 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaView: Few-shot Active Object Recognition
Mar 07, 2021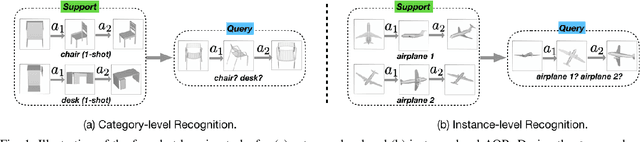
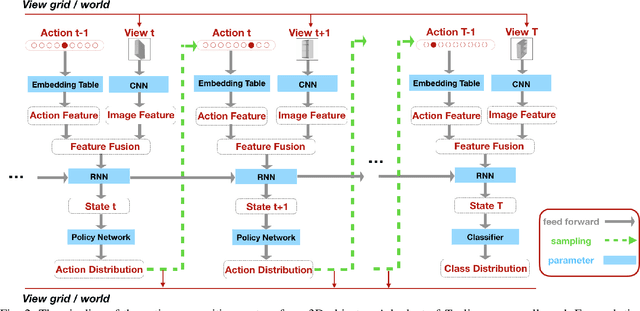
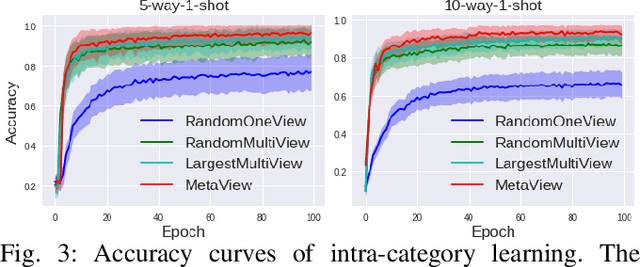
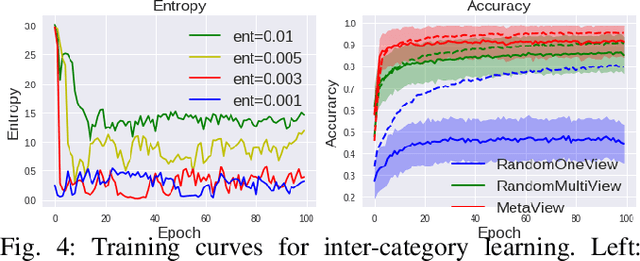
In robot sensing scenarios, instead of passively utilizing human captured views, an agent should be able to actively choose informative viewpoints of a 3D object as discriminative evidence to boost the recognition accuracy. This task is referred to as active object recognition. Recent works on this task rely on a massive amount of training examples to train an optimal view selection policy. But in realistic robot sensing scenarios, the large-scale training data may not exist and whether the intelligent view selection policy can be still learned from few object samples remains unclear. In this paper, we study this new problem which is extremely challenging but very meaningful in robot sensing -- Few-shot Active Object Recognition, i.e., to learn view selection policies from few object samples, which has not been considered and addressed before. We solve the proposed problem by adopting the framework of meta learning and name our method "MetaView". Extensive experiments on both category-level and instance-level classification tasks demonstrate that the proposed method can efficiently resolve issues that are hard for state-of-the-art active object recognition methods to handle, and outperform several baselines by large margins.
Hierarchical Reinforcement Learning By Discovering Intrinsic Options
Jan 16, 2021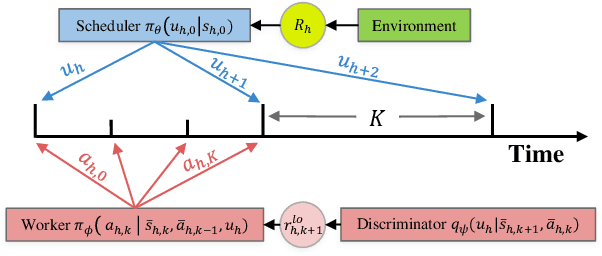
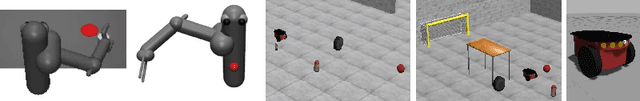


We propose a hierarchical reinforcement learning method, HIDIO, that can learn task-agnostic options in a self-supervised manner while jointly learning to utilize them to solve sparse-reward tasks. Unlike current hierarchical RL approaches that tend to formulate goal-reaching low-level tasks or pre-define ad hoc lower-level policies, HIDIO encourages lower-level option learning that is independent of the task at hand, requiring few assumptions or little knowledge about the task structure. These options are learned through an intrinsic entropy minimization objective conditioned on the option sub-trajectories. The learned options are diverse and task-agnostic. In experiments on sparse-reward robotic manipulation and navigation tasks, HIDIO achieves higher success rates with greater sample efficiency than regular RL baselines and two state-of-the-art hierarchical RL methods.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.
CraftAssist: A Framework for Dialogue-enabled Interactive Agents
Jul 19, 2019
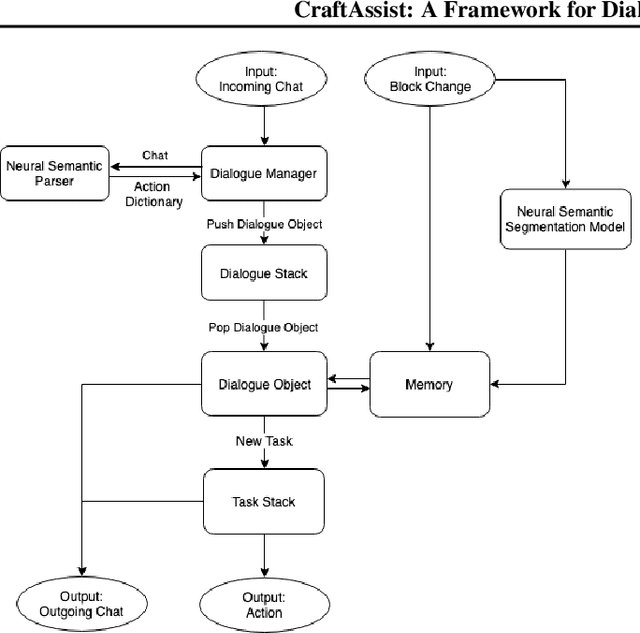
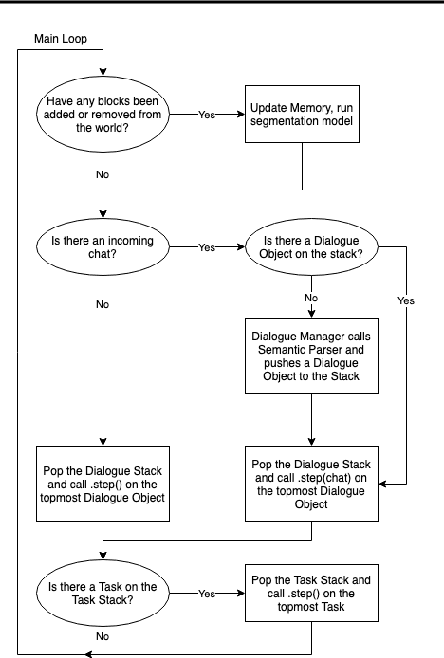
This paper describes an implementation of a bot assistant in Minecraft, and the tools and platform allowing players to interact with the bot and to record those interactions. The purpose of building such an assistant is to facilitate the study of agents that can complete tasks specified by dialogue, and eventually, to learn from dialogue interactions.
EPNAS: Efficient Progressive Neural Architecture Search
Jul 07, 2019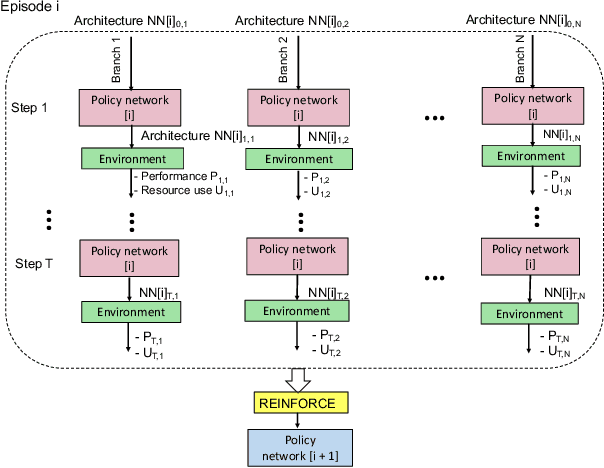
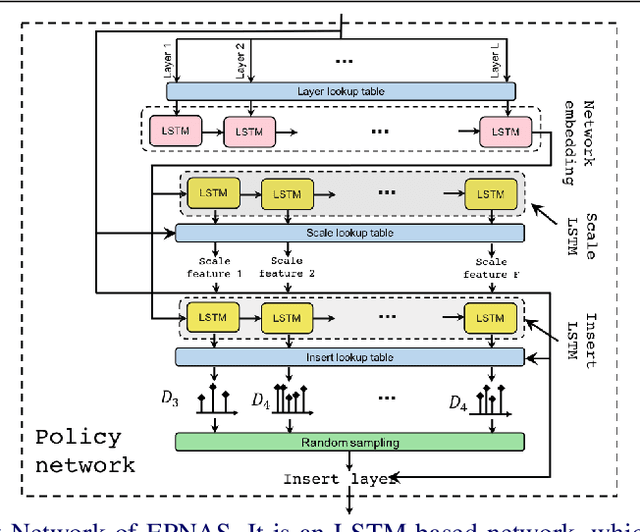
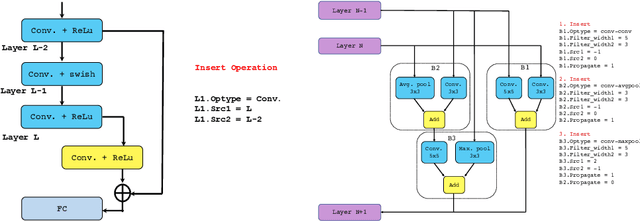
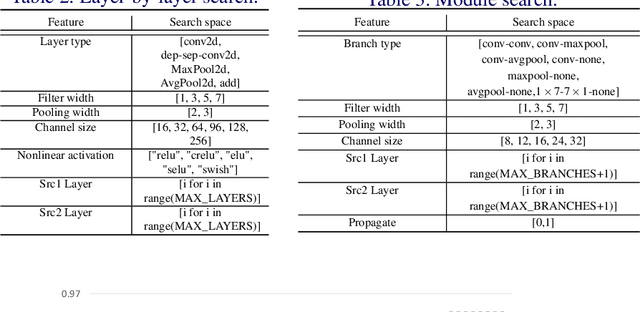
In this paper, we propose Efficient Progressive Neural Architecture Search (EPNAS), a neural architecture search (NAS) that efficiently handles large search space through a novel progressive search policy with performance prediction based on REINFORCE~\cite{Williams.1992.PG}. EPNAS is designed to search target networks in parallel, which is more scalable on parallel systems such as GPU/TPU clusters. More importantly, EPNAS can be generalized to architecture search with multiple resource constraints, \eg, model size, compute complexity or intensity, which is crucial for deployment in widespread platforms such as mobile and cloud. We compare EPNAS against other state-of-the-art (SoTA) network architectures (\eg, MobileNetV2~\cite{mobilenetv2}) and efficient NAS algorithms (\eg, ENAS~\cite{pham2018efficient}, and PNAS~\cite{Liu2017b}) on image recognition tasks using CIFAR10 and ImageNet. On both datasets, EPNAS is superior \wrt architecture searching speed and recognition accuracy.
One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers
Jun 06, 2019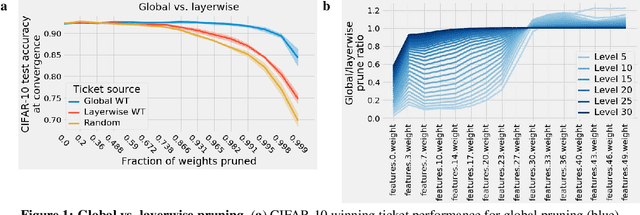
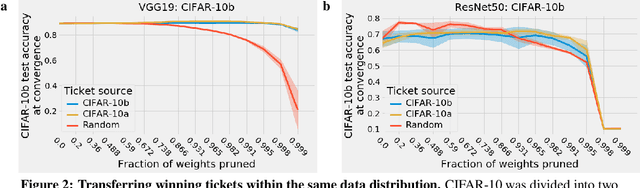
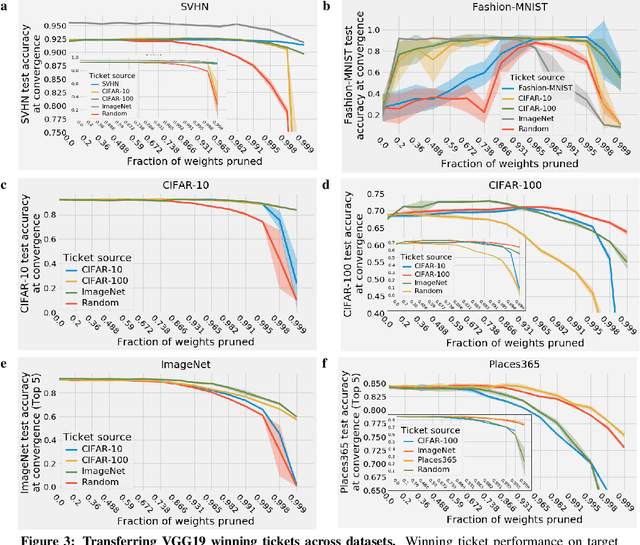
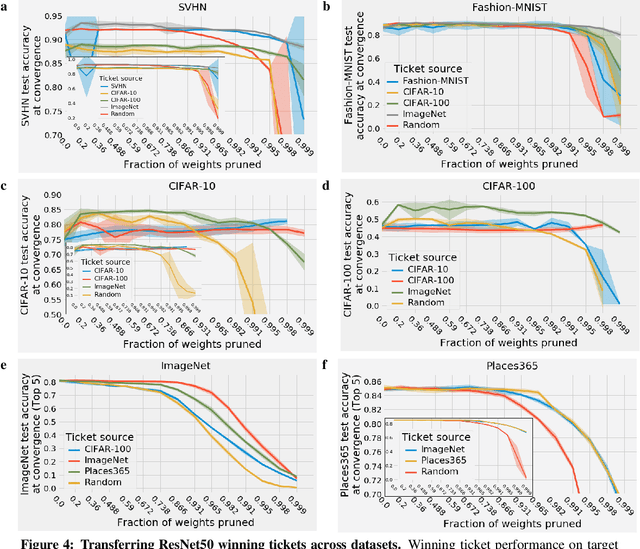
The success of lottery ticket initializations (Frankle and Carbin, 2019) suggests that small, sparsified networks can be trained so long as the network is initialized appropriately. Unfortunately, finding these "winning ticket" initializations is computationally expensive. One potential solution is to reuse the same winning tickets across a variety of datasets and optimizers. However, the generality of winning ticket initializations remains unclear. Here, we attempt to answer this question by generating winning tickets for one training configuration (optimizer and dataset) and evaluating their performance on another configuration. Perhaps surprisingly, we found that, within the natural images domain, winning ticket initializations generalized across a variety of datasets, including Fashion MNIST, SVHN, CIFAR-10/100, ImageNet, and Places365, often achieving performance close to that of winning tickets generated on the same dataset. Moreover, winning tickets generated using larger datasets consistently transferred better than those generated using smaller datasets. We also found that winning ticket initializations generalize across optimizers with high performance. These results suggest that winning ticket initializations contain inductive biases generic to neural networks more broadly which improve training across many settings and provide hope for the development of better initialization methods.
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
Jun 06, 2019
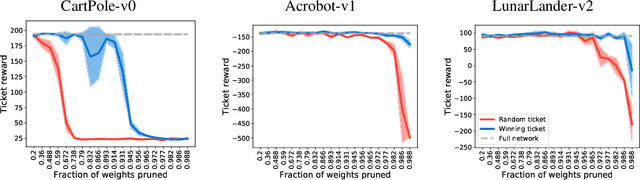
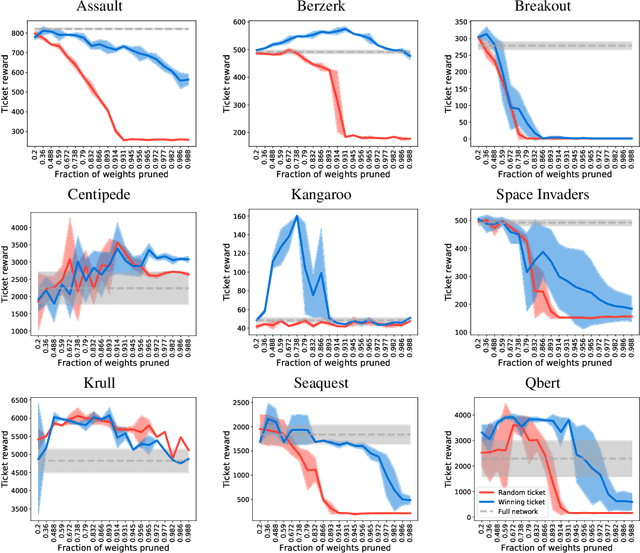
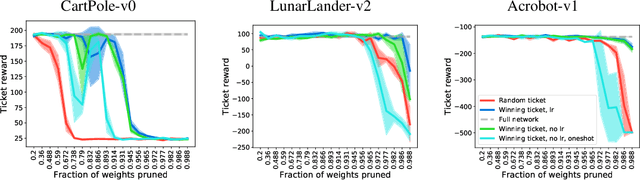
The lottery ticket hypothesis proposes that over-parameterization of deep neural networks (DNNs) aids training by increasing the probability of a "lucky" sub-network initialization being present rather than by helping the optimization process. This phenomenon is intriguing and suggests that initialization strategies for DNNs can be improved substantially, but the lottery ticket hypothesis has only previously been tested in the context of supervised learning for natural image tasks. Here, we evaluate whether "winning ticket" initializations exist in two different domains: reinforcement learning (RL) and in natural language processing (NLP). For RL, we analyzed a number of discrete-action space tasks, including both classic control and pixel control. For NLP, we examined both recurrent LSTM models and large-scale Transformer models. Consistent with work in supervised image classification, we confirm that winning ticket initializations generally outperform parameter-matched random initializations, even at extreme pruning rates. Together, these results suggest that the lottery ticket hypothesis is not restricted to supervised learning of natural images, but rather represents a broader phenomenon in DNNs.
Guided Feature Transformation (GFT): A Neural Language Grounding Module for Embodied Agents
Sep 04, 2018

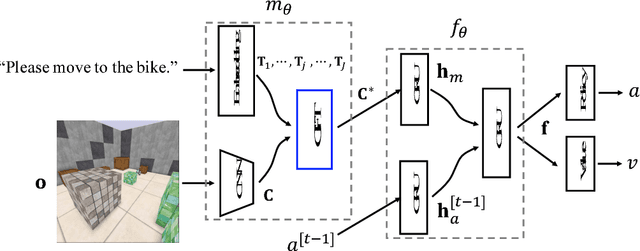
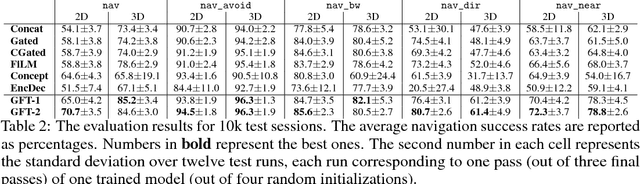
Recently there has been a rising interest in training agents, embodied in virtual environments, to perform language-directed tasks by deep reinforcement learning. In this paper, we propose a simple but effective neural language grounding module for embodied agents that can be trained end to end from scratch taking raw pixels, unstructured linguistic commands, and sparse rewards as the inputs. We model the language grounding process as a language-guided transformation of visual features, where latent sentence embeddings are used as the transformation matrices. In several language-directed navigation tasks that feature challenging partial observability and require simple reasoning, our module significantly outperforms the state of the art. We also release XWorld3D, an easy-to-customize 3D environment that can potentially be modified to evaluate a variety of embodied agents.
Interactive Grounded Language Acquisition and Generalization in a 2D World
Aug 13, 2018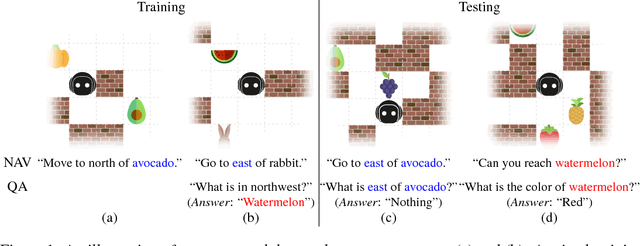

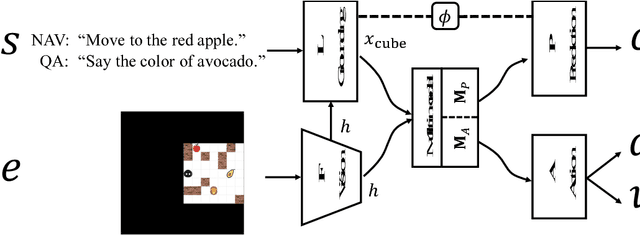
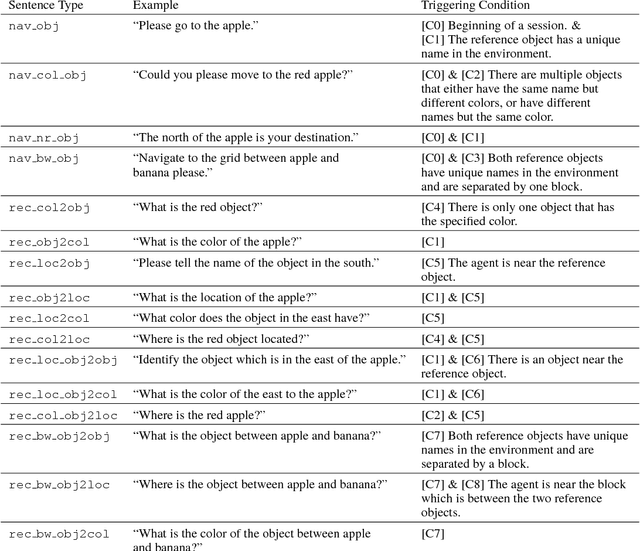
We build a virtual agent for learning language in a 2D maze-like world. The agent sees images of the surrounding environment, listens to a virtual teacher, and takes actions to receive rewards. It interactively learns the teacher's language from scratch based on two language use cases: sentence-directed navigation and question answering. It learns simultaneously the visual representations of the world, the language, and the action control. By disentangling language grounding from other computational routines and sharing a concept detection function between language grounding and prediction, the agent reliably interpolates and extrapolates to interpret sentences that contain new word combinations or new words missing from training sentences. The new words are transferred from the answers of language prediction. Such a language ability is trained and evaluated on a population of over 1.6 million distinct sentences consisting of 119 object words, 8 color words, 9 spatial-relation words, and 50 grammatical words. The proposed model significantly outperforms five comparison methods for interpreting zero-shot sentences. In addition, we demonstrate human-interpretable intermediate outputs of the model in the appendix.
Resource-Efficient Neural Architect
Jun 12, 2018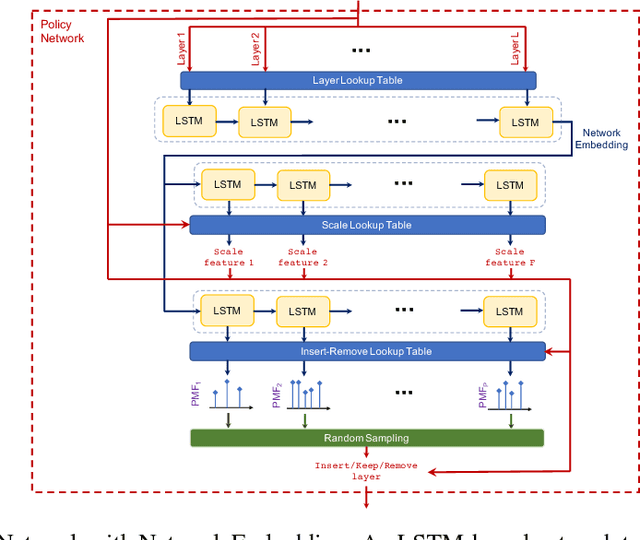
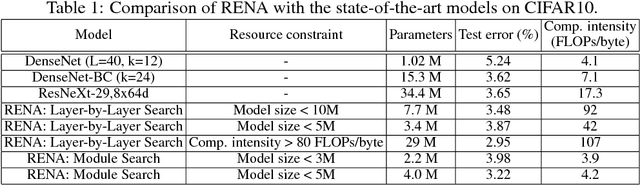
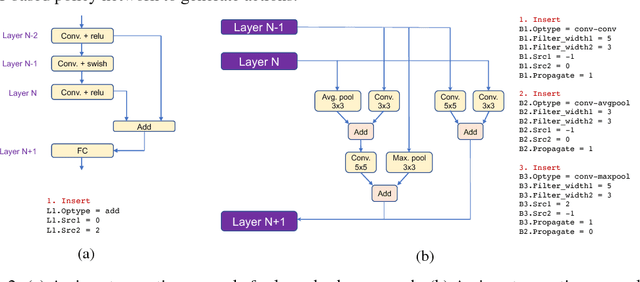
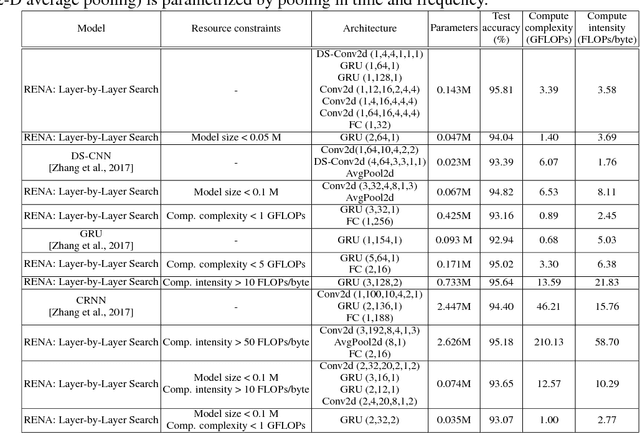
Neural Architecture Search (NAS) is a laborious process. Prior work on automated NAS targets mainly on improving accuracy, but lacks consideration of computational resource use. We propose the Resource-Efficient Neural Architect (RENA), an efficient resource-constrained NAS using reinforcement learning with network embedding. RENA uses a policy network to process the network embeddings to generate new configurations. We demonstrate RENA on image recognition and keyword spotting (KWS) problems. RENA can find novel architectures that achieve high performance even with tight resource constraints. For CIFAR10, it achieves 2.95% test error when compute intensity is greater than 100 FLOPs/byte, and 3.87% test error when model size is less than 3M parameters. For Google Speech Commands Dataset, RENA achieves the state-of-the-art accuracy without resource constraints, and it outperforms the optimized architectures with tight resource constraints.