 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Weight Parameters for Data Attribution
Paper and Code
Jun 06, 2025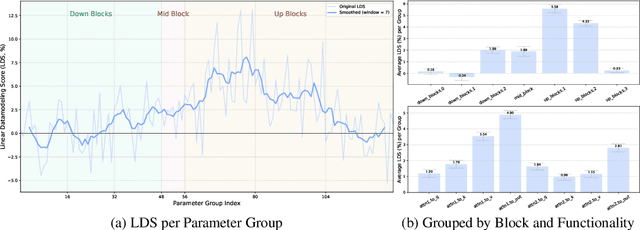

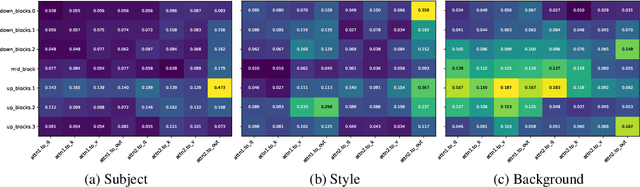
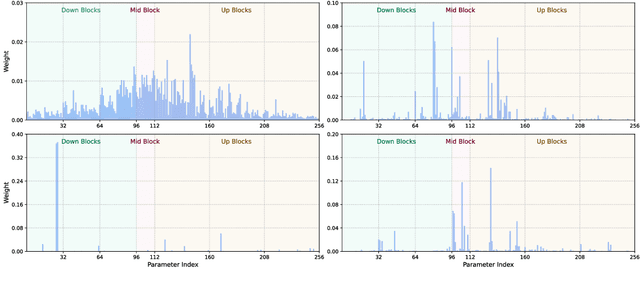
We study data attribution in generative models, aiming to identify which training examples most influence a given output. Existing methods achieve this by tracing gradients back to training data. However, they typically treat all network parameters uniformly, ignoring the fact that different layers encode different types of information and may thus draw information differently from the training set. We propose a method that models this by learning parameter importance weights tailored for attribution, without requiring labeled data. This allows the attribution process to adapt to the structure of the model, capturing which training examples contribute to specific semantic aspects of an output, such as subject, style, or background. Our method improves attribution accuracy across diffusion models and enables fine-grained insights into how outputs borrow from training data.