 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
Online Domain-aware LLM Decoding for Continual Domain Evolution
Feb 08, 2026LLMs are typically fine-tuned offline on domain-specific data, assuming a static domain. In practice, domain knowledge evolves continuously through new regulations, products, services, and interaction patterns. Retraining or fine-tuning LLMs for every new instance is computationally infeasible. Additionally, real-world environments also exhibit temporal dynamics with shifting data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. This mismatch between evolving domains and static adaptation pipelines highlights the need for efficient, real-time adaptation without costly retraining. In response, we introduce Online Domain-aware Decoding framework (ODD). ODD performs probability-level fusion between a base LLM and a prefix-tree prior, guided by adaptive confidence modulation using disagreement and continuity signals. Empirical evaluation under diverse drift scenarios demonstrates that ODD consistently surpasses LLM-Greedy and LLM-Temp Scaled across all syntactic and semantic NLG metrics. It yields an absolute ROUGE-L gain of 0.065 and a 13.6% relative improvement in Cosine Similarity over the best baseline. These results demonstrate ODD 's robustness to evolving lexical and contextual patterns, making it suitable for dynamic LLM applications.
Unveiling Statistical Significance of Online Regression over Multiple Datasets
Dec 14, 2025Despite extensive focus on techniques for evaluating the performance of two learning algorithms on a single dataset, the critical challenge of developing statistical tests to compare multiple algorithms across various datasets has been largely overlooked in most machine learning research. Additionally, in the realm of Online Learning, ensuring statistical significance is essential to validate continuous learning processes, particularly for achieving rapid convergence and effectively managing concept drifts in a timely manner. Robust statistical methods are needed to assess the significance of performance differences as data evolves over time. This article examines the state-of-the-art online regression models and empirically evaluates several suitable tests. To compare multiple online regression models across various datasets, we employed the Friedman test along with corresponding post-hoc tests. For thorough evaluations, utilizing both real and synthetic datasets with 5-fold cross-validation and seed averaging ensures comprehensive assessment across various data subsets. Our tests generally confirmed the performance of competitive baselines as consistent with their individual reports. However, some statistical test results also indicate that there is still room for improvement in certain aspects of state-of-the-art methods.
OLC-WA: Drift Aware Tuning-Free Online Classification with Weighted Average
Dec 14, 2025
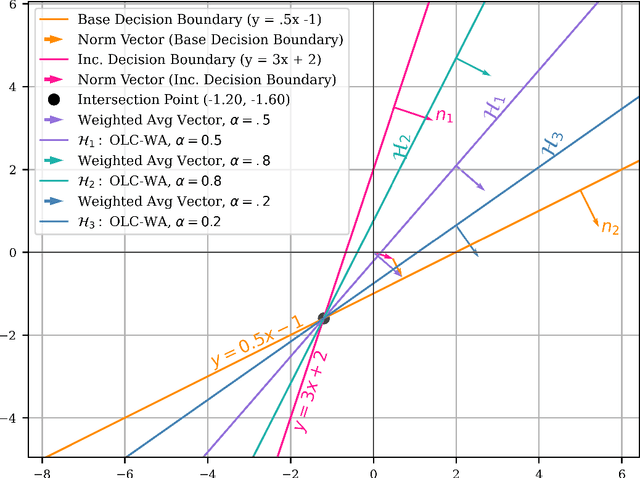

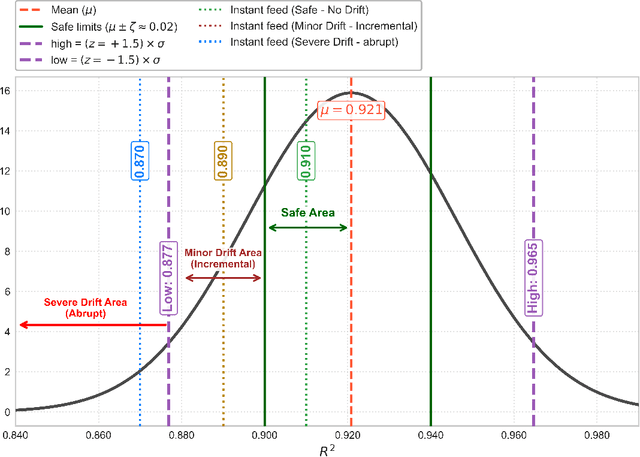
Real-world data sets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. This paper introduces Online Classification with Weighted Average (OLC-WA), an adaptive, hyperparameter-free online classification model equipped with an automated optimization mechanism. OLC-WA operates by blending incoming data streams with an existing base model. This blending is facilitated by an exponentially weighted moving average. Furthermore, an integrated optimization mechanism dynamically detects concept drift, quantifies its magnitude, and adjusts the model based on the observed data stream characteristics. This approach empowers the model to effectively adapt to evolving data distributions within streaming environments. Rigorous empirical evaluation across diverse benchmark datasets shows that OLC-WA achieves performance comparable to batch models in stationary environments, maintaining accuracy within 1-3%, and surpasses leading online baselines by 10-25% under drift, demonstrating its effectiveness in adapting to dynamic data streams.
OLR-WAA: Adaptive and Drift-Resilient Online Regression with Dynamic Weighted Averaging
Dec 14, 2025Real-world datasets frequently exhibit evolving data distributions, reflecting temporal variations and underlying shifts. Overlooking this phenomenon, known as concept drift, can substantially degrade the predictive performance of the model. Furthermore, the presence of hyperparameters in online models exacerbates this issue, as these parameters are typically fixed and lack the flexibility to dynamically adjust to evolving data. This paper introduces "OLR-WAA: An Adaptive and Drift-Resilient Online Regression with Dynamic Weighted Average", a hyperparameter-free model designed to tackle the challenges of non-stationary data streams and enable effective, continuous adaptation. The objective is to strike a balance between model stability and adaptability. OLR-WAA incrementally updates its base model by integrating incoming data streams, utilizing an exponentially weighted moving average. It further introduces a unique optimization mechanism that dynamically detects concept drift, quantifies its magnitude, and adjusts the model based on real-time data characteristics. Rigorous evaluations show that it matches batch regression performance in static settings and consistently outperforms or rivals state-of-the-art online models, confirming its effectiveness. Concept drift datasets reveal a performance gap that OLR-WAA effectively bridges, setting it apart from other online models. In addition, the model effectively handles confidence-based scenarios through a conservative update strategy that prioritizes stable, high-confidence data points. Notably, OLR-WAA converges rapidly, consistently yielding higher R2 values compared to other online models.
DAO-GP Drift Aware Online Non-Linear Regression Gaussian-Process
Dec 09, 2025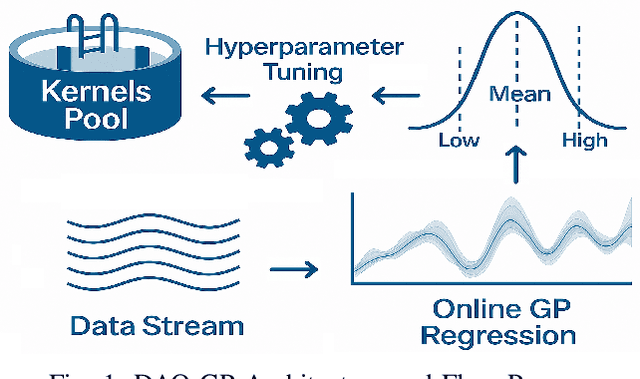
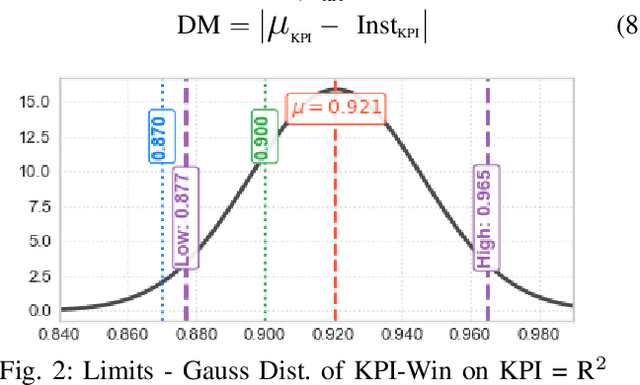
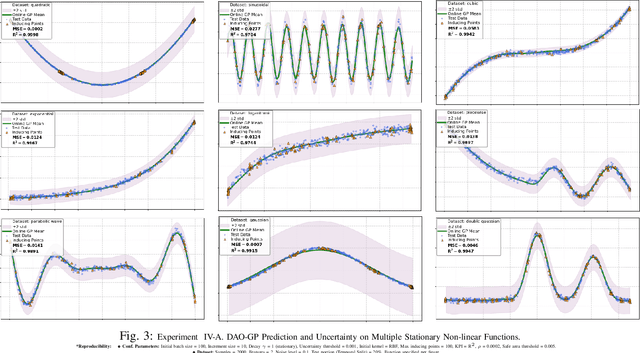
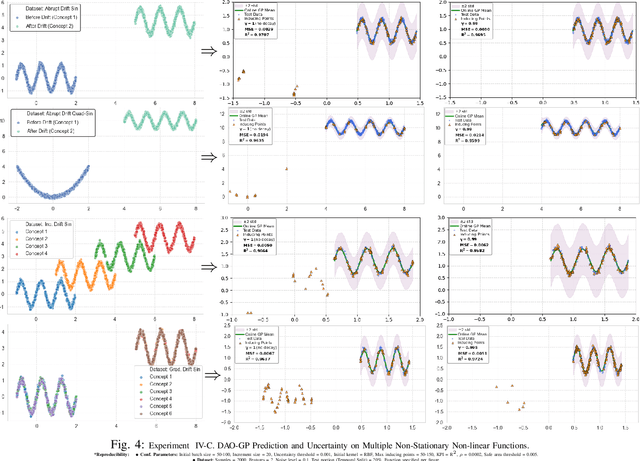
Real-world datasets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. Gaussian Process (GP) models offer powerful non-parametric regression capabilities with uncertainty quantification, making them ideal for modeling complex data relationships in an online setting. However, conventional online GP methods face several critical limitations, including a lack of drift-awareness, reliance on fixed hyperparameters, vulnerability to data snooping, absence of a principled decay mechanism, and memory inefficiencies. In response, we propose DAO-GP (Drift-Aware Online Gaussian Process), a novel, fully adaptive, hyperparameter-free, decayed, and sparse non-linear regression model. DAO-GP features a built-in drift detection and adaptation mechanism that dynamically adjusts model behavior based on the severity of drift. Extensive empirical evaluations confirm DAO-GP's robustness across stationary conditions, diverse drift types (abrupt, incremental, gradual), and varied data characteristics. Analyses demonstrate its dynamic adaptation, efficient in-memory and decay-based management, and evolving inducing points. Compared with state-of-the-art parametric and non-parametric models, DAO-GP consistently achieves superior or competitive performance, establishing it as a drift-resilient solution for online non-linear regression.
Diagnosing Shortcut-Induced Rigidity in Continual Learning: The Einstellung Rigidity Index (ERI)
Oct 01, 2025Deep neural networks frequently exploit shortcut features, defined as incidental correlations between inputs and labels without causal meaning. Shortcut features undermine robustness and reduce reliability under distribution shifts. In continual learning (CL), the consequences of shortcut exploitation can persist and intensify: weights inherited from earlier tasks bias representation reuse toward whatever features most easily satisfied prior labels, mirroring the cognitive Einstellung effect, a phenomenon where past habits block optimal solutions. Whereas catastrophic forgetting erodes past skills, shortcut-induced rigidity throttles the acquisition of new ones. We introduce the Einstellung Rigidity Index (ERI), a compact diagnostic that disentangles genuine transfer from cue-inflated performance using three interpretable facets: (i) Adaptation Delay (AD), (ii) Performance Deficit (PD), and (iii) Relative Suboptimal Feature Reliance (SFR_rel). On a two-phase CIFAR-100 CL benchmark with a deliberately spurious magenta patch in Phase 2, we evaluate Naive fine-tuning (SGD), online Elastic Weight Consolidation (EWC_on), Dark Experience Replay (DER++), Gradient Projection Memory (GPM), and Deep Generative Replay (DGR). Across these continual learning methods, we observe that CL methods reach accuracy thresholds earlier than a Scratch-T2 baseline (negative AD) but achieve slightly lower final accuracy on patched shortcut classes (positive PD). Masking the patch improves accuracy for CL methods while slightly reducing Scratch-T2, yielding negative SFR_rel. This pattern indicates the patch acted as a distractor for CL models in this setting rather than a helpful shortcut.
Wearable Sensor-Based Few-Shot Continual Learning on Hand Gestures for Motor-Impaired Individuals via Latent Embedding Exploitation
May 14, 2024Hand gestures can provide a natural means of human-computer interaction and enable people who cannot speak to communicate efficiently. Existing hand gesture recognition methods heavily depend on pre-defined gestures, however, motor-impaired individuals require new gestures tailored to each individual's gesture motion and style. Gesture samples collected from different persons have distribution shifts due to their health conditions, the severity of the disability, motion patterns of the arms, etc. In this paper, we introduce the Latent Embedding Exploitation (LEE) mechanism in our replay-based Few-Shot Continual Learning (FSCL) framework that significantly improves the performance of fine-tuning a model for out-of-distribution data. Our method produces a diversified latent feature space by leveraging a preserved latent embedding known as \textit{gesture prior knowledge}, along with \textit{intra-gesture divergence} derived from two additional embeddings. Thus, the model can capture latent statistical structure in highly variable gestures with limited samples. We conduct an experimental evaluation using the SmartWatch Gesture and the Motion Gesture datasets. The proposed method results in an average test accuracy of 57.0\%, 64.6\%, and 69.3\% by using one, three, and five samples for six different gestures. Our method helps motor-impaired persons leverage wearable devices, and their unique styles of movement can be learned and applied in human-computer interaction and social communication.
Uncertainty-Aware Multiple Instance Learning from Large-Scale Long Time Series Data
Nov 21, 2021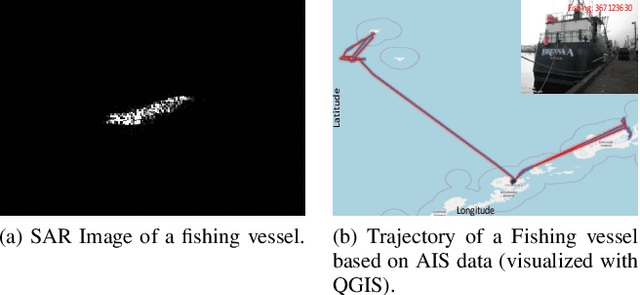
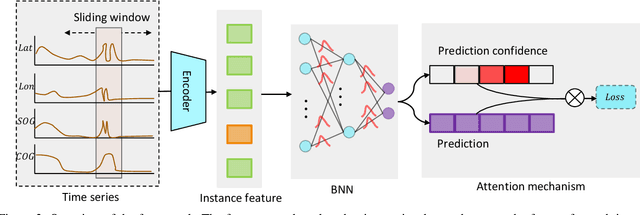
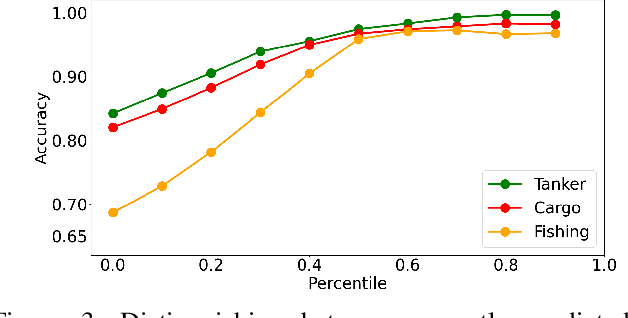
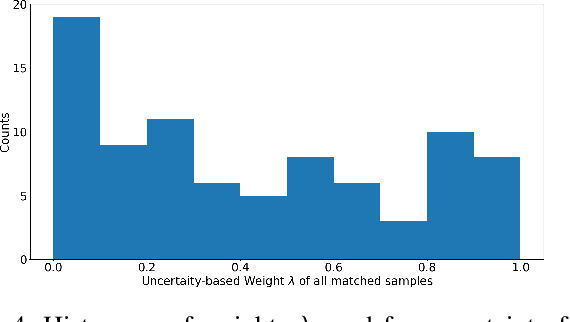
We propose a novel framework to classify large-scale time series data with long duration. Long time seriesclassification (L-TSC) is a challenging problem because the dataoften contains a large amount of irrelevant information to theclassification target. The irrelevant period degrades the classifica-tion performance while the relevance is unknown to the system.This paper proposes an uncertainty-aware multiple instancelearning (MIL) framework to identify the most relevant periodautomatically. The predictive uncertainty enables designing anattention mechanism that forces the MIL model to learn from thepossibly discriminant period. Moreover, the predicted uncertaintyyields a principled estimator to identify whether a prediction istrustworthy or not. We further incorporate another modality toaccommodate unreliable predictions by training a separate modelbased on its availability and conduct uncertainty aware fusion toproduce the final prediction. Systematic evaluation is conductedon the Automatic Identification System (AIS) data, which is col-lected to identify and track real-world vessels. Empirical resultsdemonstrate that the proposed method can effectively detect thetypes of vessels based on the trajectory and the uncertainty-awarefusion with other available data modality (Synthetic-ApertureRadar or SAR imagery is used in our experiments) can furtherimprove the detection accuracy.