 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visuotactile Skills with Two Multifingered Hands
Apr 25, 2024



Aiming to replicate human-like dexterity, perceptual experiences, and motion patterns, we explore learning from human demonstrations using a bimanual system with multifingered hands and visuotactile data. Two significant challenges exist: the lack of an affordable and accessible teleoperation system suitable for a dual-arm setup with multifingered hands, and the scarcity of multifingered hand hardware equipped with touch sensing. To tackle the first challenge, we develop HATO, a low-cost hands-arms teleoperation system that leverages off-the-shelf electronics, complemented with a software suite that enables efficient data collection; the comprehensive software suite also supports multimodal data processing, scalable policy learning, and smooth policy deployment. To tackle the latter challenge, we introduce a novel hardware adaptation by repurposing two prosthetic hands equipped with touch sensors for research. Using visuotactile data collected from our system, we learn skills to complete long-horizon, high-precision tasks which are difficult to achieve without multifingered dexterity and touch feedback. Furthermore, we empirically investigate the effects of dataset size, sensing modality, and visual input preprocessing on policy learning. Our results mark a promising step forward in bimanual multifingered manipulation from visuotactile data. Videos, code, and datasets can be found at https://toruowo.github.io/hato/ .
Twisting Lids Off with Two Hands
Mar 04, 2024



Manipulating objects with two multi-fingered hands has been a long-standing challenge in robotics, attributed to the contact-rich nature of many manipulation tasks and the complexity inherent in coordinating a high-dimensional bimanual system. In this work, we consider the problem of twisting lids of various bottle-like objects with two hands, and demonstrate that policies trained in simulation using deep reinforcement learning can be effectively transferred to the real world. With novel engineering insights into physical modeling, real-time perception, and reward design, the policy demonstrates generalization capabilities across a diverse set of unseen objects, showcasing dynamic and dexterous behaviors. Our findings serve as compelling evidence that deep reinforcement learning combined with sim-to-real transfer remains a promising approach for addressing manipulation problems of unprecedented complexity.
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
Perceiving Extrinsic Contacts from Touch Improves Learning Insertion Policies
Sep 28, 2023



Robotic manipulation tasks such as object insertion typically involve interactions between object and environment, namely extrinsic contacts. Prior work on Neural Contact Fields (NCF) use intrinsic tactile sensing between gripper and object to estimate extrinsic contacts in simulation. However, its effectiveness and utility in real-world tasks remains unknown. In this work, we improve NCF to enable sim-to-real transfer and use it to train policies for mug-in-cupholder and bowl-in-dishrack insertion tasks. We find our model NCF-v2, is capable of estimating extrinsic contacts in the real-world. Furthermore, our insertion policy with NCF-v2 outperforms policies without it, achieving 33% higher success and 1.36x faster execution on mug-in-cupholder, and 13% higher success and 1.27x faster execution on bowl-in-dishrack.
General In-Hand Object Rotation with Vision and Touch
Sep 28, 2023We introduce RotateIt, a system that enables fingertip-based object rotation along multiple axes by leveraging multimodal sensory inputs. Our system is trained in simulation, where it has access to ground-truth object shapes and physical properties. Then we distill it to operate on realistic yet noisy simulated visuotactile and proprioceptive sensory inputs. These multimodal inputs are fused via a visuotactile transformer, enabling online inference of object shapes and physical properties during deployment. We show significant performance improvements over prior methods and the importance of visual and tactile sensing.
In-Hand Object Rotation via Rapid Motor Adaptation
Oct 10, 2022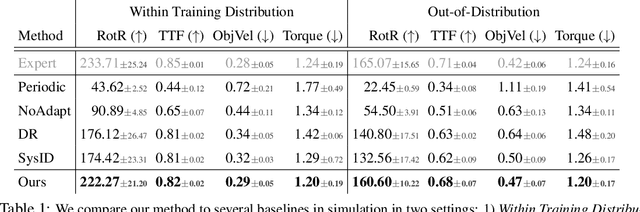
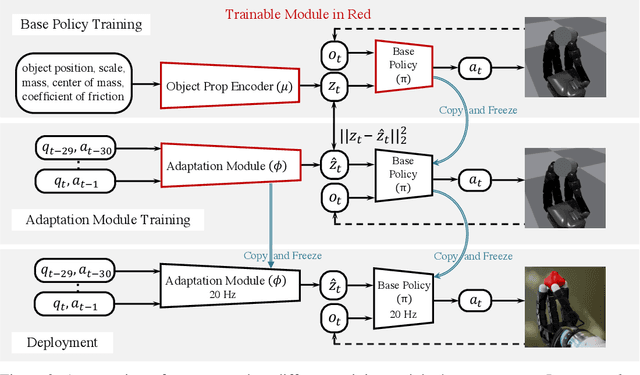


Generalized in-hand manipulation has long been an unsolved challenge of robotics. As a small step towards this grand goal, we demonstrate how to design and learn a simple adaptive controller to achieve in-hand object rotation using only fingertips. The controller is trained entirely in simulation on only cylindrical objects, which then - without any fine-tuning - can be directly deployed to a real robot hand to rotate dozens of objects with diverse sizes, shapes, and weights over the z-axis. This is achieved via rapid online adaptation of the controller to the object properties using only proprioception history. Furthermore, natural and stable finger gaits automatically emerge from training the control policy via reinforcement learning. Code and more videos are available at https://haozhi.io/hora
Coupling Vision and Proprioception for Navigation of Legged Robots
Dec 03, 2021
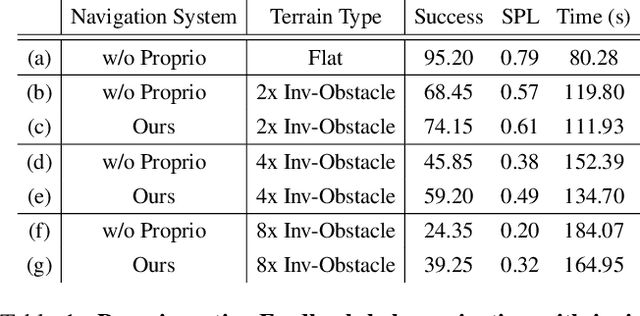
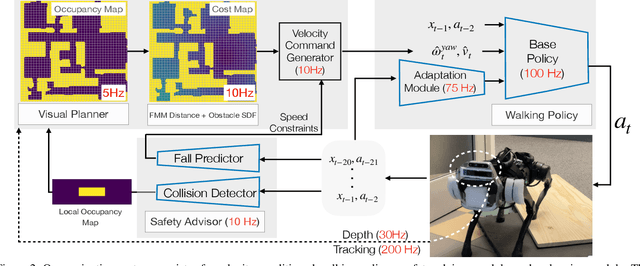
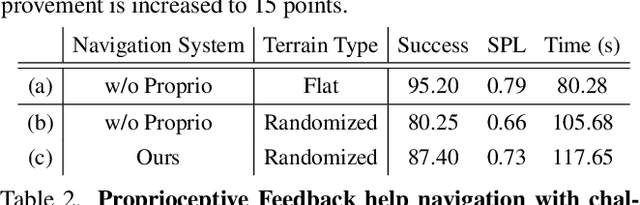
We exploit the complementary strengths of vision and proprioception to achieve point goal navigation in a legged robot. Legged systems are capable of traversing more complex terrain than wheeled robots, but to fully exploit this capability, we need the high-level path planner in the navigation system to be aware of the walking capabilities of the low-level locomotion policy on varying terrains. We achieve this by using proprioceptive feedback to estimate the safe operating limits of the walking policy, and to sense unexpected obstacles and terrain properties like smoothness or softness of the ground that may be missed by vision. The navigation system uses onboard cameras to generate an occupancy map and a corresponding cost map to reach the goal. The FMM (Fast Marching Method) planner then generates a target path. The velocity command generator takes this as input to generate the desired velocity for the locomotion policy using as input additional constraints, from the safety advisor, of unexpected obstacles and terrain determined speed limits. We show superior performance compared to wheeled robot (LoCoBot) baselines, and other baselines which have disjoint high-level planning and low-level control. We also show the real-world deployment of our system on a quadruped robot with onboard sensors and compute. Videos at https://navigation-locomotion.github.io/camera-ready
ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction
Jun 10, 2021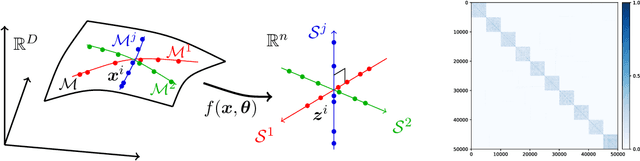
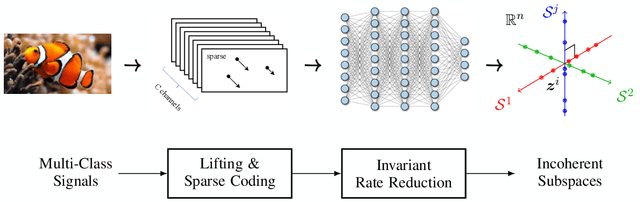

This work attempts to provide a plausible theoretical framework that aims to interpret modern deep (convolutional) networks from the principles of data compression and discriminative representation. We argue that for high-dimensional multi-class data, the optimal linear discriminative representation maximizes the coding rate difference between the whole dataset and the average of all the subsets. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction objective naturally leads to a multi-layer deep network, named ReduNet, which shares common characteristics of modern deep networks. The deep layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer via forward propagation, although they are amenable to fine-tuning via back propagation. All components of so-obtained ``white-box'' network have precise optimization, statistical, and geometric interpretation. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation in the invariant setting suggests a trade-off between sparsity and invariance, and also indicates that such a deep convolution network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments clearly verify the effectiveness of both the rate reduction objective and the associated ReduNet. All code and data are available at https://github.com/Ma-Lab-Berkeley.
Deep Networks from the Principle of Rate Reduction
Oct 27, 2020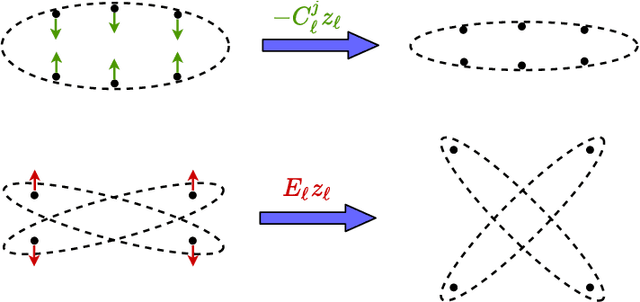
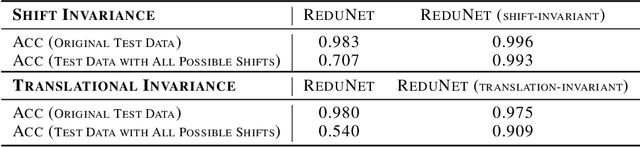

This work attempts to interpret modern deep (convolutional) networks from the principles of rate reduction and (shift) invariant classification. We show that the basic iterative gradient ascent scheme for optimizing the rate reduction of learned features naturally leads to a multi-layer deep network, one iteration per layer. The layered architectures, linear and nonlinear operators, and even parameters of the network are all explicitly constructed layer-by-layer in a forward propagation fashion by emulating the gradient scheme. All components of this "white box" network have precise optimization, statistical, and geometric interpretation. This principled framework also reveals and justifies the role of multi-channel lifting and sparse coding in early stage of deep networks. Moreover, all linear operators of the so-derived network naturally become multi-channel convolutions when we enforce classification to be rigorously shift-invariant. The derivation also indicates that such a convolutional network is significantly more efficient to construct and learn in the spectral domain. Our preliminary simulations and experiments indicate that so constructed deep network can already learn a good discriminative representation even without any back propagation training.
Learning Long-term Visual Dynamics with Region Proposal Interaction Networks
Aug 05, 2020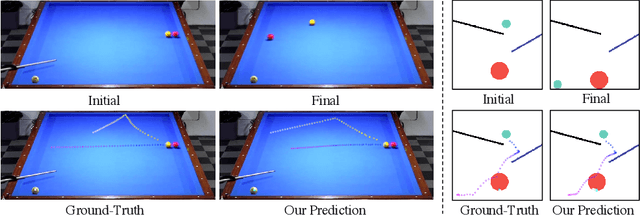
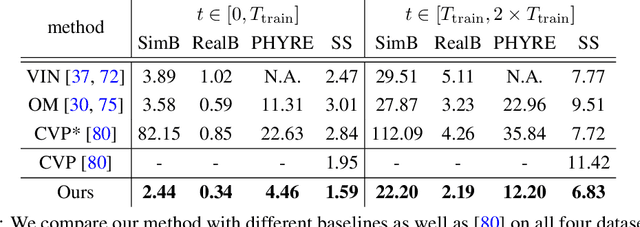
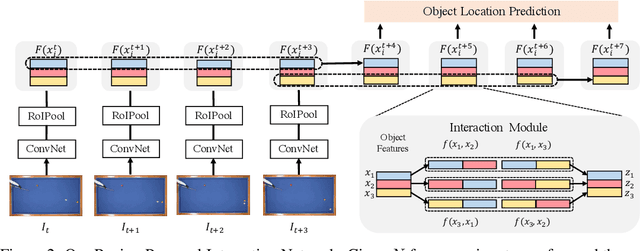
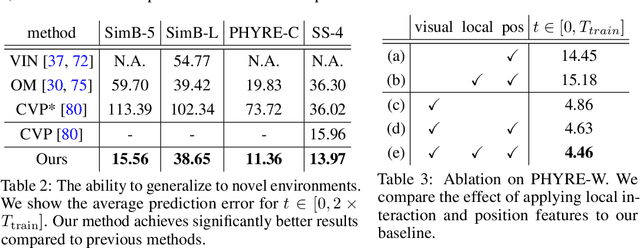
Learning long-term dynamics models is the key to understanding physical common sense. Most existing approaches on learning dynamics from visual input sidestep long-term predictions by resorting to rapid re-planning with short-term models. This not only requires such models to be super accurate but also limits them only to tasks where an agent can continuously obtain feedback and take action at each step until completion. In this paper, we aim to leverage the ideas from success stories in visual recognition tasks to build object representations that can capture inter-object and object-environment interactions over a long range. To this end, we propose Region Proposal Interaction Networks (RPIN), which reason about each object's trajectory in a latent region-proposal feature space. Thanks to the simple yet effective object representation, our approach outperforms prior methods by a significant margin both in terms of prediction quality and their ability to plan for downstream tasks, and also generalize well to novel environments. Our code is available at https://github.com/HaozhiQi/RPIN.