 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
ForesightNav: Learning Scene Imagination for Efficient Exploration
Apr 22, 2025Understanding how humans leverage prior knowledge to navigate unseen environments while making exploratory decisions is essential for developing autonomous robots with similar abilities. In this work, we propose ForesightNav, a novel exploration strategy inspired by human imagination and reasoning. Our approach equips robotic agents with the capability to predict contextual information, such as occupancy and semantic details, for unexplored regions. These predictions enable the robot to efficiently select meaningful long-term navigation goals, significantly enhancing exploration in unseen environments. We validate our imagination-based approach using the Structured3D dataset, demonstrating accurate occupancy prediction and superior performance in anticipating unseen scene geometry. Our experiments show that the imagination module improves exploration efficiency in unseen environments, achieving a 100% completion rate for PointNav and an SPL of 67% for ObjectNav on the Structured3D Validation split. These contributions demonstrate the power of imagination-driven reasoning for autonomous systems to enhance generalizable and efficient exploration.
Enhancing End-to-End Multi-Task Dialogue Systems: A Study on Intrinsic Motivation Reinforcement Learning Algorithms for Improved Training and Adaptability
Jan 31, 2024End-to-end multi-task dialogue systems are usually designed with separate modules for the dialogue pipeline. Among these, the policy module is essential for deciding what to do in response to user input. This policy is trained by reinforcement learning algorithms by taking advantage of an environment in which an agent receives feedback in the form of a reward signal. The current dialogue systems, however, only provide meagre and simplistic rewards. Investigating intrinsic motivation reinforcement learning algorithms is the goal of this study. Through this, the agent can quickly accelerate training and improve its capacity to judge the quality of its actions by teaching it an internal incentive system. In particular, we adapt techniques for random network distillation and curiosity-driven reinforcement learning to measure the frequency of state visits and encourage exploration by using semantic similarity between utterances. Experimental results on MultiWOZ, a heterogeneous dataset, show that intrinsic motivation-based debate systems outperform policies that depend on extrinsic incentives. By adopting random network distillation, for example, which is trained using semantic similarity between user-system dialogues, an astounding average success rate of 73% is achieved. This is a significant improvement over the baseline Proximal Policy Optimization (PPO), which has an average success rate of 60%. In addition, performance indicators such as booking rates and completion rates show a 10% rise over the baseline. Furthermore, these intrinsic incentive models help improve the system's policy's resilience in an increasing amount of domains. This implies that they could be useful in scaling up to settings that cover a wider range of domains.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone
Jul 11, 2023



Video-language pre-training (VLP) has become increasingly important due to its ability to generalize to various vision and language tasks. However, existing egocentric VLP frameworks utilize separate video and language encoders and learn task-specific cross-modal information only during fine-tuning, limiting the development of a unified system. In this work, we introduce the second generation of egocentric video-language pre-training (EgoVLPv2), a significant improvement from the previous generation, by incorporating cross-modal fusion directly into the video and language backbones. EgoVLPv2 learns strong video-text representation during pre-training and reuses the cross-modal attention modules to support different downstream tasks in a flexible and efficient manner, reducing fine-tuning costs. Moreover, our proposed fusion in the backbone strategy is more lightweight and compute-efficient than stacking additional fusion-specific layers. Extensive experiments on a wide range of VL tasks demonstrate the effectiveness of EgoVLPv2 by achieving consistent state-of-the-art performance over strong baselines across all downstream. Our project page can be found at https://shramanpramanick.github.io/EgoVLPv2/.
End-to-End Neural Network Compression via $\frac{\ell_1}{\ell_2}$ Regularized Latency Surrogates
Jun 13, 2023



Neural network (NN) compression via techniques such as pruning, quantization requires setting compression hyperparameters (e.g., number of channels to be pruned, bitwidths for quantization) for each layer either manually or via neural architecture search (NAS) which can be computationally expensive. We address this problem by providing an end-to-end technique that optimizes for model's Floating Point Operations (FLOPs) or for on-device latency via a novel $\frac{\ell_1}{\ell_2}$ latency surrogate. Our algorithm is versatile and can be used with many popular compression methods including pruning, low-rank factorization, and quantization. Crucially, it is fast and runs in almost the same amount of time as single model training; which is a significant training speed-up over standard NAS methods. For BERT compression on GLUE fine-tuning tasks, we achieve $50\%$ reduction in FLOPs with only $1\%$ drop in performance. For compressing MobileNetV3 on ImageNet-1K, we achieve $15\%$ reduction in FLOPs, and $11\%$ reduction in on-device latency without drop in accuracy, while still requiring $3\times$ less training compute than SOTA compression techniques. Finally, for transfer learning on smaller datasets, our technique identifies $1.2\times$-$1.4\times$ cheaper architectures than standard MobileNetV3, EfficientNet suite of architectures at almost the same training cost and accuracy.
DIME-FM: DIstilling Multimodal and Efficient Foundation Models
Mar 31, 2023



Large Vision-Language Foundation Models (VLFM), such as CLIP, ALIGN and Florence, are trained on large-scale datasets of image-caption pairs and achieve superior transferability and robustness on downstream tasks, but they are difficult to use in many practical applications due to their large size, high latency and fixed architectures. Unfortunately, recent work shows training a small custom VLFM for resource-limited applications is currently very difficult using public and smaller-scale data. In this paper, we introduce a new distillation mechanism (DIME-FM) that allows us to transfer the knowledge contained in large VLFMs to smaller, customized foundation models using a relatively small amount of inexpensive, unpaired images and sentences. We transfer the knowledge from the pre-trained CLIP-ViTL/14 model to a ViT-B/32 model, with only 40M public images and 28.4M unpaired public sentences. The resulting model "Distill-ViT-B/32" rivals the CLIP-ViT-B/32 model pre-trained on its private WiT dataset (400M image-text pairs): Distill-ViT-B/32 achieves similar results in terms of zero-shot and linear-probing performance on both ImageNet and the ELEVATER (20 image classification tasks) benchmarks. It also displays comparable robustness when evaluated on five datasets with natural distribution shifts from ImageNet.
Tell Your Story: Task-Oriented Dialogs for Interactive Content Creation
Nov 08, 2022



People capture photos and videos to relive and share memories of personal significance. Recently, media montages (stories) have become a popular mode of sharing these memories due to their intuitive and powerful storytelling capabilities. However, creating such montages usually involves a lot of manual searches, clicks, and selections that are time-consuming and cumbersome, adversely affecting user experiences. To alleviate this, we propose task-oriented dialogs for montage creation as a novel interactive tool to seamlessly search, compile, and edit montages from a media collection. To the best of our knowledge, our work is the first to leverage multi-turn conversations for such a challenging application, extending the previous literature studying simple media retrieval tasks. We collect a new dataset C3 (Conversational Content Creation), comprising 10k dialogs conditioned on media montages simulated from a large media collection. We take a simulate-and-paraphrase approach to collect these dialogs to be both cost and time efficient, while drawing from natural language distribution. Our analysis and benchmarking of state-of-the-art language models showcase the multimodal challenges present in the dataset. Lastly, we present a real-world mobile demo application that shows the feasibility of the proposed work in real-world applications. Our code and data will be made publicly available.
Fighting FIRe with FIRE: Assessing the Validity of Text-to-Video Retrieval Benchmarks
Oct 10, 2022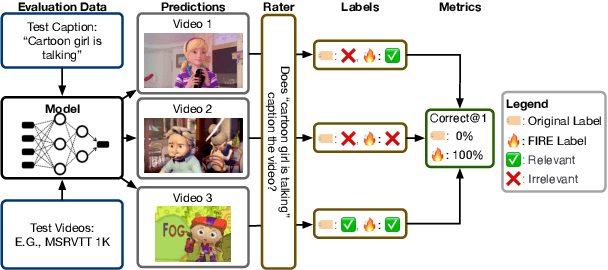
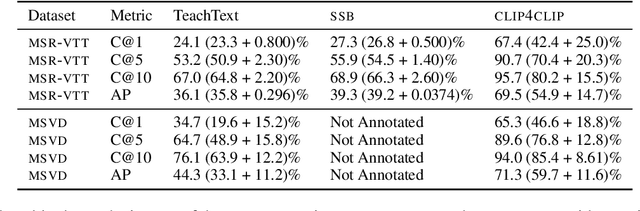
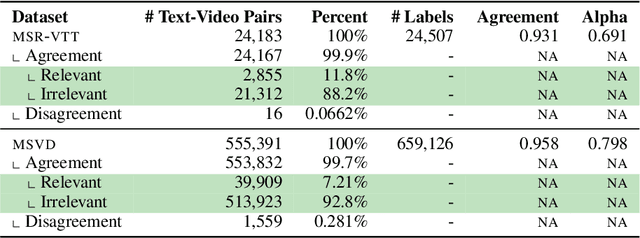
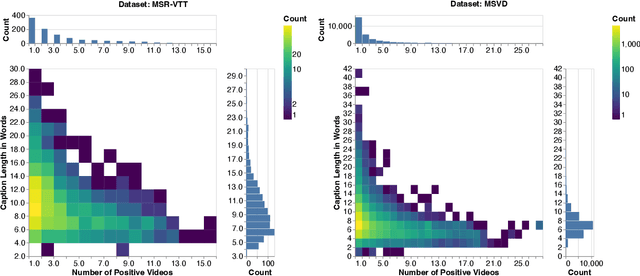
Searching vast troves of videos with textual descriptions is a core multimodal retrieval task. Owing to the lack of a purpose-built dataset for text-to-video retrieval, video captioning datasets have been re-purposed to evaluate models by (1) treating captions as positive matches to their respective videos and (2) all other videos as negatives. However, this methodology leads to a fundamental flaw during evaluation: since captions are marked as relevant only to their original video, many alternate videos also match the caption, which creates false-negative caption-video pairs. We show that when these false negatives are corrected, a recent state-of-the-art model gains 25% recall points -- a difference that threatens the validity of the benchmark itself. To diagnose and mitigate this issue, we annotate and release 683K additional caption-video pairs. Using these, we recompute effectiveness scores for three models on two standard benchmarks (MSR-VTT and MSVD). We find that (1) the recomputed metrics are up to 25% recall points higher for the best models, (2) these benchmarks are nearing saturation for Recall@10, (3) caption length (generality) is related to the number of positives, and (4) annotation costs can be mitigated by choosing evaluation sizes corresponding to desired effect size to detect. We recommend retiring these benchmarks in their current form and make recommendations for future text-to-video retrieval benchmarks.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022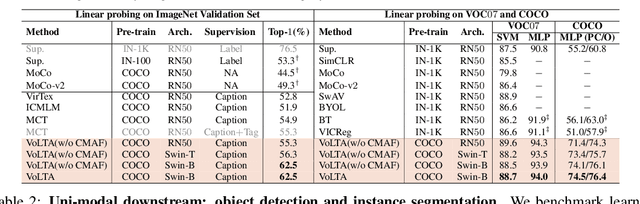
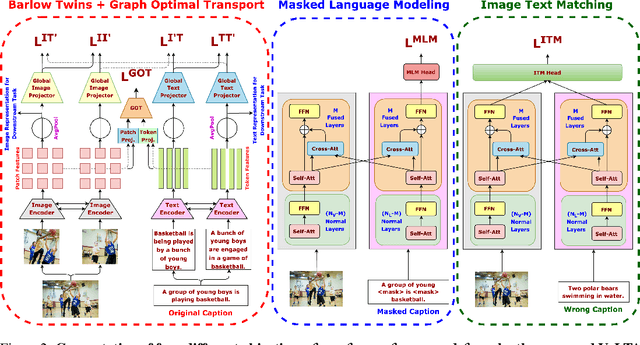
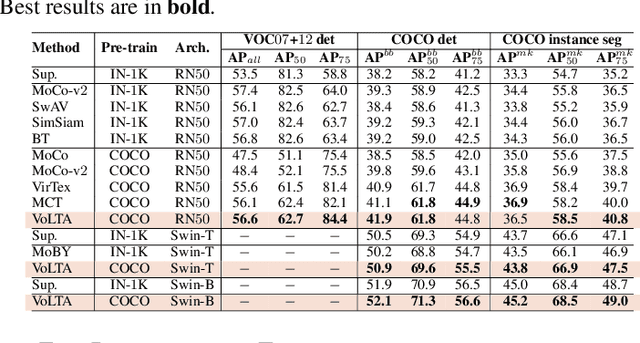

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.