 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableEmit: Selection Probability Discount for Reducing Emission Latency of Streaming Monotonic Attention ASR
Paper and Code
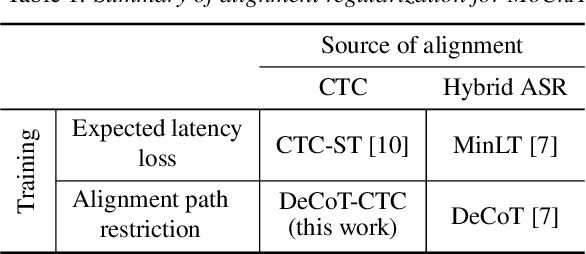
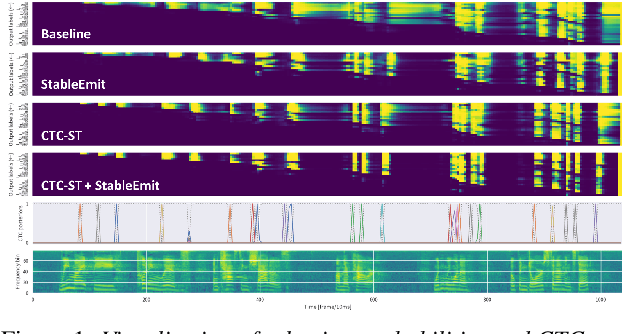

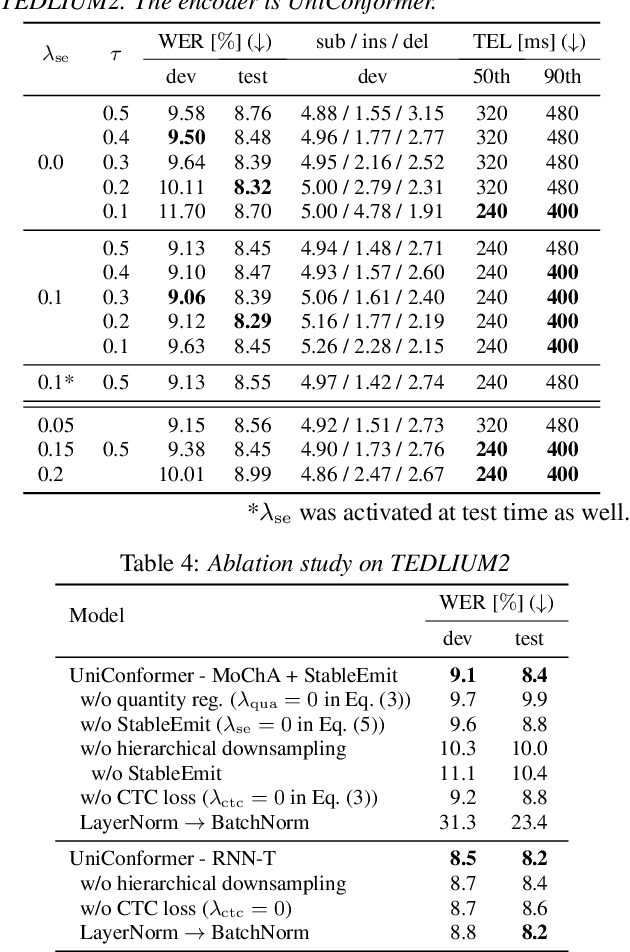
While attention-based encoder-decoder (AED) models have been successfully extended to the online variants for streaming automatic speech recognition (ASR), such as monotonic chunkwise attention (MoChA), the models still have a large label emission latency because of the unconstrained end-to-end training objective. Previous works tackled this problem by leveraging alignment information to control the timing to emit tokens during training. In this work, we propose a simple alignment-free regularization method, StableEmit, to encourage MoChA to emit tokens earlier. StableEmit discounts the selection probabilities in hard monotonic attention for token boundary detection by a constant factor and regularizes them to recover the total attention mass during training. As a result, the scale of the selection probabilities is increased, and the values can reach a threshold for token emission earlier, leading to a reduction of emission latency and deletion errors. Moreover, StableEmit can be combined with methods that constraint alignments to further improve the accuracy and latency. Experimental evaluations with LSTM and Conformer encoders demonstrate that StableEmit significantly reduces the recognition errors and the emission latency simultaneously. We also show that the use of alignment information is complementary in both metrics.