 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Faithfulness: A Framework to Characterize and Compare Saliency Methods
Jun 07, 2022
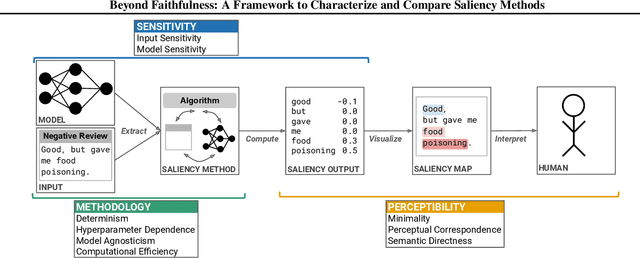
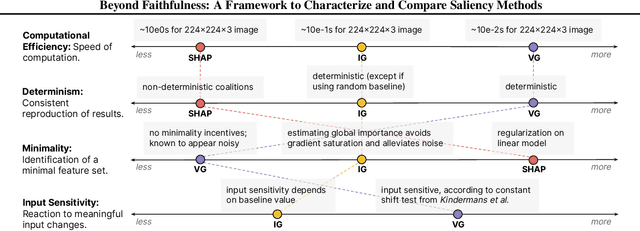

Saliency methods calculate how important each input feature is to a machine learning model's prediction, and are commonly used to understand model reasoning. "Faithfulness", or how fully and accurately the saliency output reflects the underlying model, is an oft-cited desideratum for these methods. However, explanation methods must necessarily sacrifice certain information in service of user-oriented goals such as simplicity. To that end, and akin to performance metrics, we frame saliency methods as abstractions: individual tools that provide insight into specific aspects of model behavior and entail tradeoffs. Using this framing, we describe a framework of nine dimensions to characterize and compare the properties of saliency methods. We group these dimensions into three categories that map to different phases of the interpretation process: methodology, or how the saliency is calculated; sensitivity, or relationships between the saliency result and the underlying model or input; and, perceptibility, or how a user interprets the result. As we show, these dimensions give us a granular vocabulary for describing and comparing saliency methods -- for instance, allowing us to develop "saliency cards" as a form of documentation, or helping downstream users understand tradeoffs and choose a method for a particular use case. Moreover, by situating existing saliency methods within this framework, we identify opportunities for future work, including filling gaps in the landscape and developing new evaluation metrics.
LMdiff: A Visual Diff Tool to Compare Language Models
Nov 02, 2021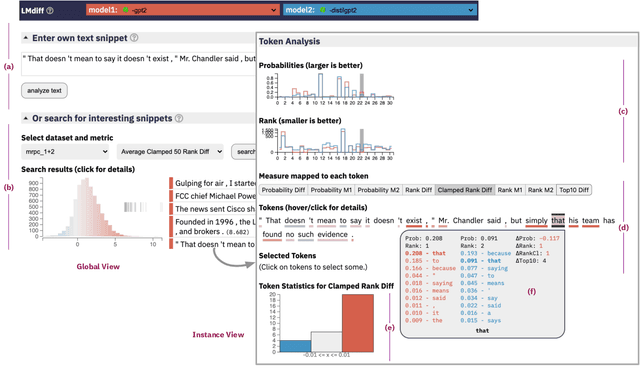

While different language models are ubiquitous in NLP, it is hard to contrast their outputs and identify which contexts one can handle better than the other. To address this question, we introduce LMdiff, a tool that visually compares probability distributions of two models that differ, e.g., through finetuning, distillation, or simply training with different parameter sizes. LMdiff allows the generation of hypotheses about model behavior by investigating text instances token by token and further assists in choosing these interesting text instances by identifying the most interesting phrases from large corpora. We showcase the applicability of LMdiff for hypothesis generation across multiple case studies. A demo is available at http://lmdiff.net .
GenNI: Human-AI Collaboration for Data-Backed Text Generation
Oct 19, 2021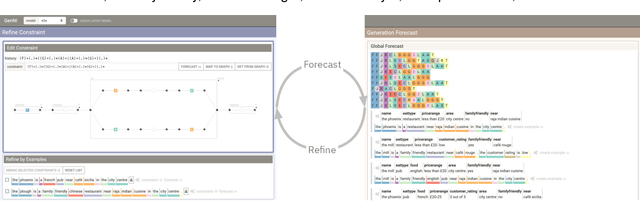
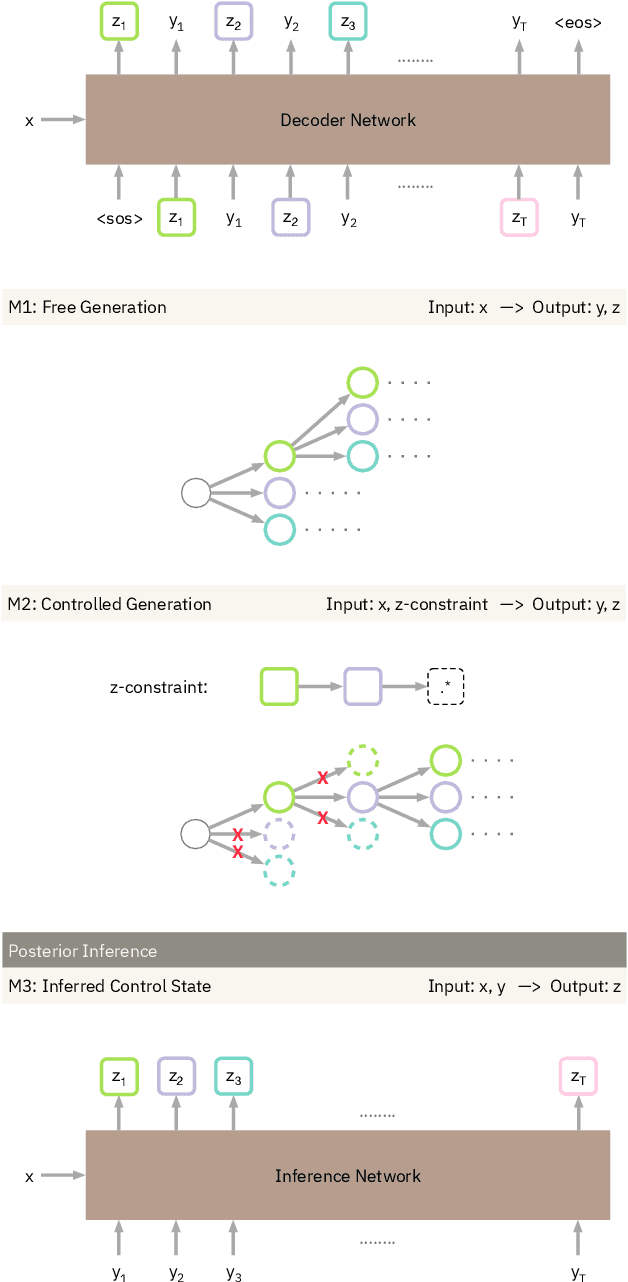
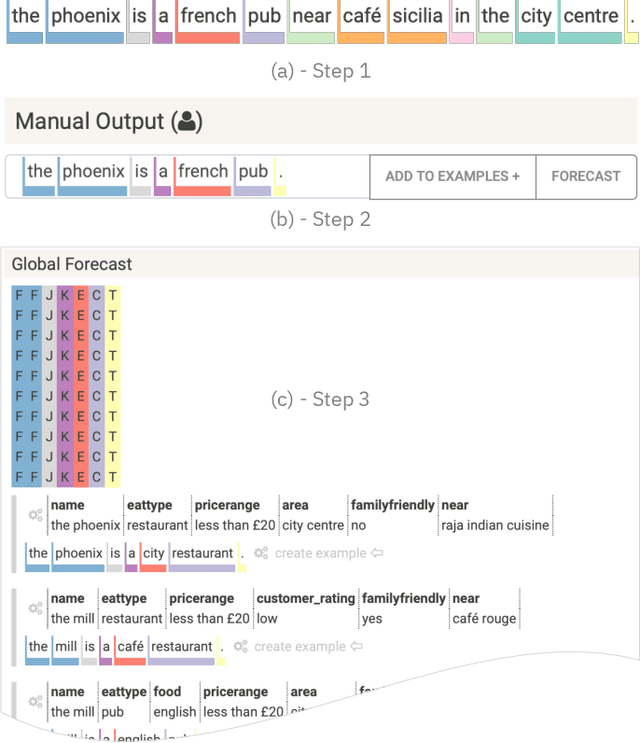
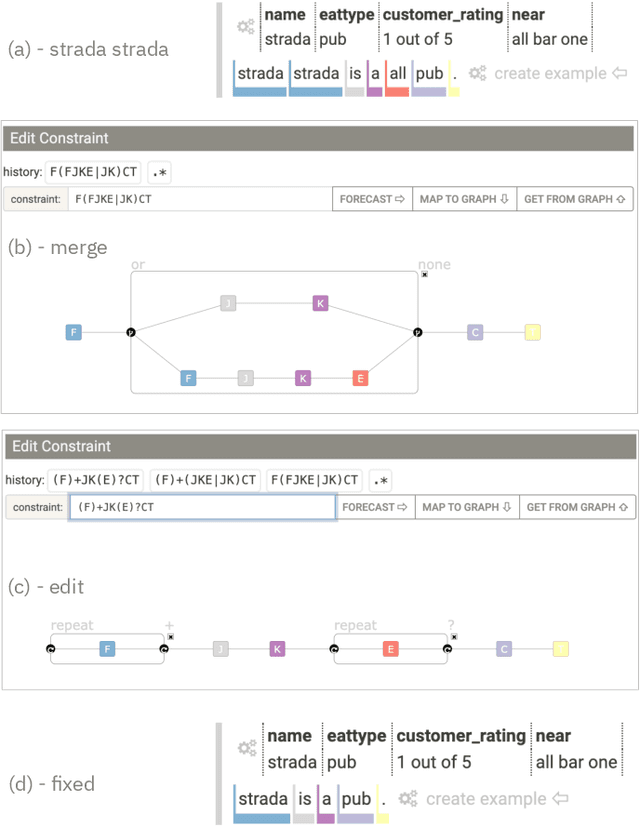
Table2Text systems generate textual output based on structured data utilizing machine learning. These systems are essential for fluent natural language interfaces in tools such as virtual assistants; however, left to generate freely these ML systems often produce misleading or unexpected outputs. GenNI (Generation Negotiation Interface) is an interactive visual system for high-level human-AI collaboration in producing descriptive text. The tool utilizes a deep learning model designed with explicit control states. These controls allow users to globally constrain model generations, without sacrificing the representation power of the deep learning models. The visual interface makes it possible for users to interact with AI systems following a Refine-Forecast paradigm to ensure that the generation system acts in a manner human users find suitable. We report multiple use cases on two experiments that improve over uncontrolled generation approaches, while at the same time providing fine-grained control. A demo and source code are available at https://genni.vizhub.ai .
Shared Interest: Large-Scale Visual Analysis of Model Behavior by Measuring Human-AI Alignment
Jul 20, 2021
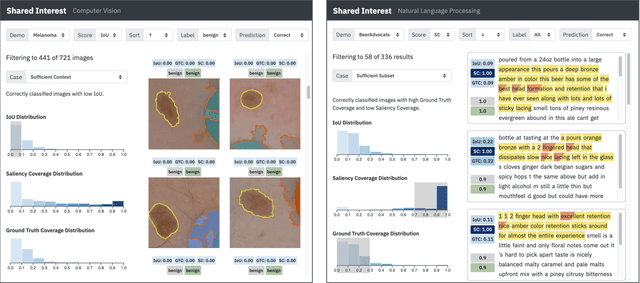

Saliency methods -- techniques to identify the importance of input features on a model's output -- are a common first step in understanding neural network behavior. However, interpreting saliency requires tedious manual inspection to identify and aggregate patterns in model behavior, resulting in ad hoc or cherry-picked analysis. To address these concerns, we present Shared Interest: a set of metrics for comparing saliency with human annotated ground truths. By providing quantitative descriptors, Shared Interest allows ranking, sorting, and aggregation of inputs thereby facilitating large-scale systematic analysis of model behavior. We use Shared Interest to identify eight recurring patterns in model behavior including focusing on a sufficient subset of ground truth features or being distracted by contextual features. Working with representative real-world users, we show how Shared Interest can be used to rapidly develop or lose trust in a model's reliability, uncover issues that are missed in manual analyses, and enable interactive probing of model behavior.
FairyTailor: A Multimodal Generative Framework for Storytelling
Jul 13, 2021
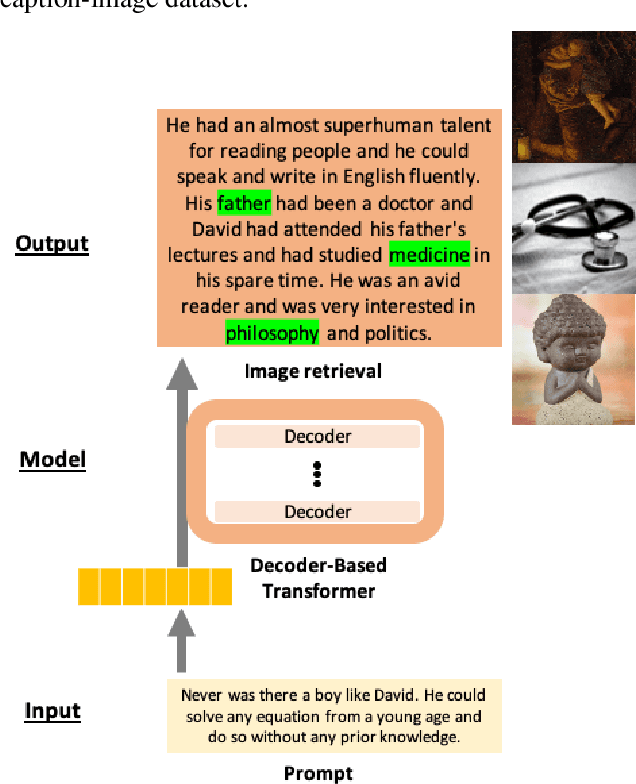

Storytelling is an open-ended task that entails creative thinking and requires a constant flow of ideas. Natural language generation (NLG) for storytelling is especially challenging because it requires the generated text to follow an overall theme while remaining creative and diverse to engage the reader. In this work, we introduce a system and a web-based demo, FairyTailor, for human-in-the-loop visual story co-creation. Users can create a cohesive children's fairytale by weaving generated texts and retrieved images with their input. FairyTailor adds another modality and modifies the text generation process to produce a coherent and creative sequence of text and images. To our knowledge, this is the first dynamic tool for multimodal story generation that allows interactive co-formation of both texts and images. It allows users to give feedback on co-created stories and share their results.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Latent Compass: Creation by Navigation
Dec 20, 2020In Marius von Senden's Space and Sight, a newly sighted blind patient describes the experience of a corner as lemon-like, because corners "prick" sight like lemons prick the tongue. Prickliness, here, is a dimension in the feature space of sensory experience, an effect of the perceived on the perceiver that arises where the two interact. In the account of the newly sighted, an effect familiar from one interaction translates to a novel context. Perception serves as the vehicle for generalization, in that an effect shared across different experiences produces a concrete abstraction grounded in those experiences. Cezanne and the post-impressionists, fluent in the language of experience translation, realized that the way to paint a concrete form that best reflected reality was to paint not what they saw, but what it was like to see. We envision a future of creation using AI where what it is like to see is replicable, transferrable, manipulable - part of the artist's palette that is both grounded in a particular context, and generalizable beyond it. An active line of research maps human-interpretable features onto directions in GAN latent space. Supervised and self-supervised approaches that search for anticipated directions or use off-the-shelf classifiers to drive image manipulation in embedding space are limited in the variety of features they can uncover. Unsupervised approaches that discover useful new directions show that the space of perceptually meaningful directions is nowhere close to being fully mapped. As this space is broad and full of creative potential, we want tools for direction discovery that capture the richness and generalizability of human perception. Our approach puts creators in the discovery loop during real-time tool use, in order to identify directions that are perceptually meaningful to them, and generate interpretable image translations along those directions.
Understanding the Role of Individual Units in a Deep Neural Network
Sep 12, 2020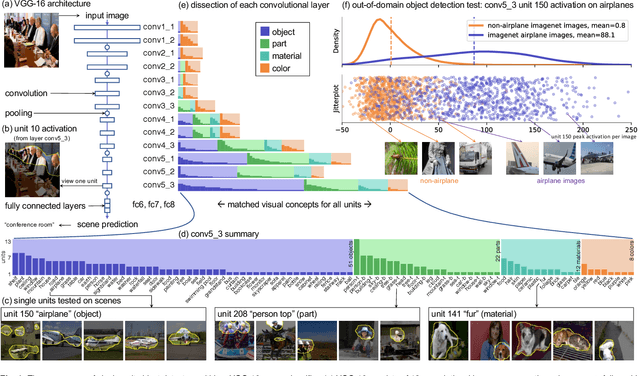
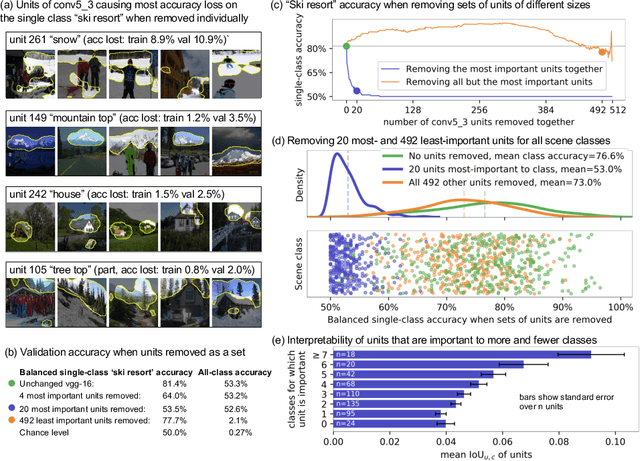
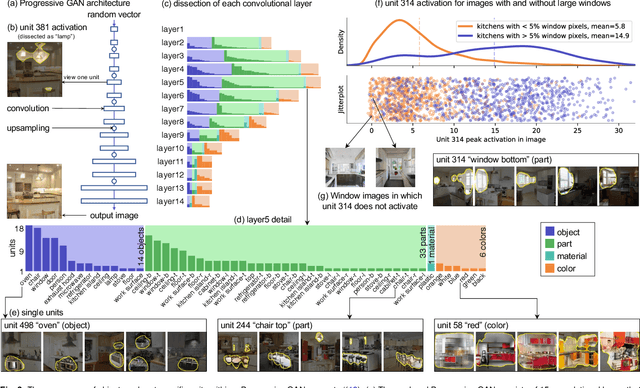
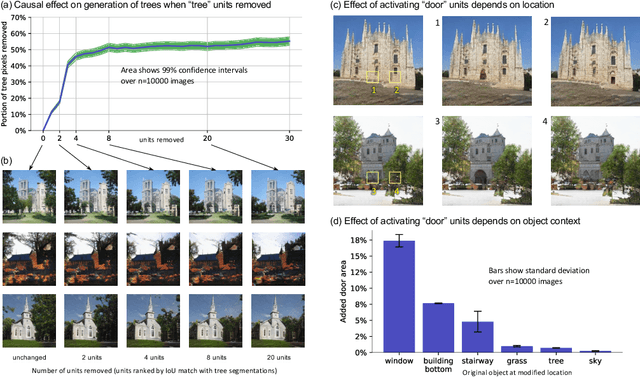
Deep neural networks excel at finding hierarchical representations that solve complex tasks over large data sets. How can we humans understand these learned representations? In this work, we present network dissection, an analytic framework to systematically identify the semantics of individual hidden units within image classification and image generation networks. First, we analyze a convolutional neural network (CNN) trained on scene classification and discover units that match a diverse set of object concepts. We find evidence that the network has learned many object classes that play crucial roles in classifying scene classes. Second, we use a similar analytic method to analyze a generative adversarial network (GAN) model trained to generate scenes. By analyzing changes made when small sets of units are activated or deactivated, we find that objects can be added and removed from the output scenes while adapting to the context. Finally, we apply our analytic framework to understanding adversarial attacks and to semantic image editing.
Accelerating Antimicrobial Discovery with Controllable Deep Generative Models and Molecular Dynamics
May 22, 2020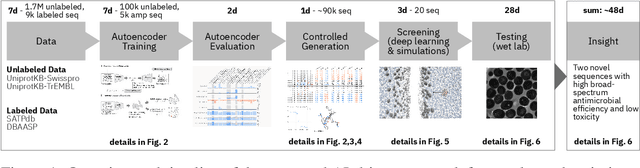
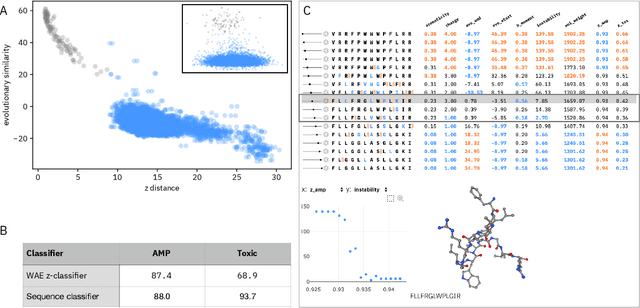
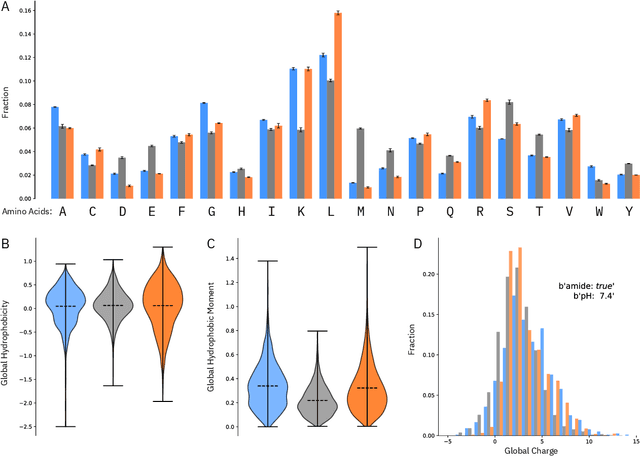
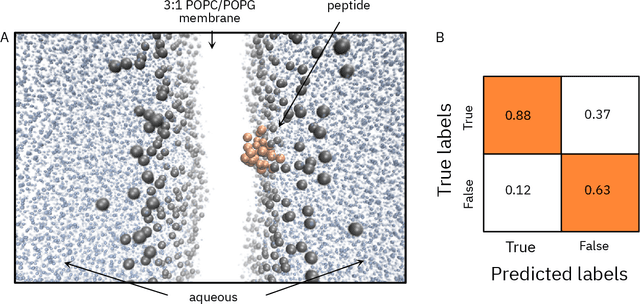
De novo therapeutic design is challenged by a vast chemical repertoire and multiple constraints such as high broad-spectrum potency and low toxicity. We propose CLaSS (Controlled Latent attribute Space Sampling) - a novel and efficient computational method for attribute-controlled generation of molecules, which leverages guidance from classifiers trained on an informative latent space of molecules modeled using a deep generative autoencoder. We further screen the generated molecules by using a set of deep learning classifiers in conjunction with novel physicochemical features derived from high-throughput molecular simulations. The proposed approach is employed for designing non-toxic antimicrobial peptides (AMPs) with strong broad-spectrum potency, which are emerging drug candidates for tackling antibiotic resistance. Synthesis and wet lab testing of only twenty designed sequences identified two novel and minimalist AMPs with high potency against diverse Gram-positive and Gram-negative pathogens, including the hard-to-treat multidrug-resistant K. pneumoniae, as well as low in vitro and in vivo toxicity. The proposed approach thus presents a viable path for faster discovery of potent and selective broad-spectrum antimicrobials with a higher success rate than state-of-the-art methods.
Semantic Photo Manipulation with a Generative Image Prior
May 15, 2020

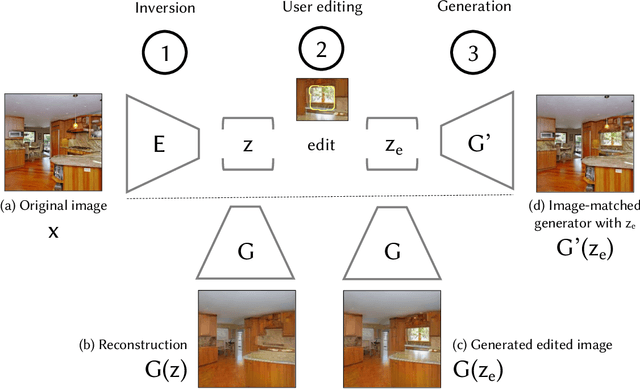
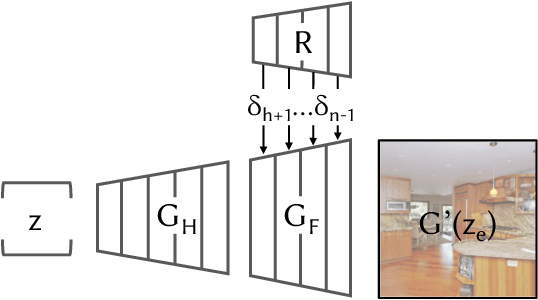
Despite the recent success of GANs in synthesizing images conditioned on inputs such as a user sketch, text, or semantic labels, manipulating the high-level attributes of an existing natural photograph with GANs is challenging for two reasons. First, it is hard for GANs to precisely reproduce an input image. Second, after manipulation, the newly synthesized pixels often do not fit the original image. In this paper, we address these issues by adapting the image prior learned by GANs to image statistics of an individual image. Our method can accurately reconstruct the input image and synthesize new content, consistent with the appearance of the input image. We demonstrate our interactive system on several semantic image editing tasks, including synthesizing new objects consistent with background, removing unwanted objects, and changing the appearance of an object. Quantitative and qualitative comparisons against several existing methods demonstrate the effectiveness of our method.
* SIGGRAPH 2019