 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Liquids in Real-world Images
Jan 02, 2026Different types of liquids such as water, wine and medicine appear in all aspects of daily life. However, limited attention has been given to the task, hindering the ability of robots to avoid or interact with liquids safely. The segmentation of liquids is difficult because liquids come in diverse appearances and shapes; moreover, they can be both transparent or reflective, taking on arbitrary objects and scenes from the background or surroundings. To take on this challenge, we construct a large-scale dataset of liquids named LQDS consisting of 5000 real-world images annotated into 14 distinct classes, and design a novel liquid detection model named LQDM, which leverages cross-attention between a dedicated boundary branch and the main segmentation branch to enhance segmentation predictions. Extensive experiments demonstrate the effectiveness of LQDM on the test set of LQDS, outperforming state-of-the-art methods and establishing a strong baseline for the semantic segmentation of liquids.
OLC-WA: Drift Aware Tuning-Free Online Classification with Weighted Average
Dec 14, 2025
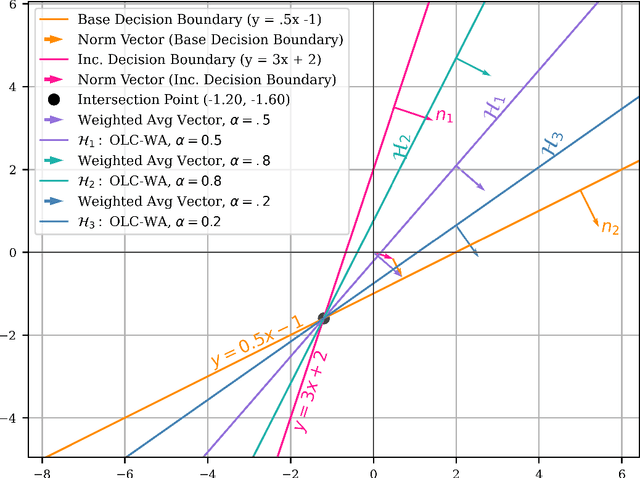

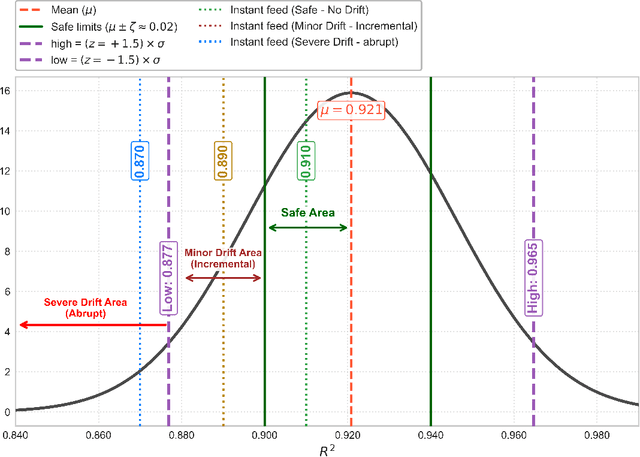
Real-world data sets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. This paper introduces Online Classification with Weighted Average (OLC-WA), an adaptive, hyperparameter-free online classification model equipped with an automated optimization mechanism. OLC-WA operates by blending incoming data streams with an existing base model. This blending is facilitated by an exponentially weighted moving average. Furthermore, an integrated optimization mechanism dynamically detects concept drift, quantifies its magnitude, and adjusts the model based on the observed data stream characteristics. This approach empowers the model to effectively adapt to evolving data distributions within streaming environments. Rigorous empirical evaluation across diverse benchmark datasets shows that OLC-WA achieves performance comparable to batch models in stationary environments, maintaining accuracy within 1-3%, and surpasses leading online baselines by 10-25% under drift, demonstrating its effectiveness in adapting to dynamic data streams.
Hybrid Quantum-Classical Neural Networks for Few-Shot Credit Risk Assessment
Sep 17, 2025Quantum Machine Learning (QML) offers a new paradigm for addressing complex financial problems intractable for classical methods. This work specifically tackles the challenge of few-shot credit risk assessment, a critical issue in inclusive finance where data scarcity and imbalance limit the effectiveness of conventional models. To address this, we design and implement a novel hybrid quantum-classical workflow. The methodology first employs an ensemble of classical machine learning models (Logistic Regression, Random Forest, XGBoost) for intelligent feature engineering and dimensionality reduction. Subsequently, a Quantum Neural Network (QNN), trained via the parameter-shift rule, serves as the core classifier. This framework was evaluated through numerical simulations and deployed on the Quafu Quantum Cloud Platform's ScQ-P21 superconducting processor. On a real-world credit dataset of 279 samples, our QNN achieved a robust average AUC of 0.852 +/- 0.027 in simulations and yielded an impressive AUC of 0.88 in the hardware experiment. This performance surpasses a suite of classical benchmarks, with a particularly strong result on the recall metric. This study provides a pragmatic blueprint for applying quantum computing to data-constrained financial scenarios in the NISQ era and offers valuable empirical evidence supporting its potential in high-stakes applications like inclusive finance.
IRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
G3CN: Gaussian Topology Refinement Gated Graph Convolutional Network for Skeleton-Based Action Recognition
Sep 09, 2025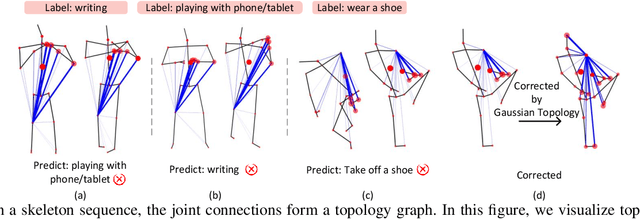
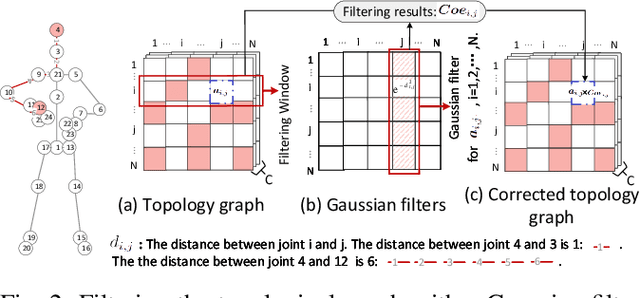
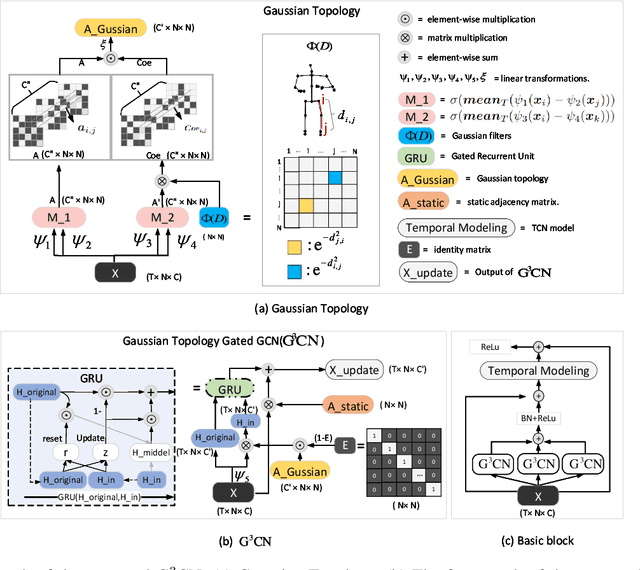
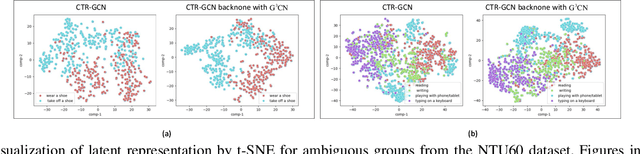
Graph Convolutional Networks (GCNs) have proven to be highly effective for skeleton-based action recognition, primarily due to their ability to leverage graph topology for feature aggregation, a key factor in extracting meaningful representations. However, despite their success, GCNs often struggle to effectively distinguish between ambiguous actions, revealing limitations in the representation of learned topological and spatial features. To address this challenge, we propose a novel approach, Gaussian Topology Refinement Gated Graph Convolution (G$^{3}$CN), to address the challenge of distinguishing ambiguous actions in skeleton-based action recognition. G$^{3}$CN incorporates a Gaussian filter to refine the skeleton topology graph, improving the representation of ambiguous actions. Additionally, Gated Recurrent Units (GRUs) are integrated into the GCN framework to enhance information propagation between skeleton points. Our method shows strong generalization across various GCN backbones. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA benchmarks demonstrate that G$^{3}$CN effectively improves action recognition, particularly for ambiguous samples.
CGTrack: Cascade Gating Network with Hierarchical Feature Aggregation for UAV Tracking
May 09, 2025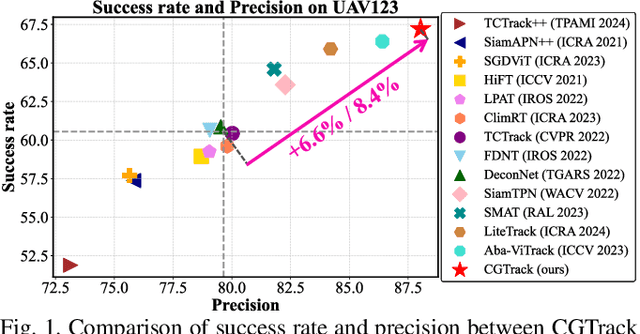
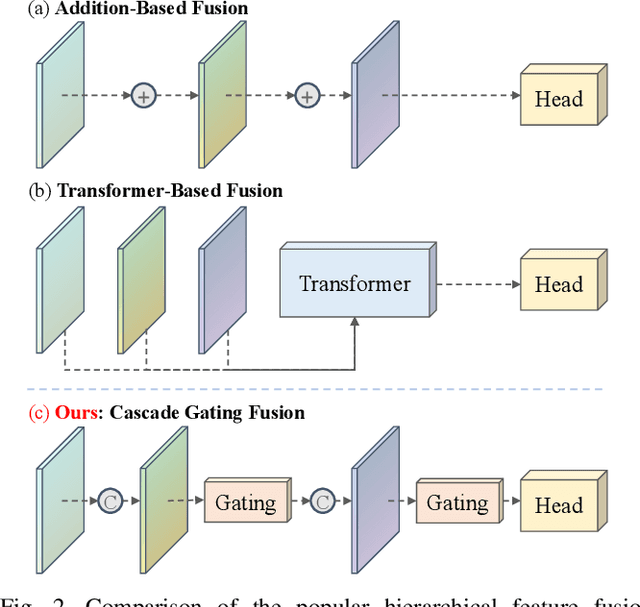
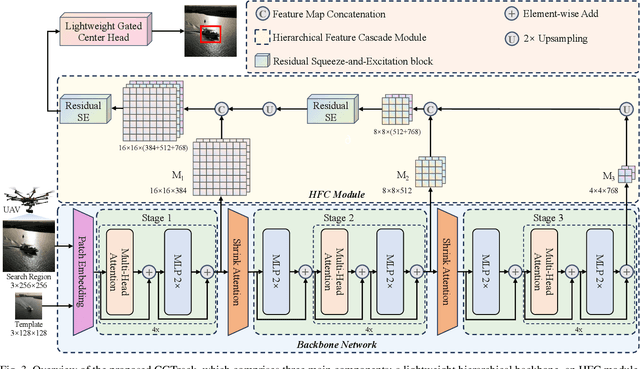
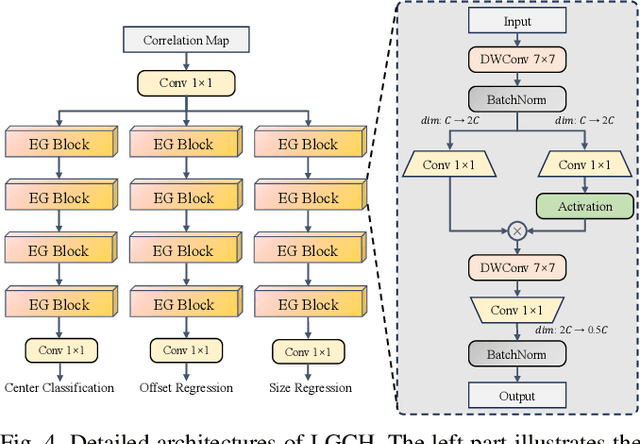
Recent advancements in visual object tracking have markedly improved the capabilities of unmanned aerial vehicle (UAV) tracking, which is a critical component in real-world robotics applications. While the integration of hierarchical lightweight networks has become a prevalent strategy for enhancing efficiency in UAV tracking, it often results in a significant drop in network capacity, which further exacerbates challenges in UAV scenarios, such as frequent occlusions and extreme changes in viewing angles. To address these issues, we introduce a novel family of UAV trackers, termed CGTrack, which combines explicit and implicit techniques to expand network capacity within a coarse-to-fine framework. Specifically, we first introduce a Hierarchical Feature Cascade (HFC) module that leverages the spirit of feature reuse to increase network capacity by integrating the deep semantic cues with the rich spatial information, incurring minimal computational costs while enhancing feature representation. Based on this, we design a novel Lightweight Gated Center Head (LGCH) that utilizes gating mechanisms to decouple target-oriented coordinates from previously expanded features, which contain dense local discriminative information. Extensive experiments on three challenging UAV tracking benchmarks demonstrate that CGTrack achieves state-of-the-art performance while running fast. Code will be available at https://github.com/Nightwatch-Fox11/CGTrack.
High-Fidelity Image Inpainting with Multimodal Guided GAN Inversion
Apr 17, 2025Generative Adversarial Network (GAN) inversion have demonstrated excellent performance in image inpainting that aims to restore lost or damaged image texture using its unmasked content. Previous GAN inversion-based methods usually utilize well-trained GAN models as effective priors to generate the realistic regions for missing holes. Despite excellence, they ignore a hard constraint that the unmasked regions in the input and the output should be the same, resulting in a gap between GAN inversion and image inpainting and thus degrading the performance. Besides, existing GAN inversion approaches often consider a single modality of the input image, neglecting other auxiliary cues in images for improvements. Addressing these problems, we propose a novel GAN inversion approach, dubbed MMInvertFill, for image inpainting. MMInvertFill contains primarily a multimodal guided encoder with a pre-modulation and a GAN generator with F&W+ latent space. Specifically, the multimodal encoder aims to enhance the multi-scale structures with additional semantic segmentation edge texture modalities through a gated mask-aware attention module. Afterwards, a pre-modulation is presented to encode these structures into style vectors. To mitigate issues of conspicuous color discrepancy and semantic inconsistency, we introduce the F&W+ latent space to bridge the gap between GAN inversion and image inpainting. Furthermore, in order to reconstruct faithful and photorealistic images, we devise a simple yet effective Soft-update Mean Latent module to capture more diversified in-domain patterns for generating high-fidelity textures for massive corruptions. In our extensive experiments on six challenging datasets, we show that our MMInvertFill qualitatively and quantitatively outperforms other state-of-the-arts and it supports the completion of out-of-domain images effectively.
Poly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding
Mar 13, 2025In this paper, we propose spatio-temporal omni-object video grounding, dubbed OmniSTVG, a new STVG task that aims at localizing spatially and temporally all targets mentioned in the textual query from videos. Compared to classic STVG locating only a single target, OmniSTVG enables localization of not only an arbitrary number of text-referred targets but also their interacting counterparts in the query from the video, making it more flexible and practical in real scenarios for comprehensive understanding. In order to facilitate exploration of OmniSTVG, we introduce BOSTVG, a large-scale benchmark dedicated to OmniSTVG. Specifically, our BOSTVG consists of 10,018 videos with 10.2M frames and covers a wide selection of 287 classes from diverse scenarios. Each sequence in BOSTVG, paired with a free-form textual query, encompasses a varying number of targets ranging from 1 to 10. To ensure high quality, each video is manually annotated with meticulous inspection and refinement. To our best knowledge, BOSTVG is to date the first and the largest benchmark for OmniSTVG. To encourage future research, we introduce a simple yet effective approach, named OmniTube, which, drawing inspiration from Transformer-based STVG methods, is specially designed for OmniSTVG and demonstrates promising results. By releasing BOSTVG, we hope to go beyond classic STVG by locating every object appearing in the query for more comprehensive understanding, opening up a new direction for STVG. Our benchmark, model, and results will be released at https://github.com/JellyYao3000/OmniSTVG.
Attention to Trajectory: Trajectory-Aware Open-Vocabulary Tracking
Mar 11, 2025



Open-Vocabulary Multi-Object Tracking (OV-MOT) aims to enable approaches to track objects without being limited to a predefined set of categories. Current OV-MOT methods typically rely primarily on instance-level detection and association, often overlooking trajectory information that is unique and essential for object tracking tasks. Utilizing trajectory information can enhance association stability and classification accuracy, especially in cases of occlusion and category ambiguity, thereby improving adaptability to novel classes. Thus motivated, in this paper we propose \textbf{TRACT}, an open-vocabulary tracker that leverages trajectory information to improve both object association and classification in OV-MOT. Specifically, we introduce a \textit{Trajectory Consistency Reinforcement} (\textbf{TCR}) strategy, that benefits tracking performance by improving target identity and category consistency. In addition, we present \textbf{TraCLIP}, a plug-and-play trajectory classification module. It integrates \textit{Trajectory Feature Aggregation} (\textbf{TFA}) and \textit{Trajectory Semantic Enrichment} (\textbf{TSE}) strategies to fully leverage trajectory information from visual and language perspectives for enhancing the classification results. Extensive experiments on OV-TAO show that our TRACT significantly improves tracking performance, highlighting trajectory information as a valuable asset for OV-MOT. Code will be released.