 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Counting of Stacked Objects in Industrial Inspection
Mar 16, 2026Visual object counting is a fundamental computer vision task in industrial inspection, where accurate, high-throughput inventory tracking and quality assurance are critical. Moreover, manufactured parts are often too light to reliably deduce their count from their weight, or too heavy to move the stack on a scale safely and practically, making automated visual counting the more robust solution in many scenarios. However, existing methods struggle with stacked 3D items in containers, pallets, or bins, where most objects are heavily occluded and only a few are directly visible. To address this important yet underexplored challenge, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems: estimating the 3D geometry of the stack and its occupancy ratio from multi-view images. By combining geometric reconstruction with deep learning-based depth analysis, our method can accurately count identical manufactured parts inside containers, even when they are irregularly stacked and partially hidden. We validate our 3D counting pipeline on large-scale synthetic and diverse real-world data with manually verified total counts, demonstrating robust performance under realistic inspection conditions.
Counting Stacked Objects from Multi-View Images
Nov 28, 2024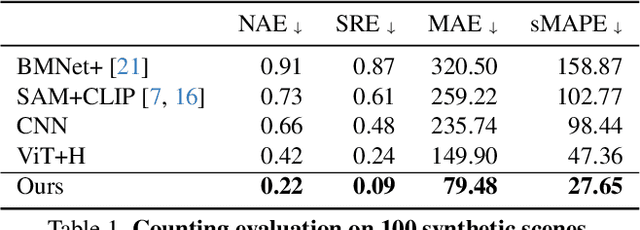
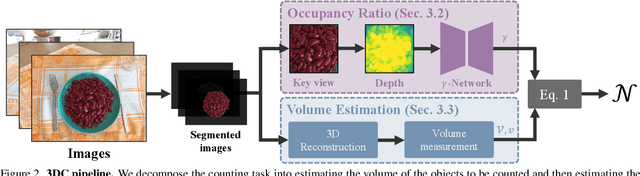
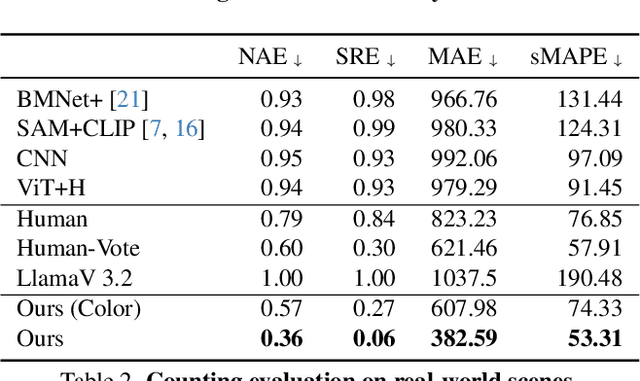

Visual object counting is a fundamental computer vision task underpinning numerous real-world applications, from cell counting in biomedicine to traffic and wildlife monitoring. However, existing methods struggle to handle the challenge of stacked 3D objects in which most objects are hidden by those above them. To address this important yet underexplored problem, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems - estimating the 3D geometry of the object stack and the occupancy ratio from multi-view images. By combining geometric reconstruction and deep learning-based depth analysis, our method can accurately count identical objects within containers, even when they are irregularly stacked. We validate our 3D Counting pipeline on diverse real-world and large-scale synthetic datasets, which we will release publicly to facilitate further research.