 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Orchestration of AI x DB Workloads
Mar 04, 2026AI-driven analytics are increasingly crucial to data-centric decision-making. The practice of exporting data to machine learning runtimes incurs high overhead, limits robustness to data drift, and expands the attack surface, especially in multi-tenant, heterogeneous data systems. Integrating AI directly into database engines, while offering clear benefits, introduces challenges in managing joint query processing and model execution, optimizing end-to-end performance, coordinating execution under resource contention, and enforcing strong security and access-control guarantees. This paper discusses the challenges of joint DB-AI, or AIxDB, data management and query processing within AI-powered data systems. It presents various challenges that need to be addressed carefully, such as query optimization, execution scheduling, and distributed execution over heterogeneous hardware. Database components such as transaction management and access control need to be re-examined to support AI lifecycle management, mitigate data drift, and protect sensitive data from unauthorized AI operations. We present a design and preliminary results to demonstrate what may be key to the performance for serving AIxDB queries.
NeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024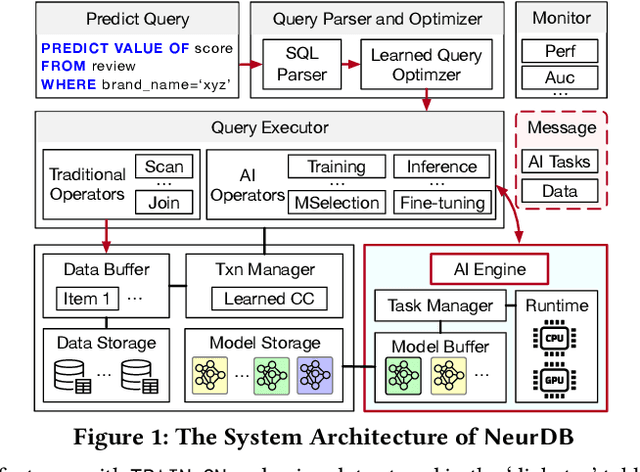
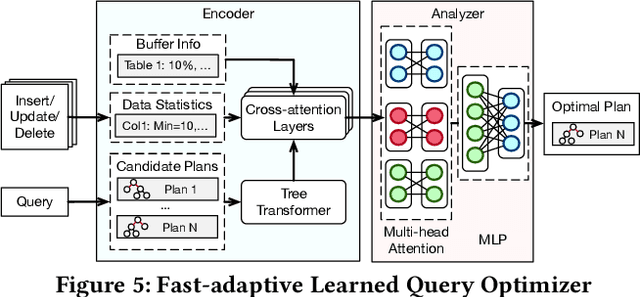
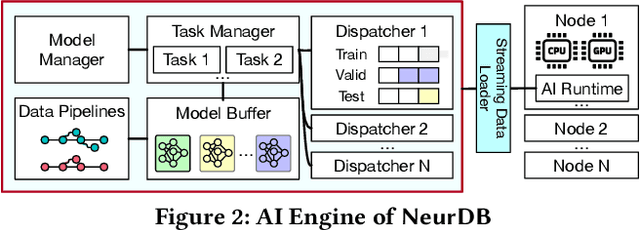
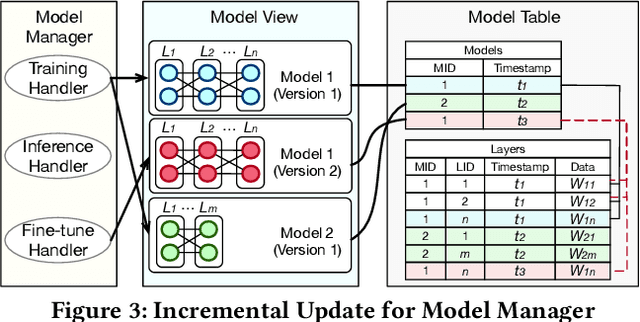
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
Clip Body and Tail Separately: High Probability Guarantees for DPSGD with Heavy Tails
May 27, 2024Differentially Private Stochastic Gradient Descent (DPSGD) is widely utilized to preserve training data privacy in deep learning, which first clips the gradients to a predefined norm and then injects calibrated noise into the training procedure. Existing DPSGD works typically assume the gradients follow sub-Gaussian distributions and design various clipping mechanisms to optimize training performance. However, recent studies have shown that the gradients in deep learning exhibit a heavy-tail phenomenon, that is, the tails of the gradient have infinite variance, which may lead to excessive clipping loss to the gradients with existing DPSGD mechanisms. To address this problem, we propose a novel approach, Discriminative Clipping~(DC)-DPSGD, with two key designs. First, we introduce a subspace identification technique to distinguish between body and tail gradients. Second, we present a discriminative clipping mechanism that applies different clipping thresholds for body and tail gradients to reduce the clipping loss. Under the non-convex condition, \ourtech{} reduces the empirical gradient norm from {${\mathbb{O}\left(\log^{\max(0,\theta-1)}(T/\delta)\log^{2\theta}(\sqrt{T})\right)}$} to {${\mathbb{O}\left(\log(\sqrt{T})\right)}$} with heavy-tailed index $\theta\geq 1/2$, iterations $T$, and arbitrary probability $\delta$. Extensive experiments on four real-world datasets demonstrate that our approach outperforms three baselines by up to 9.72\% in terms of accuracy.
NeurDB: An AI-powered Autonomous Data System
May 07, 2024In the wake of rapid advancements in artificial intelligence (AI), we stand on the brink of a transformative leap in data systems. The imminent fusion of AI and DB (AIxDB) promises a new generation of data systems, which will relieve the burden on end-users across all industry sectors by featuring AI-enhanced functionalities, such as personalized and automated in-database AI-powered analytics, self-driving capabilities for improved system performance, etc. In this paper, we explore the evolution of data systems with a focus on deepening the fusion of AI and DB. We present NeurDB, our next-generation data system designed to fully embrace AI design in each major system component and provide in-database AI-powered analytics. We outline the conceptual and architectural overview of NeurDB, discuss its design choices and key components, and report its current development and future plan.
Powering In-Database Dynamic Model Slicing for Structured Data Analytics
May 01, 2024



Relational database management systems (RDBMS) are widely used for the storage and retrieval of structured data. To derive insights beyond statistical aggregation, we typically have to extract specific subdatasets from the database using conventional database operations, and then apply deep neural networks (DNN) training and inference on these respective subdatasets in a separate machine learning system. The process can be prohibitively expensive, especially when there are a combinatorial number of subdatasets extracted for different analytical purposes. This calls for efficient in-database support of advanced analytical methods In this paper, we introduce LEADS, a novel SQL-aware dynamic model slicing technique to customize models for subdatasets specified by SQL queries. LEADS improves the predictive modeling of structured data via the mixture of experts (MoE) technique and maintains inference efficiency by a SQL-aware gating network. At the core of LEADS is the construction of a general model with multiple expert sub-models via MoE trained over the entire database. This SQL-aware MoE technique scales up the modeling capacity, enhances effectiveness, and preserves efficiency by activating only necessary experts via the gating network during inference. Additionally, we introduce two regularization terms during the training process of LEADS to strike a balance between effectiveness and efficiency. We also design and build an in-database inference system, called INDICES, to support end-to-end advanced structured data analytics by non-intrusively incorporating LEADS onto PostgreSQL. Our extensive experiments on real-world datasets demonstrate that LEADS consistently outperforms baseline models, and INDICES delivers effective in-database analytics with a considerable reduction in inference latency compared to traditional solutions.
Exploring Privacy and Fairness Risks in Sharing Diffusion Models: An Adversarial Perspective
Mar 04, 2024



Diffusion models have recently gained significant attention in both academia and industry due to their impressive generative performance in terms of both sampling quality and distribution coverage. Accordingly, proposals are made for sharing pre-trained diffusion models across different organizations, as a way of improving data utilization while enhancing privacy protection by avoiding sharing private data directly. However, the potential risks associated with such an approach have not been comprehensively examined. In this paper, we take an adversarial perspective to investigate the potential privacy and fairness risks associated with the sharing of diffusion models. Specifically, we investigate the circumstances in which one party (the sharer) trains a diffusion model using private data and provides another party (the receiver) black-box access to the pre-trained model for downstream tasks. We demonstrate that the sharer can execute fairness poisoning attacks to undermine the receiver's downstream models by manipulating the training data distribution of the diffusion model. Meanwhile, the receiver can perform property inference attacks to reveal the distribution of sensitive features in the sharer's dataset. Our experiments conducted on real-world datasets demonstrate remarkable attack performance on different types of diffusion models, which highlights the critical importance of robust data auditing and privacy protection protocols in pertinent applications.
Secure and Verifiable Data Collaboration with Low-Cost Zero-Knowledge Proofs
Nov 26, 2023



Organizations are increasingly recognizing the value of data collaboration for data analytics purposes. Yet, stringent data protection laws prohibit the direct exchange of raw data. To facilitate data collaboration, federated Learning (FL) emerges as a viable solution, which enables multiple clients to collaboratively train a machine learning (ML) model under the supervision of a central server while ensuring the confidentiality of their raw data. However, existing studies have unveiled two main risks: (i) the potential for the server to infer sensitive information from the client's uploaded updates (i.e., model gradients), compromising client input privacy, and (ii) the risk of malicious clients uploading malformed updates to poison the FL model, compromising input integrity. Recent works utilize secure aggregation with zero-knowledge proofs (ZKP) to guarantee input privacy and integrity in FL. Nevertheless, they suffer from extremely low efficiency and, thus, are impractical for real deployment. In this paper, we propose a novel and highly efficient solution RiseFL for secure and verifiable data collaboration, ensuring input privacy and integrity simultaneously.Firstly, we devise a probabilistic integrity check method that significantly reduces the cost of ZKP generation and verification. Secondly, we design a hybrid commitment scheme to satisfy Byzantine robustness with improved performance. Thirdly, we theoretically prove the security guarantee of the proposed solution. Extensive experiments on synthetic and real-world datasets suggest that our solution is effective and is highly efficient in both client computation and communication. For instance, RiseFL is up to 28x, 53x and 164x faster than three state-of-the-art baselines ACORN, RoFL and EIFFeL for the client computation.
Passive Inference Attacks on Split Learning via Adversarial Regularization
Oct 16, 2023



Split Learning (SL) has emerged as a practical and efficient alternative to traditional federated learning. While previous attempts to attack SL have often relied on overly strong assumptions or targeted easily exploitable models, we seek to develop more practical attacks. We introduce SDAR, a novel attack framework against SL with an honest-but-curious server. SDAR leverages auxiliary data and adversarial regularization to learn a decodable simulator of the client's private model, which can effectively infer the client's private features under the vanilla SL, and both features and labels under the U-shaped SL. We perform extensive experiments in both configurations to validate the effectiveness of our proposed attacks. Notably, in challenging but practical scenarios where existing passive attacks struggle to reconstruct the client's private data effectively, SDAR consistently achieves attack performance comparable to active attacks. On CIFAR-10, at the deep split level of 7, SDAR achieves private feature reconstruction with less than 0.025 mean squared error in both the vanilla and the U-shaped SL, and attains a label inference accuracy of over 98% in the U-shaped setting, while existing attacks fail to produce non-trivial results.
A Fusion-Denoising Attack on InstaHide with Data Augmentation
May 17, 2021


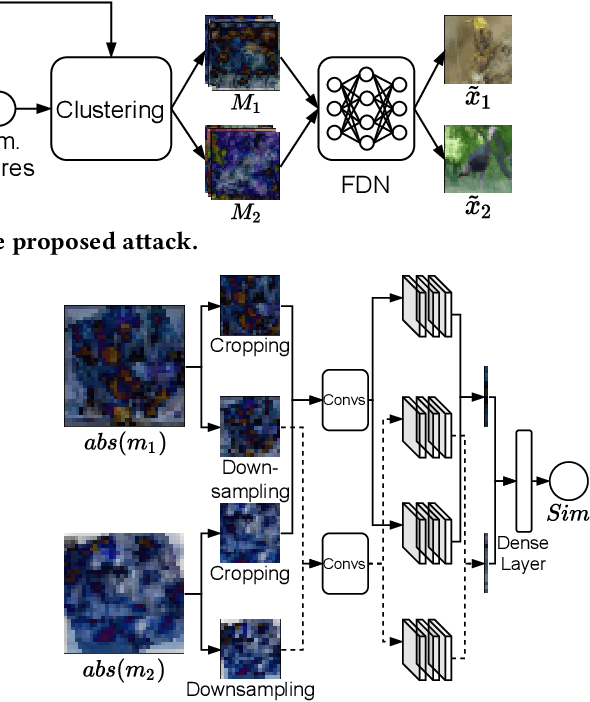
InstaHide is a state-of-the-art mechanism for protecting private training images in collaborative learning. It works by mixing multiple private images and modifying them in such a way that their visual features are no longer distinguishable to the naked eye, without significantly degrading the accuracy of training. In recent work, however, Carlini et al. show that it is possible to reconstruct private images from the encrypted dataset generated by InstaHide, by exploiting the correlations among the encrypted images. Nevertheless, Carlini et al.'s attack relies on the assumption that each private image is used without modification when mixing up with other private images. As a consequence, it could be easily defeated by incorporating data augmentation into InstaHide. This leads to a natural question: is InstaHide with data augmentation secure? This paper provides a negative answer to the above question, by present an attack for recovering private images from the outputs of InstaHide even when data augmentation is present. The basic idea of our attack is to use a comparative network to identify encrypted images that are likely to correspond to the same private image, and then employ a fusion-denoising network for restoring the private image from the encrypted ones, taking into account the effects of data augmentation. Extensive experiments demonstrate the effectiveness of the proposed attack in comparison to Carlini et al.'s attack.
Serverless Model Serving for Data Science
Mar 04, 2021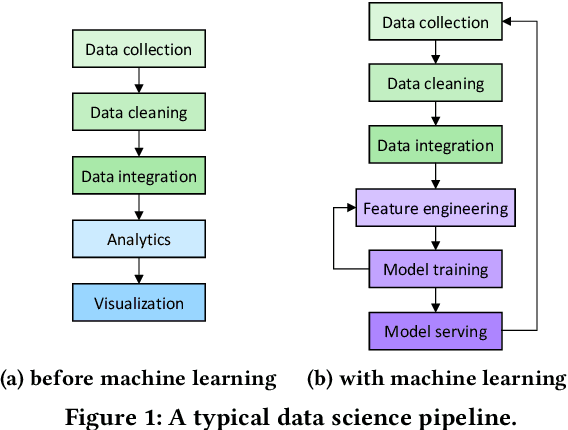
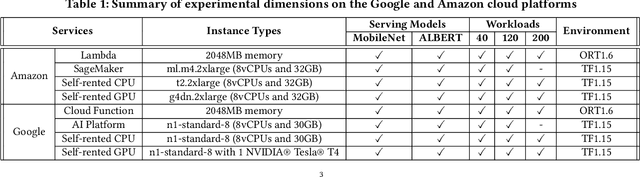
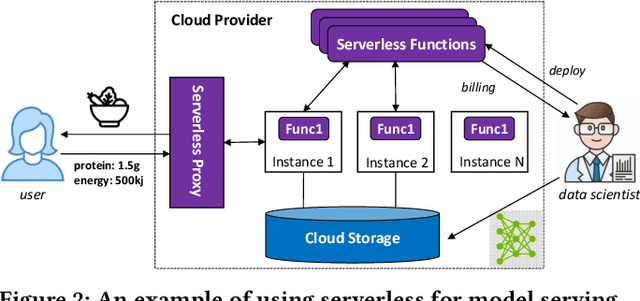
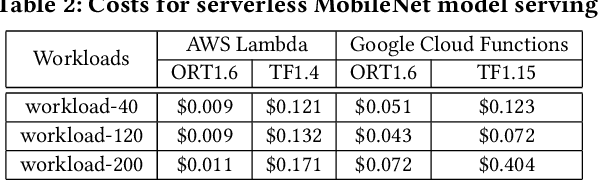
Machine learning (ML) is an important part of modern data science applications. Data scientists today have to manage the end-to-end ML life cycle that includes both model training and model serving, the latter of which is essential, as it makes their works available to end-users. Systems for model serving require high performance, low cost, and ease of management. Cloud providers are already offering model serving options, including managed services and self-rented servers. Recently, serverless computing, whose advantages include high elasticity and fine-grained cost model, brings another possibility for model serving. In this paper, we study the viability of serverless as a mainstream model serving platform for data science applications. We conduct a comprehensive evaluation of the performance and cost of serverless against other model serving systems on two clouds: Amazon Web Service (AWS) and Google Cloud Platform (GCP). We find that serverless outperforms many cloud-based alternatives with respect to cost and performance. More interestingly, under some circumstances, it can even outperform GPU-based systems for both average latency and cost. These results are different from previous works' claim that serverless is not suitable for model serving, and are contrary to the conventional wisdom that GPU-based systems are better for ML workloads than CPU-based systems. Other findings include a large gap in cold start time between AWS and GCP serverless functions, and serverless' low sensitivity to changes in workloads or models. Our evaluation results indicate that serverless is a viable option for model serving. Finally, we present several practical recommendations for data scientists on how to use serverless for scalable and cost-effective model serving.