 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception
Mar 21, 2023There is a recent trend in the LiDAR perception field towards unifying multiple tasks in a single strong network with improved performance, as opposed to using separate networks for each task. In this paper, we introduce a new LiDAR multi-task learning paradigm based on the transformer. The proposed LiDARFormer utilizes cross-space global contextual feature information and exploits cross-task synergy to boost the performance of LiDAR perception tasks across multiple large-scale datasets and benchmarks. Our novel transformer-based framework includes a cross-space transformer module that learns attentive features between the 2D dense Bird's Eye View (BEV) and 3D sparse voxel feature maps. Additionally, we propose a transformer decoder for the segmentation task to dynamically adjust the learned features by leveraging the categorical feature representations. Furthermore, we combine the segmentation and detection features in a shared transformer decoder with cross-task attention layers to enhance and integrate the object-level and class-level features. LiDARFormer is evaluated on the large-scale nuScenes and the Waymo Open datasets for both 3D detection and semantic segmentation tasks, and it outperforms all previously published methods on both tasks. Notably, LiDARFormer achieves the state-of-the-art performance of 76.4% L2 mAPH and 74.3% NDS on the challenging Waymo and nuScenes detection benchmarks for a single model LiDAR-only method.
MobileRec: A Large-Scale Dataset for Mobile Apps Recommendation
Mar 12, 2023



Recommender systems have become ubiquitous in our digital lives, from recommending products on e-commerce websites to suggesting movies and music on streaming platforms. Existing recommendation datasets, such as Amazon Product Reviews and MovieLens, greatly facilitated the research and development of recommender systems in their respective domains. While the number of mobile users and applications (aka apps) has increased exponentially over the past decade, research in mobile app recommender systems has been significantly constrained, primarily due to the lack of high-quality benchmark datasets, as opposed to recommendations for products, movies, and news. To facilitate research for app recommendation systems, we introduce a large-scale dataset, called MobileRec. We constructed MobileRec from users' activity on the Google play store. MobileRec contains 19.3 million user interactions (i.e., user reviews on apps) with over 10K unique apps across 48 categories. MobileRec records the sequential activity of a total of 0.7 million distinct users. Each of these users has interacted with no fewer than five distinct apps, which stands in contrast to previous datasets on mobile apps that recorded only a single interaction per user. Furthermore, MobileRec presents users' ratings as well as sentiments on installed apps, and each app contains rich metadata such as app name, category, description, and overall rating, among others. We demonstrate that MobileRec can serve as an excellent testbed for app recommendation through a comparative study of several state-of-the-art recommendation approaches. The quantitative results can act as a baseline for other researchers to compare their results against. The MobileRec dataset is available at https://huggingface.co/datasets/recmeapp/mobilerec.
LidarMultiNet: Towards a Unified Multi-task Network for LiDAR Perception
Sep 19, 2022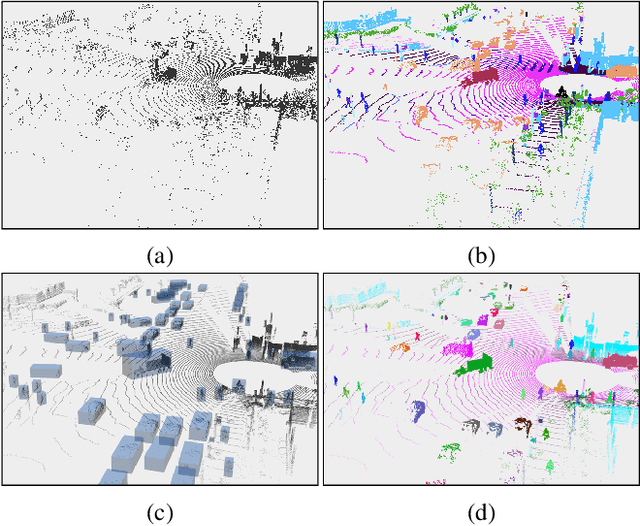
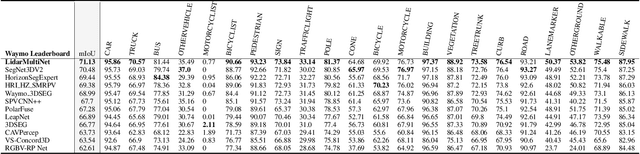
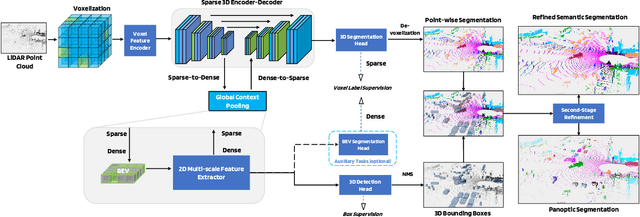

LiDAR-based 3D object detection, semantic segmentation, and panoptic segmentation are usually implemented in specialized networks with distinctive architectures that are difficult to adapt to each other. This paper presents LidarMultiNet, a LiDAR-based multi-task network that unifies these three major LiDAR perception tasks. Among its many benefits, a multi-task network can reduce the overall cost by sharing weights and computation among multiple tasks. However, it typically underperforms compared to independently combined single-task models. The proposed LidarMultiNet aims to bridge the performance gap between the multi-task network and multiple single-task networks. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder architecture with a Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame. Task-specific heads are added on top of the network to perform the three LiDAR perception tasks. More tasks can be implemented simply by adding new task-specific heads while introducing little additional cost. A second stage is also proposed to refine the first-stage segmentation and generate accurate panoptic segmentation results. LidarMultiNet is extensively tested on both Waymo Open Dataset and nuScenes dataset, demonstrating for the first time that major LiDAR perception tasks can be unified in a single strong network that is trained end-to-end and achieves state-of-the-art performance. Notably, LidarMultiNet reaches the official 1st place in the Waymo Open Dataset 3D semantic segmentation challenge 2022 with the highest mIoU and the best accuracy for most of the 22 classes on the test set, using only LiDAR points as input. It also sets the new state-of-the-art for a single model on the Waymo 3D object detection benchmark and three nuScenes benchmarks.
CenterFormer: Center-based Transformer for 3D Object Detection
Sep 12, 2022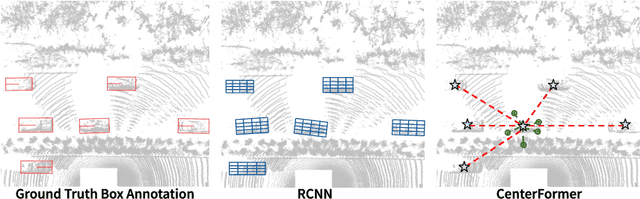
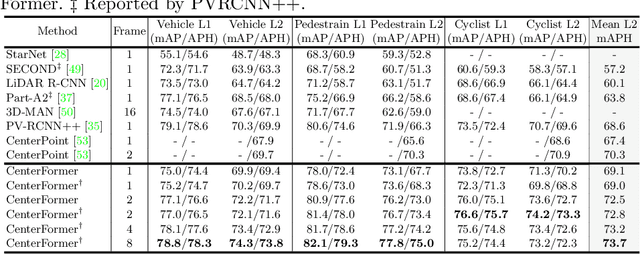
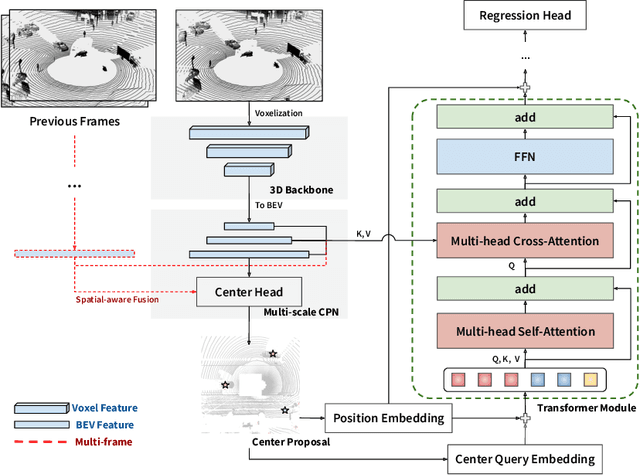
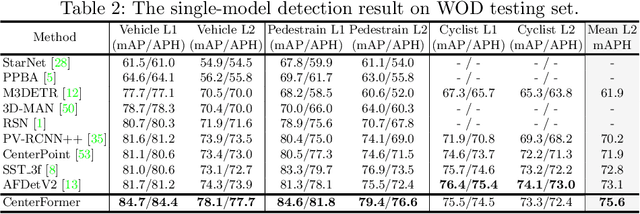
Query-based transformer has shown great potential in constructing long-range attention in many image-domain tasks, but has rarely been considered in LiDAR-based 3D object detection due to the overwhelming size of the point cloud data. In this paper, we propose CenterFormer, a center-based transformer network for 3D object detection. CenterFormer first uses a center heatmap to select center candidates on top of a standard voxel-based point cloud encoder. It then uses the feature of the center candidate as the query embedding in the transformer. To further aggregate features from multiple frames, we design an approach to fuse features through cross-attention. Lastly, regression heads are added to predict the bounding box on the output center feature representation. Our design reduces the convergence difficulty and computational complexity of the transformer structure. The results show significant improvements over the strong baseline of anchor-free object detection networks. CenterFormer achieves state-of-the-art performance for a single model on the Waymo Open Dataset, with 73.7% mAPH on the validation set and 75.6% mAPH on the test set, significantly outperforming all previously published CNN and transformer-based methods. Our code is publicly available at https://github.com/TuSimple/centerformer
LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 24, 2022
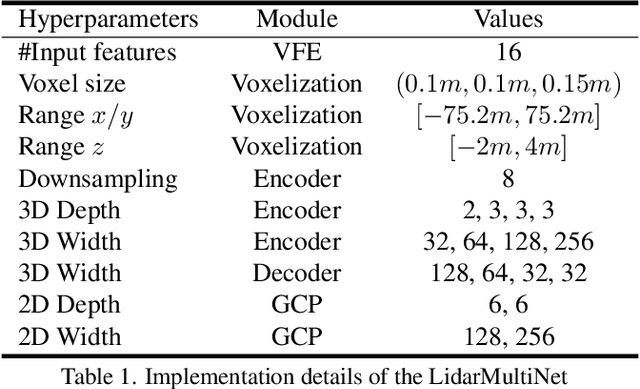
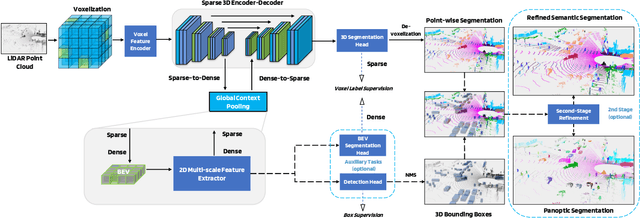
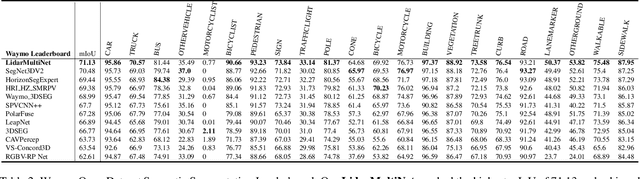
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
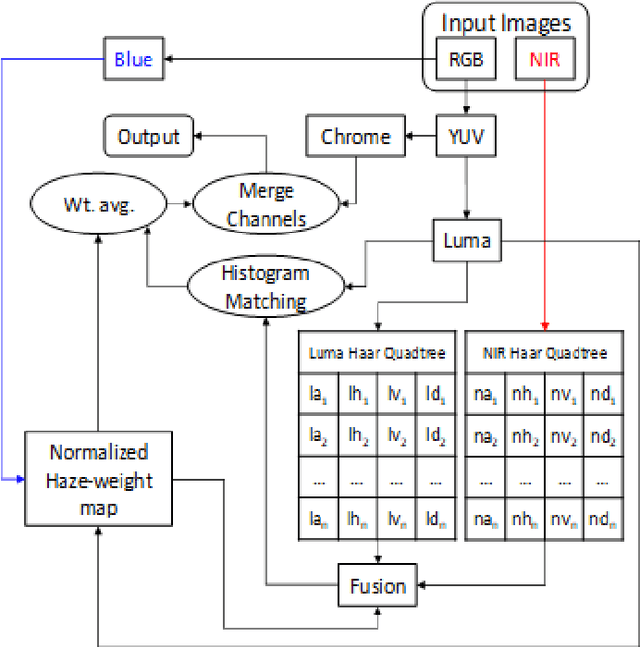
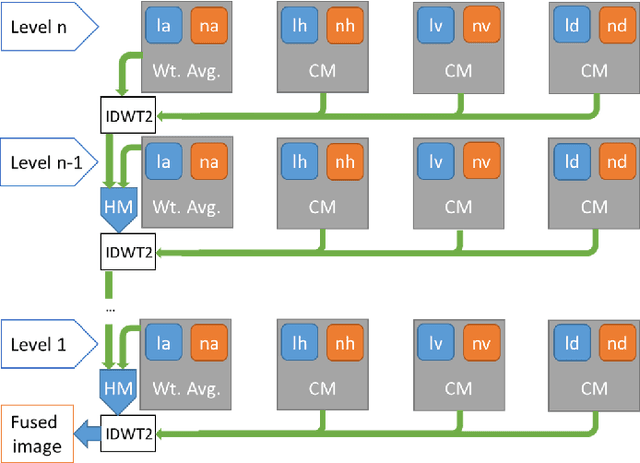
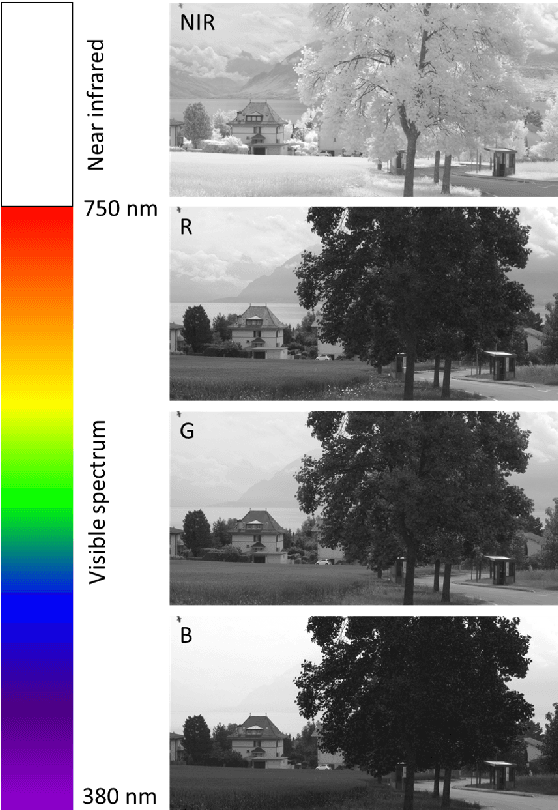
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
StreamHover: Livestream Transcript Summarization and Annotation
Sep 11, 2021
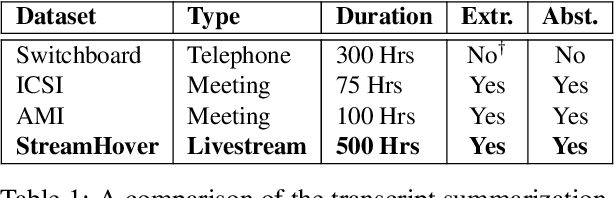

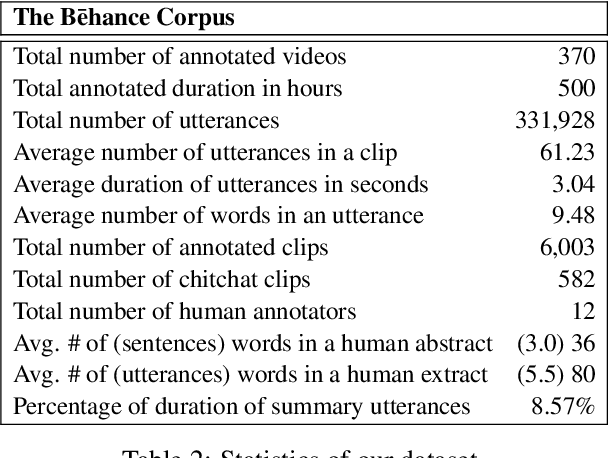
With the explosive growth of livestream broadcasting, there is an urgent need for new summarization technology that enables us to create a preview of streamed content and tap into this wealth of knowledge. However, the problem is nontrivial due to the informal nature of spoken language. Further, there has been a shortage of annotated datasets that are necessary for transcript summarization. In this paper, we present StreamHover, a framework for annotating and summarizing livestream transcripts. With a total of over 500 hours of videos annotated with both extractive and abstractive summaries, our benchmark dataset is significantly larger than currently existing annotated corpora. We explore a neural extractive summarization model that leverages vector-quantized variational autoencoder to learn latent vector representations of spoken utterances and identify salient utterances from the transcripts to form summaries. We show that our model generalizes better and improves performance over strong baselines. The results of this study provide an avenue for future research to improve summarization solutions for efficient browsing of livestreams.
Panoptic-PolarNet: Proposal-free LiDAR Point Cloud Panoptic Segmentation
Mar 27, 2021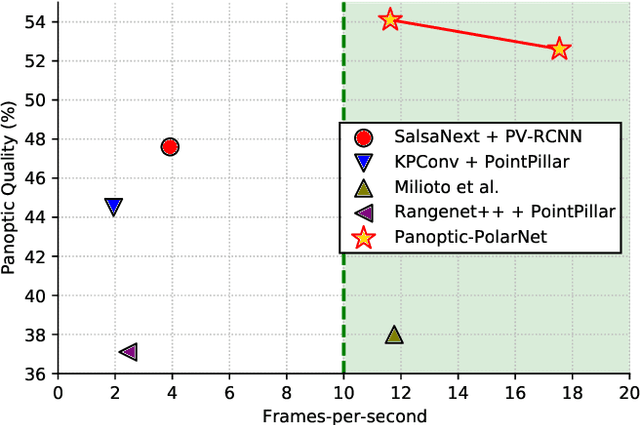
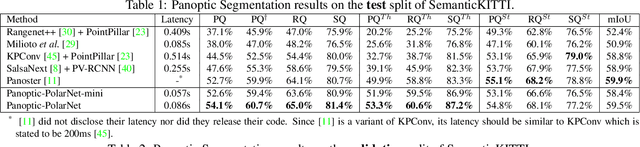
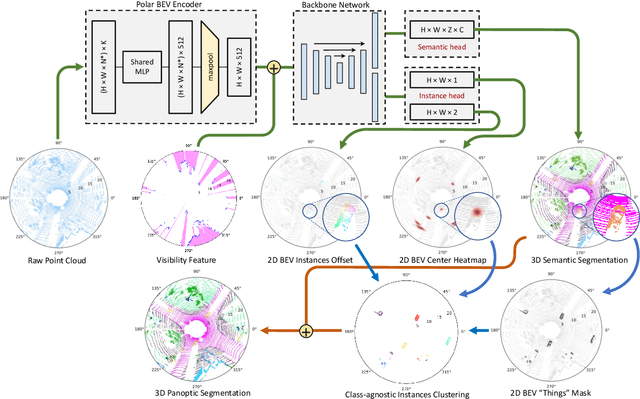
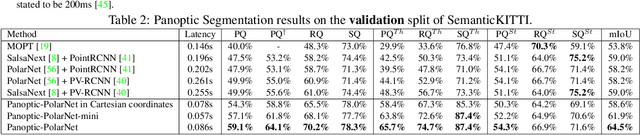
Panoptic segmentation presents a new challenge in exploiting the merits of both detection and segmentation, with the aim of unifying instance segmentation and semantic segmentation in a single framework. However, an efficient solution for panoptic segmentation in the emerging domain of LiDAR point cloud is still an open research problem and is very much under-explored. In this paper, we present a fast and robust LiDAR point cloud panoptic segmentation framework, referred to as Panoptic-PolarNet. We learn both semantic segmentation and class-agnostic instance clustering in a single inference network using a polar Bird's Eye View (BEV) representation, enabling us to circumvent the issue of occlusion among instances in urban street scenes. To improve our network's learnability, we also propose an adapted instance augmentation technique and a novel adversarial point cloud pruning method. Our experiments show that Panoptic-PolarNet outperforms the baseline methods on SemanticKITTI and nuScenes datasets with an almost real-time inference speed. Panoptic-PolarNet achieved 54.1% PQ in the public SemanticKITTI panoptic segmentation leaderboard and leading performance for the validation set of nuScenes.
Better Highlighting: Creating Sub-Sentence Summary Highlights
Oct 20, 2020


Amongst the best means to summarize is highlighting. In this paper, we aim to generate summary highlights to be overlaid on the original documents to make it easier for readers to sift through a large amount of text. The method allows summaries to be understood in context to prevent a summarizer from distorting the original meaning, of which abstractive summarizers usually fall short. In particular, we present a new method to produce self-contained highlights that are understandable on their own to avoid confusion. Our method combines determinantal point processes and deep contextualized representations to identify an optimal set of sub-sentence segments that are both important and non-redundant to form summary highlights. To demonstrate the flexibility and modeling power of our method, we conduct extensive experiments on summarization datasets. Our analysis provides evidence that highlighting is a promising avenue of research towards future summarization.
CCA: Exploring the Possibility of Contextual Camouflage Attack on Object Detection
Aug 19, 2020
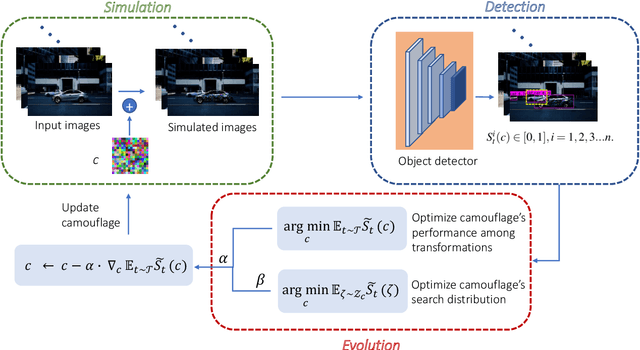
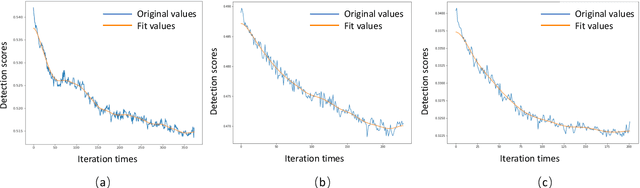
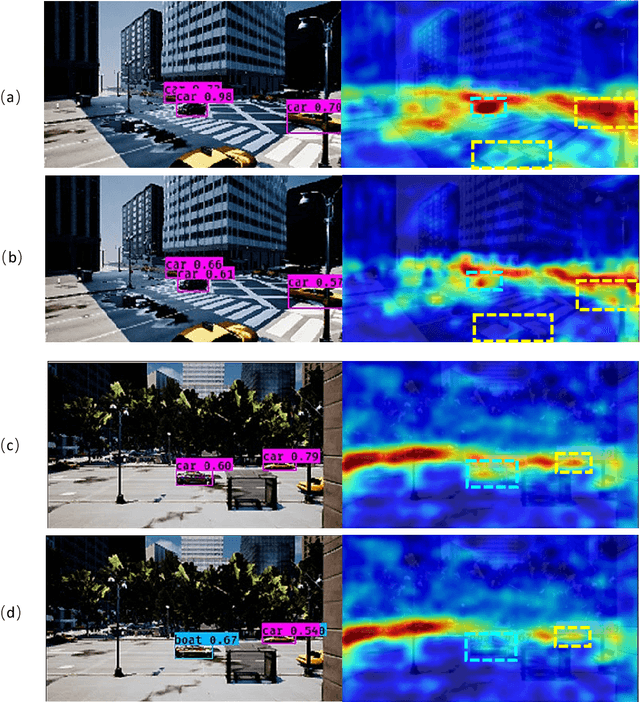
Deep neural network based object detection hasbecome the cornerstone of many real-world applications. Alongwith this success comes concerns about its vulnerability tomalicious attacks. To gain more insight into this issue, we proposea contextual camouflage attack (CCA for short) algorithm to in-fluence the performance of object detectors. In this paper, we usean evolutionary search strategy and adversarial machine learningin interactions with a photo-realistic simulated environment tofind camouflage patterns that are effective over a huge varietyof object locations, camera poses, and lighting conditions. Theproposed camouflages are validated effective to most of the state-of-the-art object detectors.