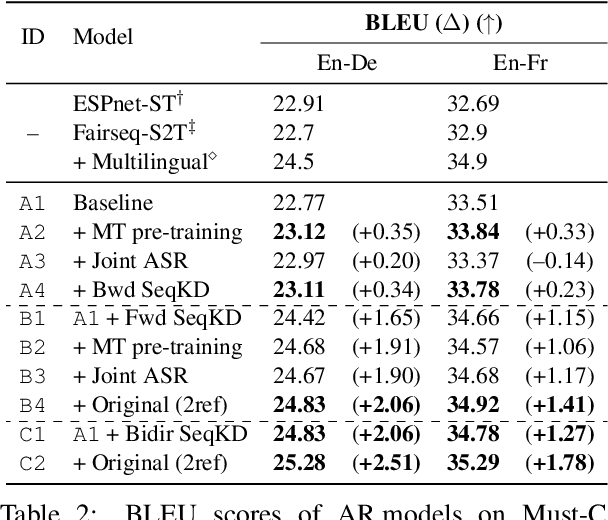
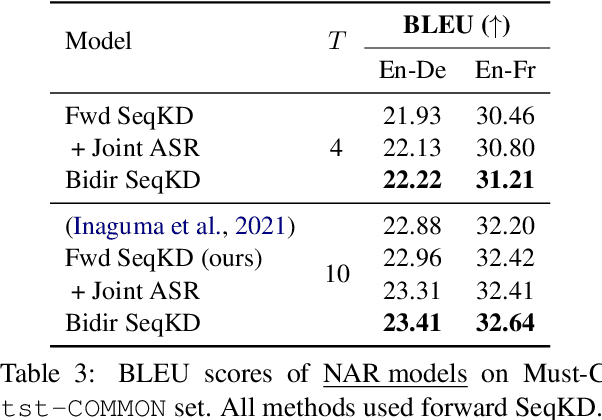
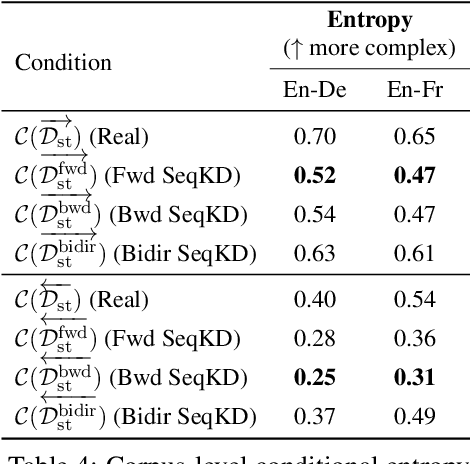
A conventional approach to improving the performance of end-to-end speech translation (E2E-ST) models is to leverage the source transcription via pre-training and joint training with automatic speech recognition (ASR) and neural machine translation (NMT) tasks. However, since the input modalities are different, it is difficult to leverage source language text successfully. In this work, we focus on sequence-level knowledge distillation (SeqKD) from external text-based NMT models. To leverage the full potential of the source language information, we propose backward SeqKD, SeqKD from a target-to-source backward NMT model. To this end, we train a bilingual E2E-ST model to predict paraphrased transcriptions as an auxiliary task with a single decoder. The paraphrases are generated from the translations in bitext via back-translation. We further propose bidirectional SeqKD in which SeqKD from both forward and backward NMT models is combined. Experimental evaluations on both autoregressive and non-autoregressive models show that SeqKD in each direction consistently improves the translation performance, and the effectiveness is complementary regardless of the model capacity.
Alignment Knowledge Distillation for Online Streaming Attention-based Speech Recognition
Feb 28, 2021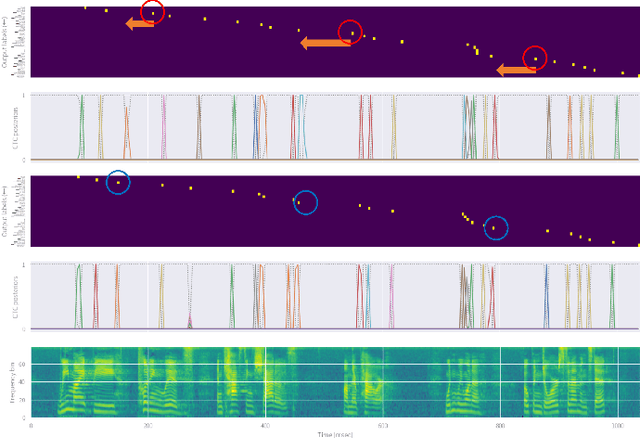
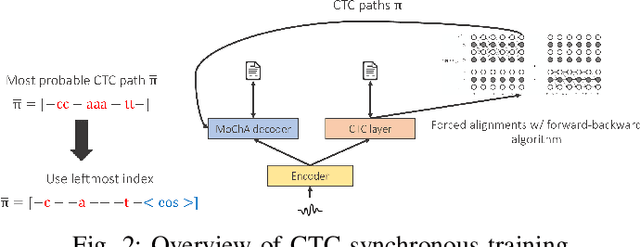
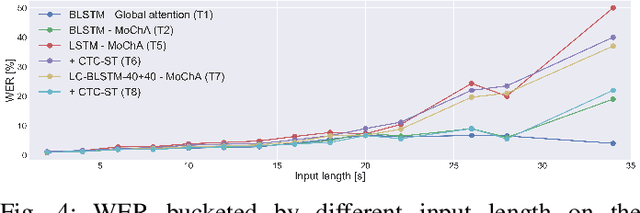
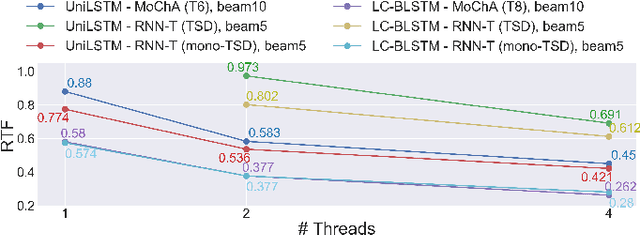
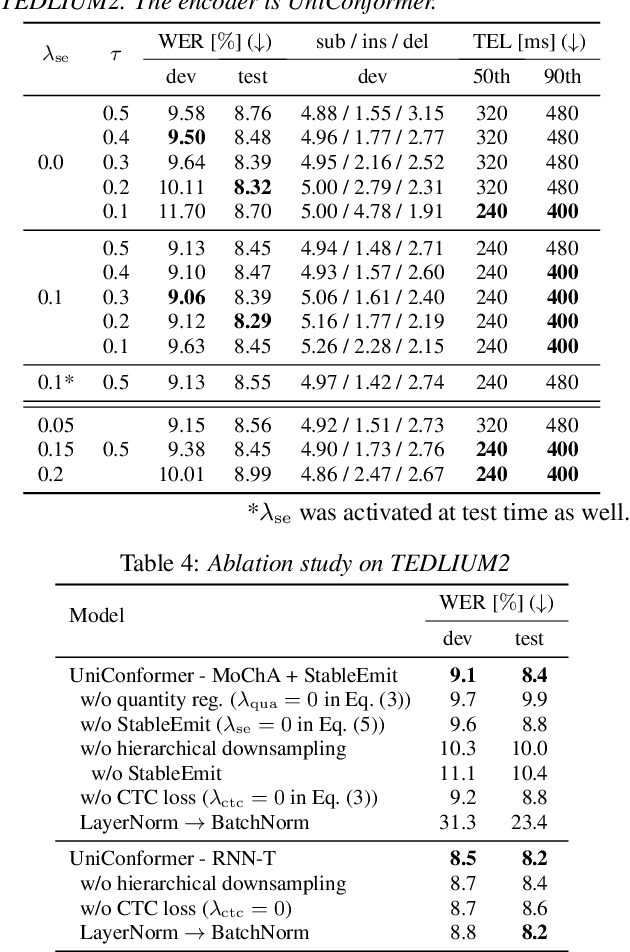
This article describes an efficient training method for online streaming attention-based encoder-decoder (AED) automatic speech recognition (ASR) systems. AED models have achieved competitive performance in offline scenarios by jointly optimizing all components. They have recently been extended to an online streaming framework via models such as monotonic chunkwise attention (MoChA). However, the elaborate attention calculation process is not robust for long-form speech utterances. Moreover, the sequence-level training objective and time-restricted streaming encoder cause a nonnegligible delay in token emission during inference. To address these problems, we propose CTC synchronous training (CTC-ST), in which CTC alignments are leveraged as a reference for token boundaries to enable a MoChA model to learn optimal monotonic input-output alignments. We formulate a purely end-to-end training objective to synchronize the boundaries of MoChA to those of CTC. The CTC model shares an encoder with the MoChA model to enhance the encoder representation. Moreover, the proposed method provides alignment information learned in the CTC branch to the attention-based decoder. Therefore, CTC-ST can be regarded as self-distillation of alignment knowledge from CTC to MoChA. Experimental evaluations on a variety of benchmark datasets show that the proposed method significantly reduces recognition errors and emission latency simultaneously, especially for long-form and noisy speech. We also compare CTC-ST with several methods that distill alignment knowledge from a hybrid ASR system and show that the CTC-ST can achieve a comparable tradeoff of accuracy and latency without relying on external alignment information. The best MoChA system shows performance comparable to that of RNN-transducer (RNN-T).
The 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Dec 23, 2020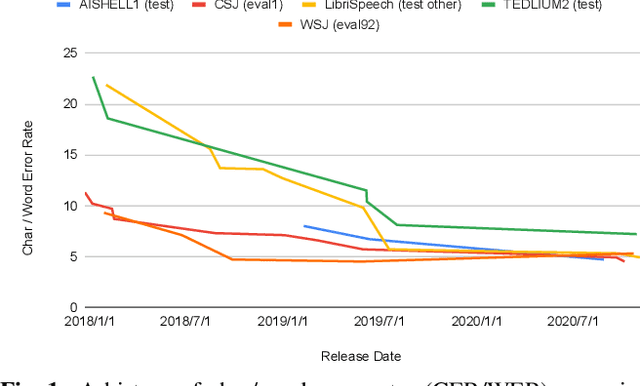

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.
Orthros: Non-autoregressive End-to-end Speech Translation with Dual-decoder
Nov 06, 2020
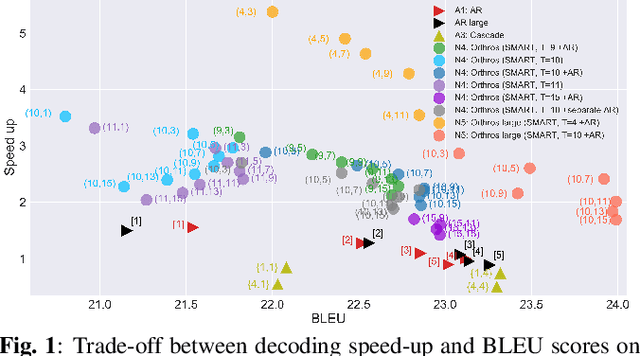
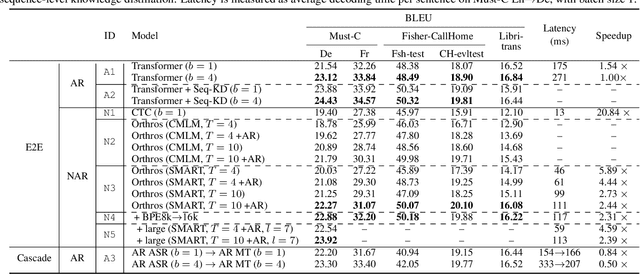
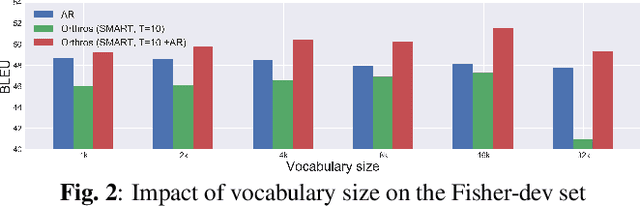
Fast inference speed is an important goal towards real-world deployment of speech translation (ST) systems. End-to-end (E2E) models based on the encoder-decoder architecture are more suitable for this goal than traditional cascaded systems, but their effectiveness regarding decoding speed has not been explored so far. Inspired by recent progress in non-autoregressive (NAR) methods in text-based translation, which generates target tokens in parallel by eliminating conditional dependencies, we study the problem of NAR decoding for E2E-ST. We propose a novel NAR E2E-ST framework, Orthoros, in which both NAR and autoregressive (AR) decoders are jointly trained on the shared speech encoder. The latter is used for selecting better translation among various length candidates generated from the former, which dramatically improves the effectiveness of a large length beam with negligible overhead. We further investigate effective length prediction methods from speech inputs and the impact of vocabulary sizes. Experiments on four benchmarks show the effectiveness of the proposed method in improving inference speed while maintaining competitive translation quality compared to state-of-the-art AR E2E-ST systems.
Improved Mask-CTC for Non-Autoregressive End-to-End ASR
Oct 26, 2020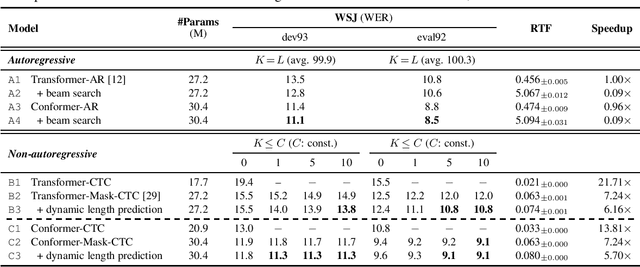
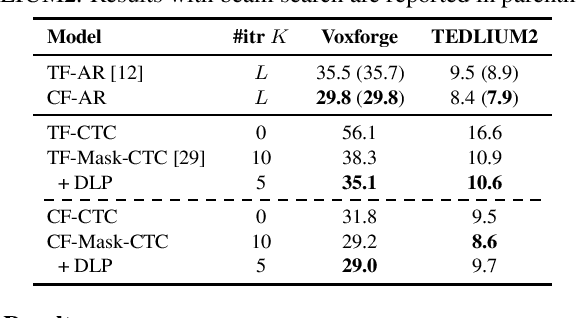
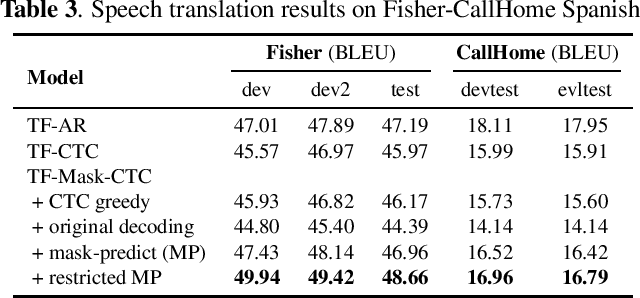
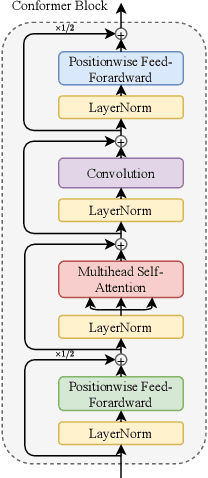
For real-world deployment of automatic speech recognition (ASR), the system is desired to be capable of fast inference while relieving the requirement of computational resources. The recently proposed end-to-end ASR system based on mask-predict with connectionist temporal classification (CTC), Mask-CTC, fulfills this demand by generating tokens in a non-autoregressive fashion. While Mask-CTC achieves remarkably fast inference speed, its recognition performance falls behind that of conventional autoregressive (AR) systems. To boost the performance of Mask-CTC, we first propose to enhance the encoder network architecture by employing a recently proposed architecture called Conformer. Next, we propose new training and decoding methods by introducing auxiliary objective to predict the length of a partial target sequence, which allows the model to delete or insert tokens during inference. Experimental results on different ASR tasks show that the proposed approaches improve Mask-CTC significantly, outperforming a standard CTC model (15.5% $\rightarrow$ 9.1% WER on WSJ). Moreover, Mask-CTC now achieves competitive results to AR models with no degradation of inference speed ($<$ 0.1 RTF using CPU). We also show a potential application of Mask-CTC to end-to-end speech translation.
Distilling the Knowledge of BERT for Sequence-to-Sequence ASR
Aug 09, 2020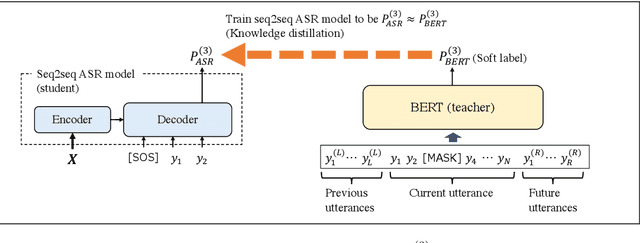
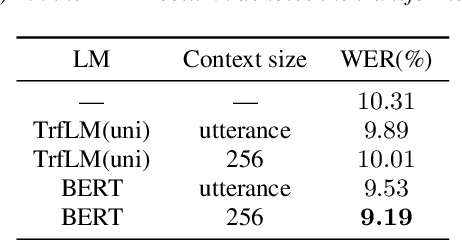
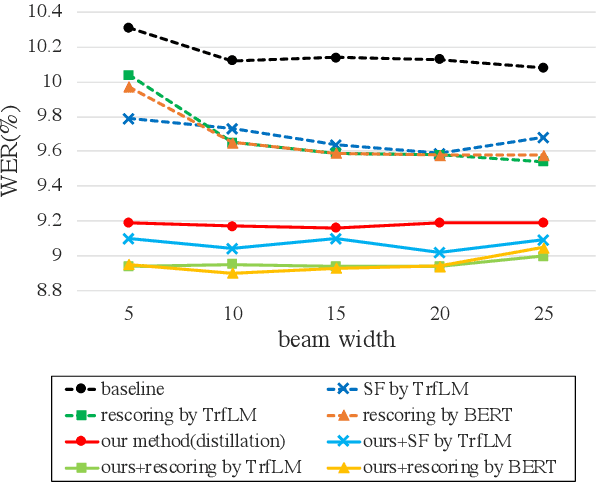
Attention-based sequence-to-sequence (seq2seq) models have achieved promising results in automatic speech recognition (ASR). However, as these models decode in a left-to-right way, they do not have access to context on the right. We leverage both left and right context by applying BERT as an external language model to seq2seq ASR through knowledge distillation. In our proposed method, BERT generates soft labels to guide the training of seq2seq ASR. Furthermore, we leverage context beyond the current utterance as input to BERT. Experimental evaluations show that our method significantly improves the ASR performance from the seq2seq baseline on the Corpus of Spontaneous Japanese (CSJ). Knowledge distillation from BERT outperforms that from a transformer LM that only looks at left context. We also show the effectiveness of leveraging context beyond the current utterance. Our method outperforms other LM application approaches such as n-best rescoring and shallow fusion, while it does not require extra inference cost.
Enhancing Monotonic Multihead Attention for Streaming ASR
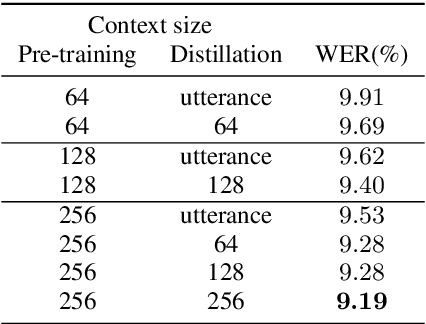
May 23, 2020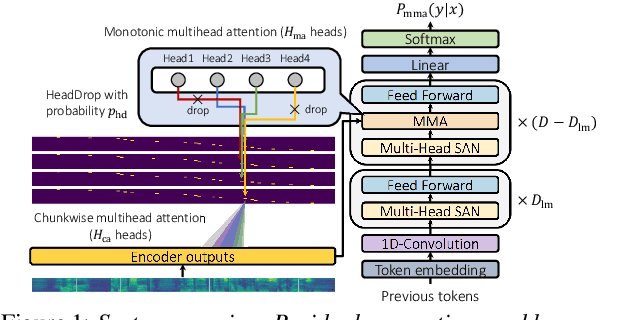
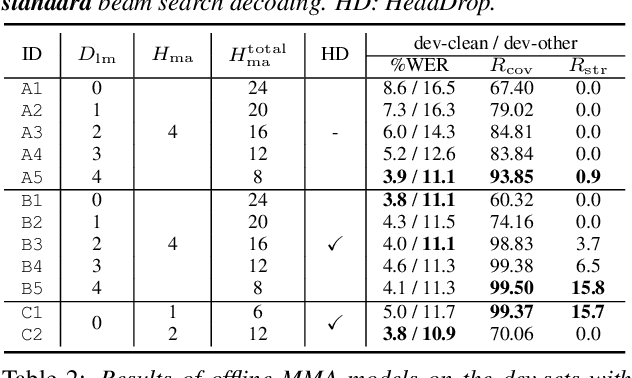
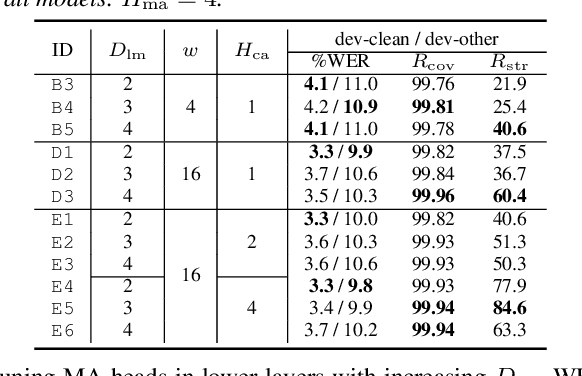
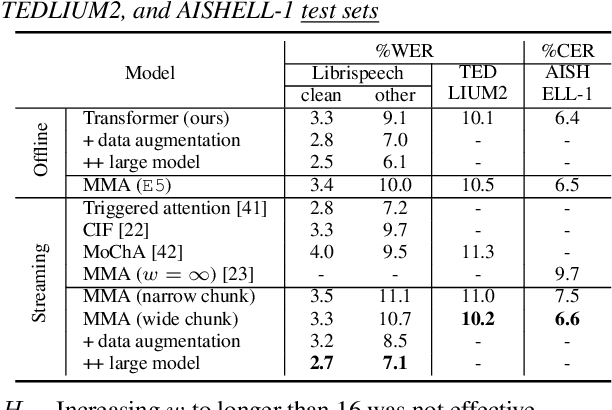
We investigate a monotonic multihead attention (MMA) by extending hard monotonic attention to Transformer-based automatic speech recognition (ASR) for online streaming applications. For streaming inference, all monotonic attention (MA) heads should learn proper alignments because the next token is not generated until all heads detect the corresponding token boundaries. However, we found not all MA heads learn alignments with a naive implementation. To encourage every head to learn alignments properly, we propose HeadDrop regularization by masking out a part of heads stochastically during training. Furthermore, we propose to prune redundant heads to improve consensus among heads for boundary detection and prevent delayed token generation caused by such heads. Chunkwise attention on each MA head is extended to the multihead counterpart. Finally, we propose head-synchronous beam search decoding to guarantee stable streaming inference.