 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Dec 15, 2022Direct speech-to-speech translation (S2ST), in which all components can be optimized jointly, is advantageous over cascaded approaches to achieve fast inference with a simplified pipeline. We present a novel two-pass direct S2ST architecture, {\textit UnitY}, which first generates textual representations and predicts discrete acoustic units subsequently. We enhance the model performance by subword prediction in the first-pass decoder, advanced two-pass decoder architecture design and search strategy, and better training regularization. To leverage large amounts of unlabeled text data, we pre-train the first-pass text decoder based on the self-supervised denoising auto-encoding task. Experimental evaluations on benchmark datasets at various data scales demonstrate that UnitY outperforms a single-pass speech-to-unit translation model by 2.5-4.2 ASR-BLEU with 2.83x decoding speed-up. We show that the proposed methods boost the performance even when predicting spectrogram in the second pass. However, predicting discrete units achieves 2.51x decoding speed-up compared to that case.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022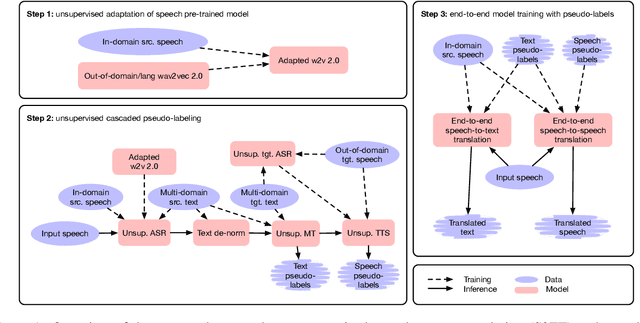
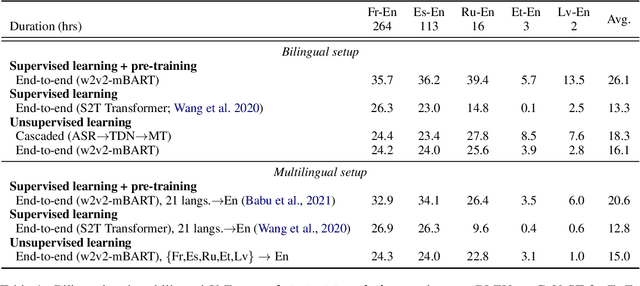
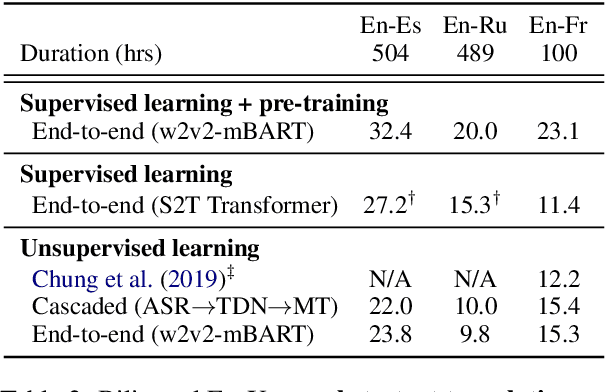
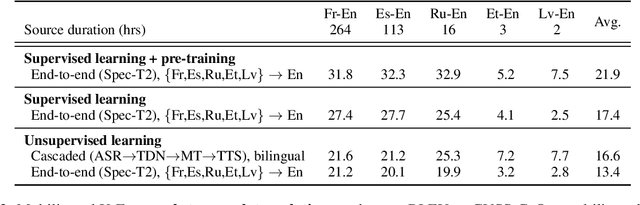
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022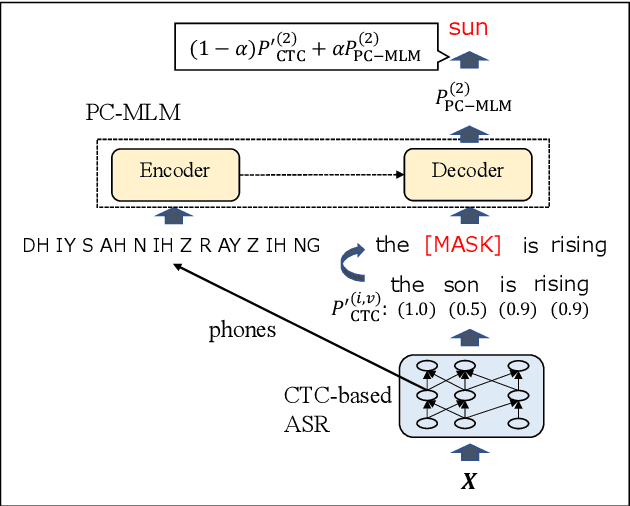
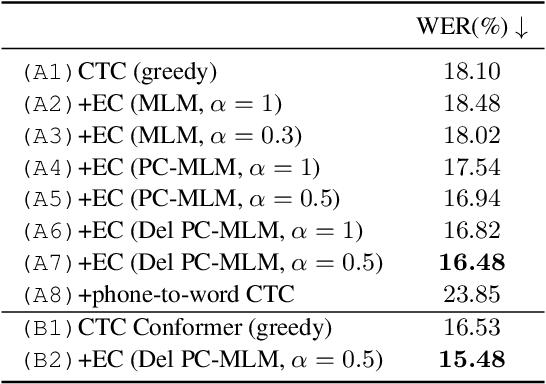
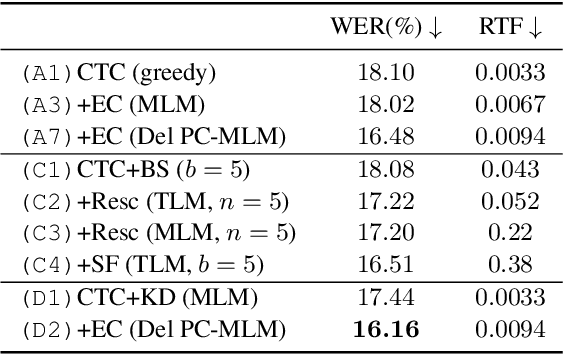
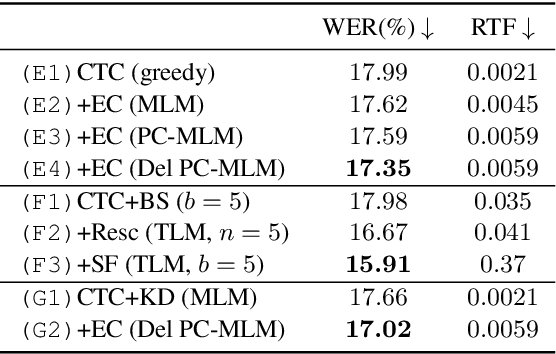
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022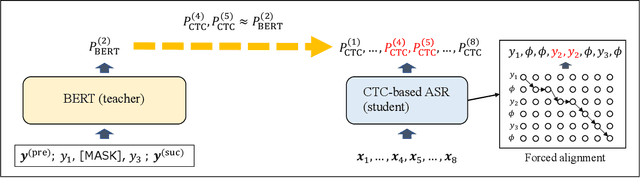
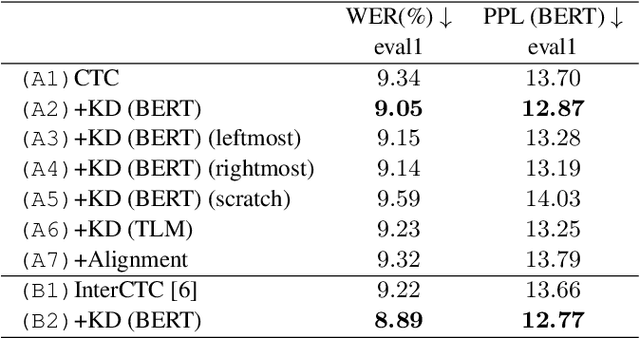
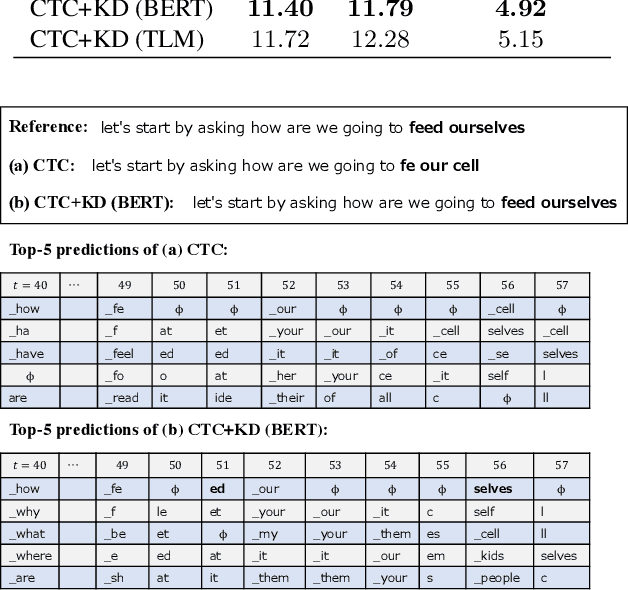
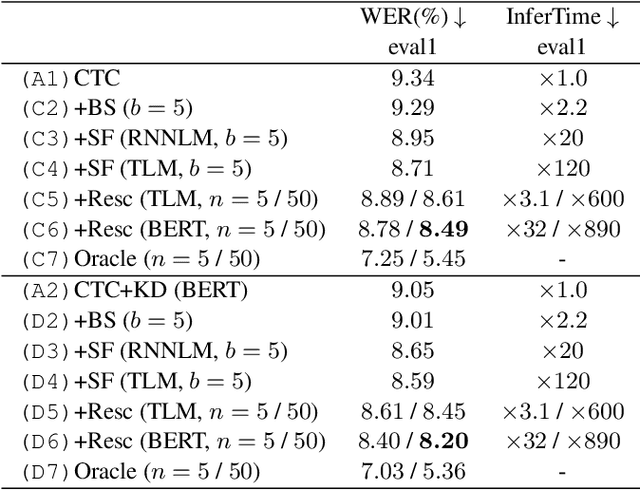
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
A Study of Transducer based End-to-End ASR with ESPnet: Architecture, Auxiliary Loss and Decoding Strategies
Jan 14, 2022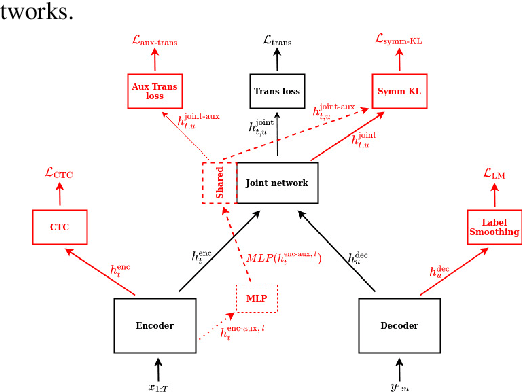
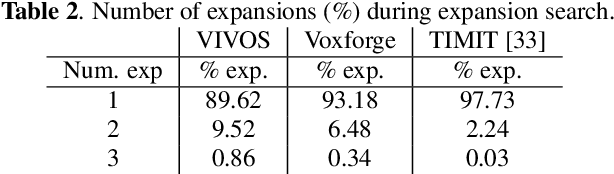
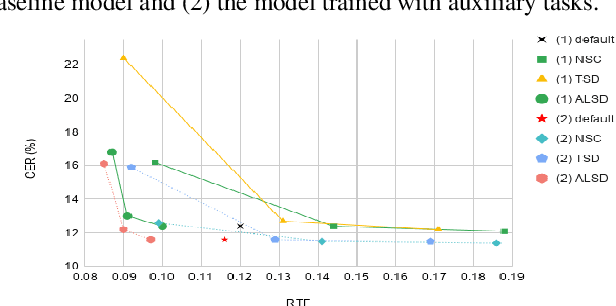
In this study, we present recent developments of models trained with the RNN-T loss in ESPnet. It involves the use of various architectures such as recently proposed Conformer, multi-task learning with different auxiliary criteria and multiple decoding strategies, including our own proposition. Through experiments and benchmarks, we show that our proposed systems can be competitive against other state-of-art systems on well-known datasets such as LibriSpeech and AISHELL-1. Additionally, we demonstrate that these models are promising against other already implemented systems in ESPnet in regards to both performance and decoding speed, enabling the possibility to have powerful systems for a streaming task. With these additions, we hope to expand the usefulness of the ESPnet toolkit for the research community and also give tools for the ASR industry to deploy our systems in realistic and production environments.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021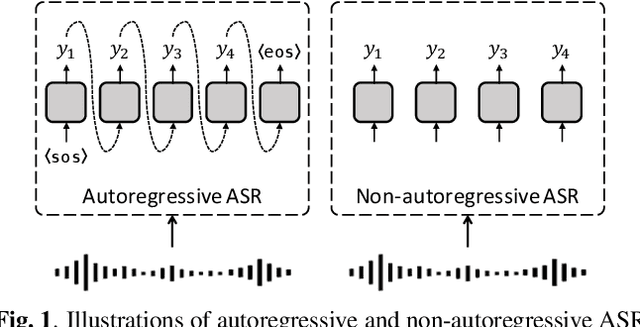

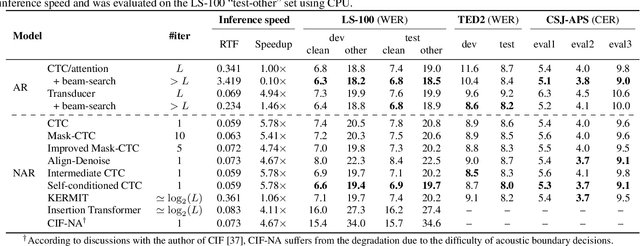
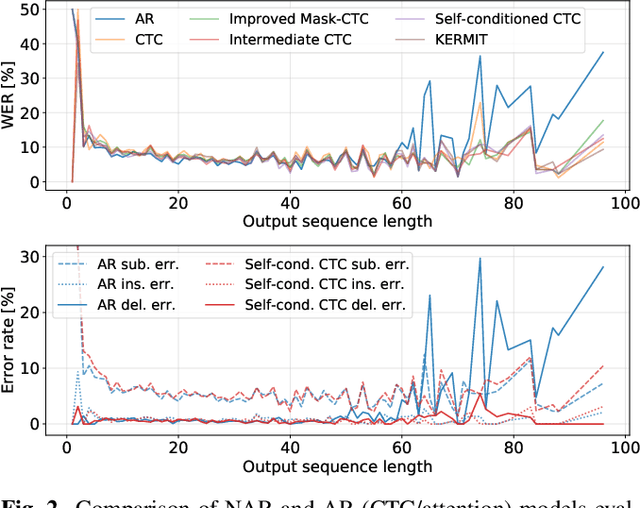
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
ASR Rescoring and Confidence Estimation with ELECTRA
Oct 05, 2021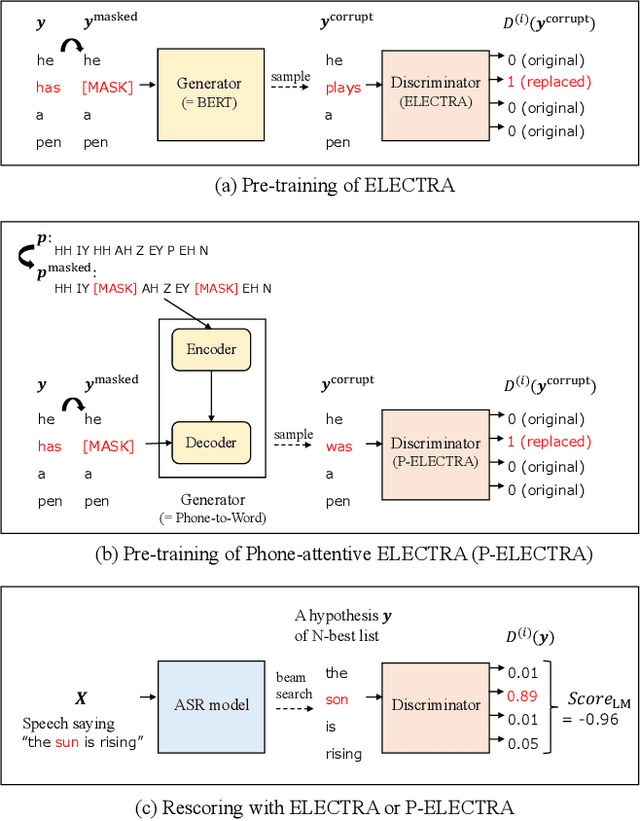

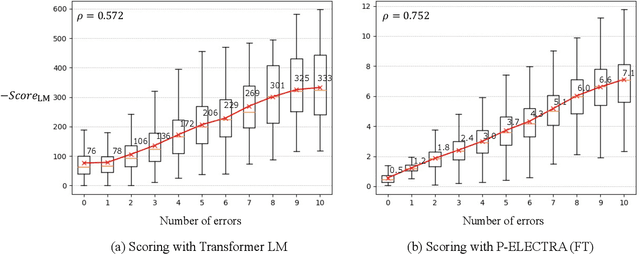
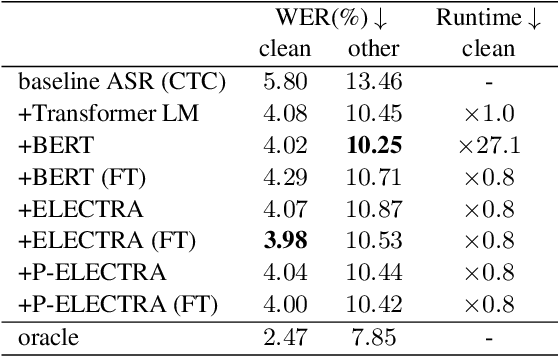
In automatic speech recognition (ASR) rescoring, the hypothesis with the fewest errors should be selected from the n-best list using a language model (LM). However, LMs are usually trained to maximize the likelihood of correct word sequences, not to detect ASR errors. We propose an ASR rescoring method for directly detecting errors with ELECTRA, which is originally a pre-training method for NLP tasks. ELECTRA is pre-trained to predict whether each word is replaced by BERT or not, which can simulate ASR error detection on large text corpora. To make this pre-training closer to ASR error detection, we further propose an extended version of ELECTRA called phone-attentive ELECTRA (P-ELECTRA). In the pre-training of P-ELECTRA, each word is replaced by a phone-to-word conversion model, which leverages phone information to generate acoustically similar words. Since our rescoring method is optimized for detecting errors, it can also be used for word-level confidence estimation. Experimental evaluations on the Librispeech and TED-LIUM2 corpora show that our rescoring method with ELECTRA is competitive with conventional rescoring methods with faster inference. ELECTRA also performs better in confidence estimation than BERT because it can learn to detect inappropriate words not only in fine-tuning but also in pre-training.
Fast-MD: Fast Multi-Decoder End-to-End Speech Translation with Non-Autoregressive Hidden Intermediates
Sep 27, 2021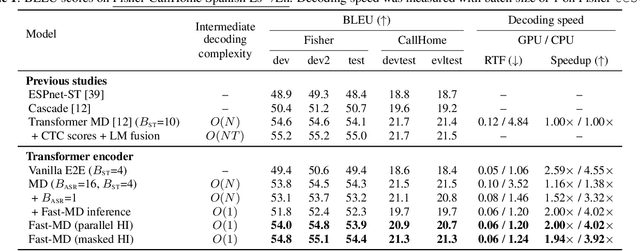
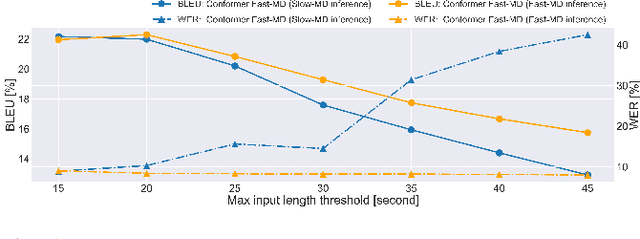
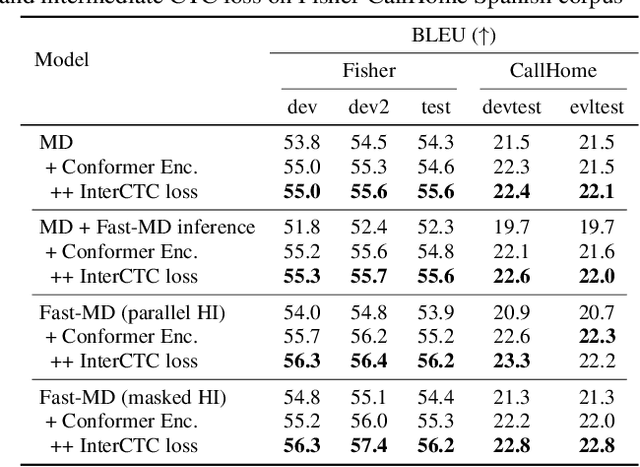
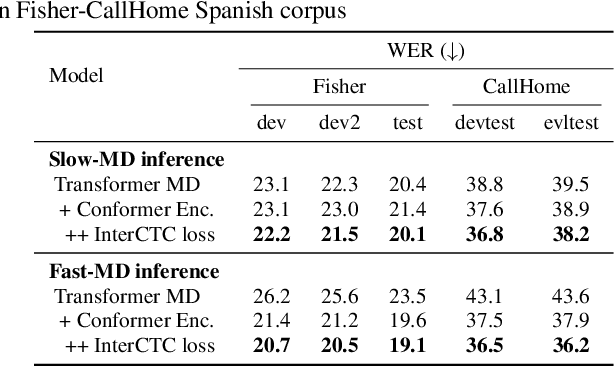
The multi-decoder (MD) end-to-end speech translation model has demonstrated high translation quality by searching for better intermediate automatic speech recognition (ASR) decoder states as hidden intermediates (HI). It is a two-pass decoding model decomposing the overall task into ASR and machine translation sub-tasks. However, the decoding speed is not fast enough for real-world applications because it conducts beam search for both sub-tasks during inference. We propose Fast-MD, a fast MD model that generates HI by non-autoregressive (NAR) decoding based on connectionist temporal classification (CTC) outputs followed by an ASR decoder. We investigated two types of NAR HI: (1) parallel HI by using an autoregressive Transformer ASR decoder and (2) masked HI by using Mask-CTC, which combines CTC and the conditional masked language model. To reduce a mismatch in the ASR decoder between teacher-forcing during training and conditioning on CTC outputs during testing, we also propose sampling CTC outputs during training. Experimental evaluations on three corpora show that Fast-MD achieved about 2x and 4x faster decoding speed than that of the na\"ive MD model on GPU and CPU with comparable translation quality. Adopting the Conformer encoder and intermediate CTC loss further boosts its quality without sacrificing decoding speed.
Non-autoregressive End-to-end Speech Translation with Parallel Autoregressive Rescoring
Sep 09, 2021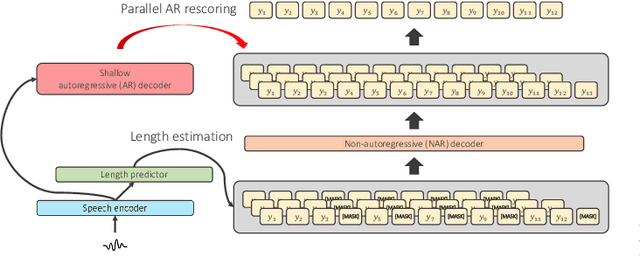
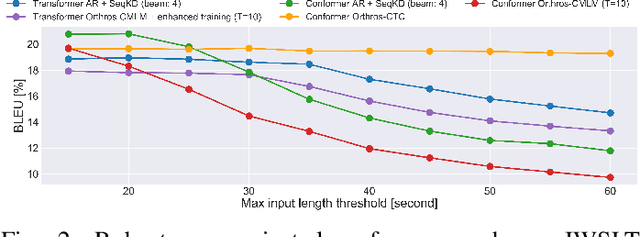
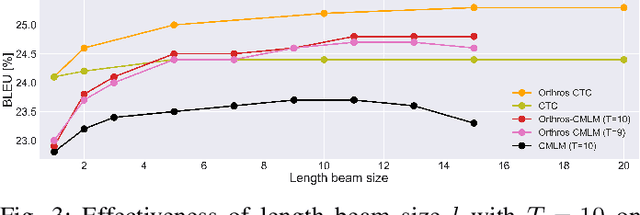
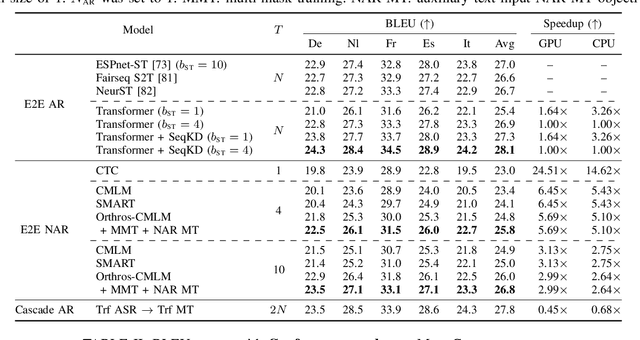
This article describes an efficient end-to-end speech translation (E2E-ST) framework based on non-autoregressive (NAR) models. End-to-end speech translation models have several advantages over traditional cascade systems such as inference latency reduction. However, conventional AR decoding methods are not fast enough because each token is generated incrementally. NAR models, however, can accelerate the decoding speed by generating multiple tokens in parallel on the basis of the token-wise conditional independence assumption. We propose a unified NAR E2E-ST framework called Orthros, which has an NAR decoder and an auxiliary shallow AR decoder on top of the shared encoder. The auxiliary shallow AR decoder selects the best hypothesis by rescoring multiple candidates generated from the NAR decoder in parallel (parallel AR rescoring). We adopt conditional masked language model (CMLM) and a connectionist temporal classification (CTC)-based model as NAR decoders for Orthros, referred to as Orthros-CMLM and Orthros-CTC, respectively. We also propose two training methods to enhance the CMLM decoder. Experimental evaluations on three benchmark datasets with six language directions demonstrated that Orthros achieved large improvements in translation quality with a very small overhead compared with the baseline NAR model. Moreover, the Conformer encoder architecture enabled large quality improvements, especially for CTC-based models. Orthros-CTC with the Conformer encoder increased decoding speed by 3.63x on CPU with translation quality comparable to that of an AR model.