 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Based Action-Model Acquisition for Planning
Feb 18, 2022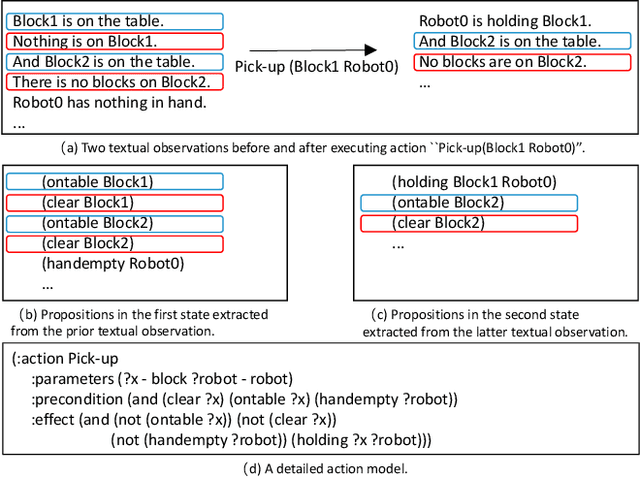
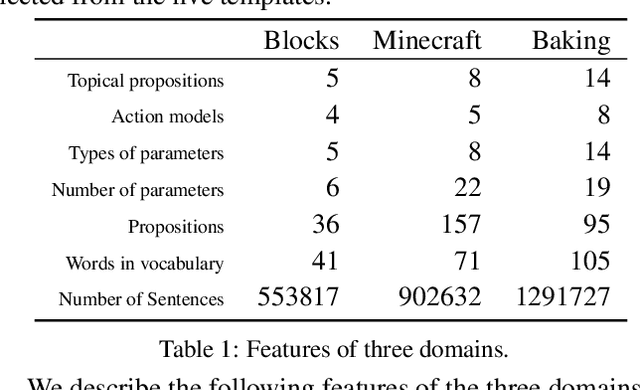
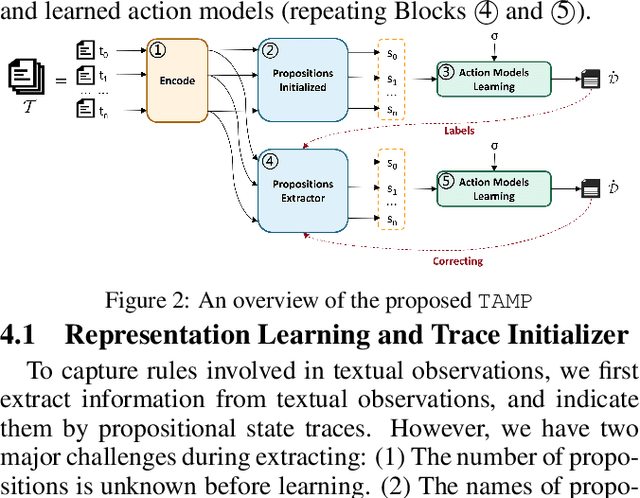

Although there have been approaches that are capable of learning action models from plan traces, there is no work on learning action models from textual observations, which is pervasive and much easier to collect from real-world applications compared to plan traces. In this paper we propose a novel approach to learning action models from natural language texts by integrating Constraint Satisfaction and Natural Language Processing techniques. Specifically, we first build a novel language model to extract plan traces from texts, and then build a set of constraints to generate action models based on the extracted plan traces. After that, we iteratively improve the language model and constraints until we achieve the convergent language model and action models. We empirically exhibit that our approach is both effective and efficient.
Integrating AI Planning with Natural Language Processing: A Combination of Explicit and Tacit Knowledge
Feb 15, 2022Automated planning focuses on strategies, building domain models and synthesizing plans to transit initial states to goals. Natural language processing concerns with the interactions between agents and human language, especially processing and analyzing large amounts of natural language data. These two fields have abilities to generate explicit knowledge, e.g., preconditions and effects of action models, and learn from tacit knowledge, e.g., neural models, respectively. Integrating AI planning and natural language processing effectively improves the communication between human and intelligent agents. This paper outlines the commons and relations between AI planning and natural language processing, argues that each of them can effectively impact on the other one by four areas: (1) planning-based text understanding, (2) planning-based text generation, (3) text-based human-robot interaction, and (4) text-based explainable planning. We also explore some potential future issues between AI planning and natural language processing.
Introduction to The Dynamic Pickup and Delivery Problem Benchmark -- ICAPS 2021 Competition
Jan 19, 2022The Dynamic Pickup and Delivery Problem (DPDP) is an essential problem within the logistics domain. So far, research on this problem has mainly focused on using artificial data which fails to reflect the complexity of real-world problems. In this draft, we would like to introduce a new benchmark from real business scenarios as well as a simulator supporting the dynamic evaluation. The benchmark and simulator have been published and successfully supported the ICAPS 2021 Dynamic Pickup and Delivery Problem competition participated by 152 teams.
Creativity of AI: Automatic Symbolic Option Discovery for Facilitating Deep Reinforcement Learning
Dec 18, 2021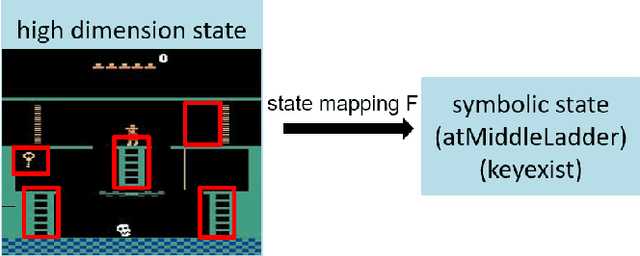


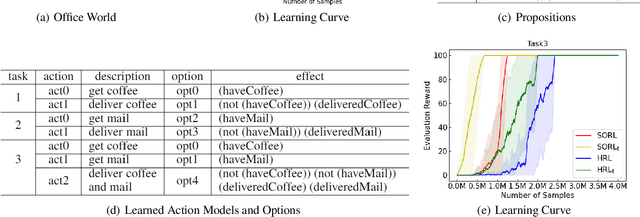
Despite of achieving great success in real life, Deep Reinforcement Learning (DRL) is still suffering from three critical issues, which are data efficiency, lack of the interpretability and transferability. Recent research shows that embedding symbolic knowledge into DRL is promising in addressing those challenges. Inspired by this, we introduce a novel deep reinforcement learning framework with symbolic options. This framework features a loop training procedure, which enables guiding the improvement of policy by planning with action models and symbolic options learned from interactive trajectories automatically. The learned symbolic options alleviate the dense requirement of expert domain knowledge and provide inherent interpretability of policies. Moreover, the transferability and data efficiency can be further improved by planning with the action models. To validate the effectiveness of this framework, we conduct experiments on two domains, Montezuma's Revenge and Office World, respectively. The results demonstrate the comparable performance, improved data efficiency, interpretability and transferability.
Retrosynthetic Planning with Experience-Guided Monte Carlo Tree Search
Dec 11, 2021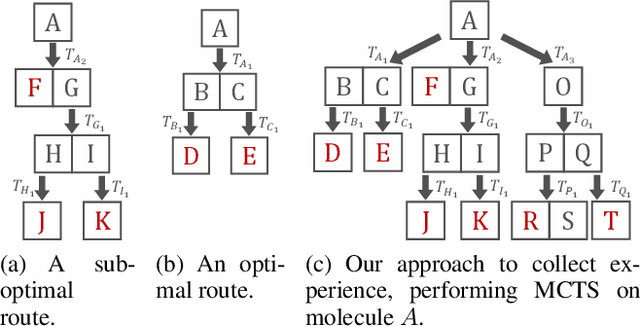
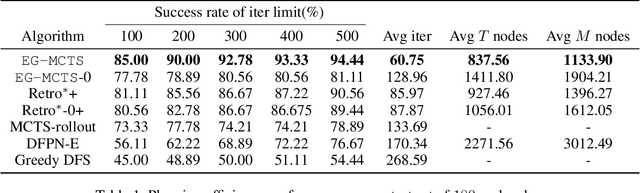
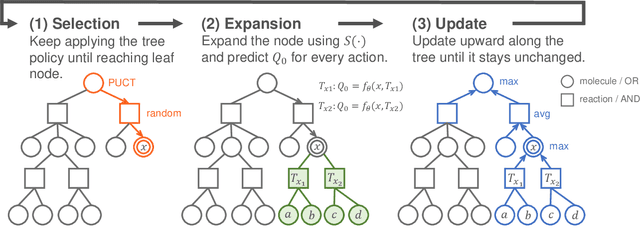
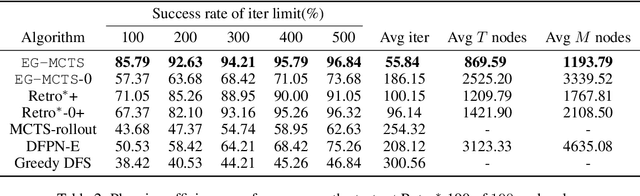
Retrosynthetic planning problem is to analyze a complex molecule and give a synthetic route using simple building blocks. The huge number of chemical reactions leads to a combinatorial explosion of possibilities, and even the experienced chemists could not select the most promising transformations. The current approaches rely on human-defined or machine-trained score functions which have limited chemical knowledge or use expensive estimation methods such as rollout to guide the search. In this paper, we propose {\tt MCTS}, a novel MCTS-based retrosynthetic planning approach, to deal with retrosynthetic planning problem. Instead of exploiting rollout, we build an Experience Guidance Network to learn knowledge from synthetic experiences during the search. Experiments on benchmark USPTO datasets show that, our {\tt MCTS} gains significant improvement over state-of-the-art approaches both in efficiency and effectiveness.
Lifelong Reinforcement Learning with Temporal Logic Formulas and Reward Machines
Nov 18, 2021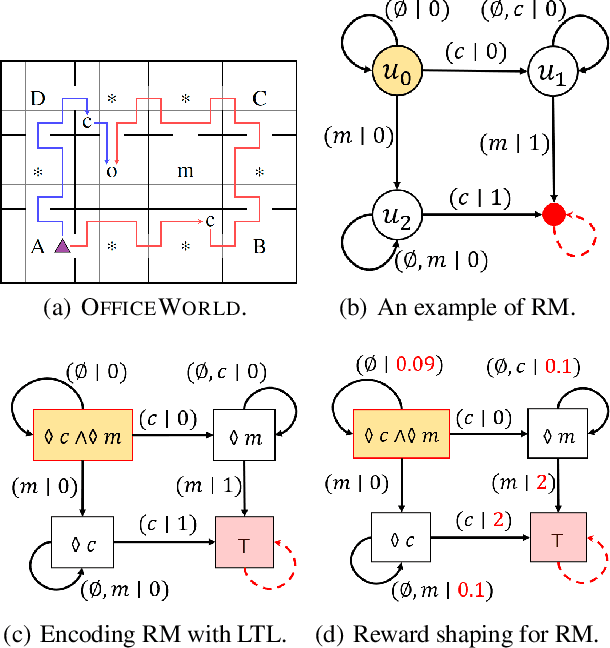
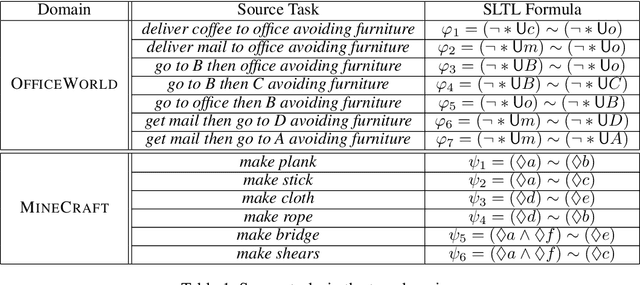
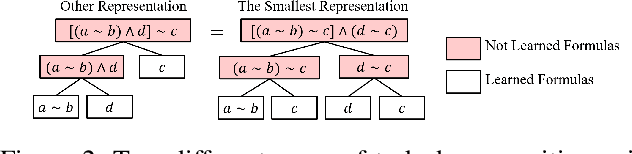
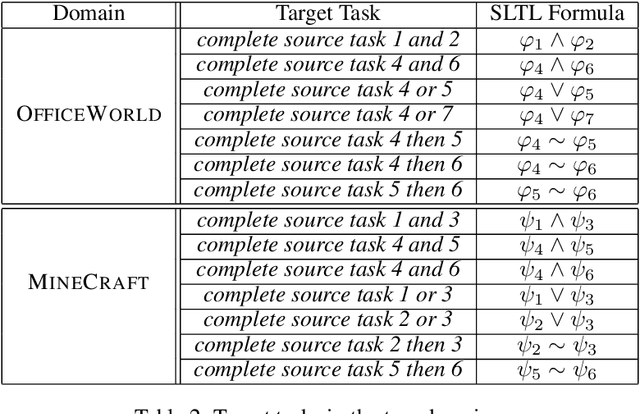
Continuously learning new tasks using high-level ideas or knowledge is a key capability of humans. In this paper, we propose Lifelong reinforcement learning with Sequential linear temporal logic formulas and Reward Machines (LSRM), which enables an agent to leverage previously learned knowledge to fasten learning of logically specified tasks. For the sake of more flexible specification of tasks, we first introduce Sequential Linear Temporal Logic (SLTL), which is a supplement to the existing Linear Temporal Logic (LTL) formal language. We then utilize Reward Machines (RM) to exploit structural reward functions for tasks encoded with high-level events, and propose automatic extension of RM and efficient knowledge transfer over tasks for continuous learning in lifetime. Experimental results show that LSRM outperforms the methods that learn the target tasks from scratch by taking advantage of the task decomposition using SLTL and knowledge transfer over RM during the lifelong learning process.
Coordinated Proximal Policy Optimization
Nov 07, 2021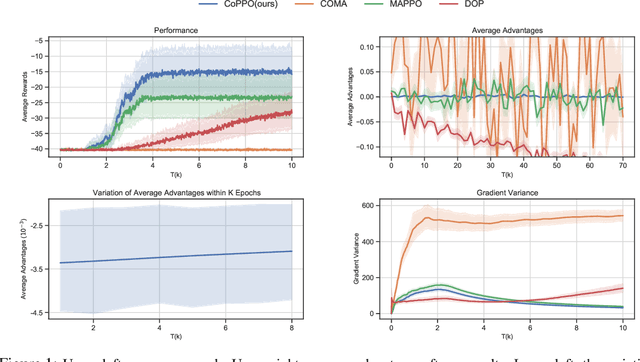
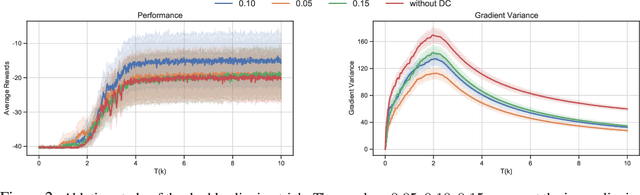
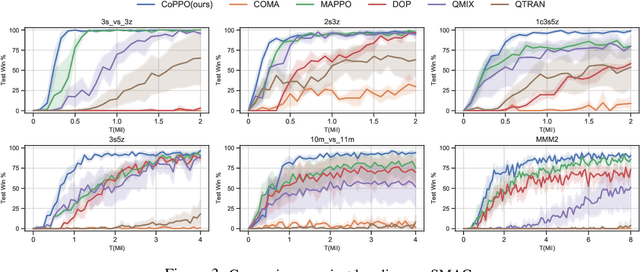
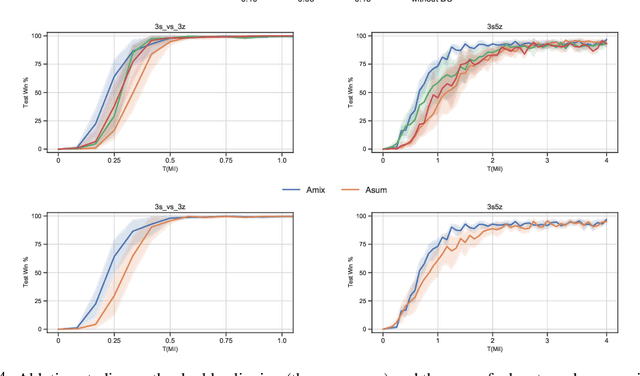
We present Coordinated Proximal Policy Optimization (CoPPO), an algorithm that extends the original Proximal Policy Optimization (PPO) to the multi-agent setting. The key idea lies in the coordinated adaptation of step size during the policy update process among multiple agents. We prove the monotonicity of policy improvement when optimizing a theoretically-grounded joint objective, and derive a simplified optimization objective based on a set of approximations. We then interpret that such an objective in CoPPO can achieve dynamic credit assignment among agents, thereby alleviating the high variance issue during the concurrent update of agent policies. Finally, we demonstrate that CoPPO outperforms several strong baselines and is competitive with the latest multi-agent PPO method (i.e. MAPPO) under typical multi-agent settings, including cooperative matrix games and the StarCraft II micromanagement tasks.
Gradient-Based Mixed Planning with Discrete and Continuous Actions
Oct 19, 2021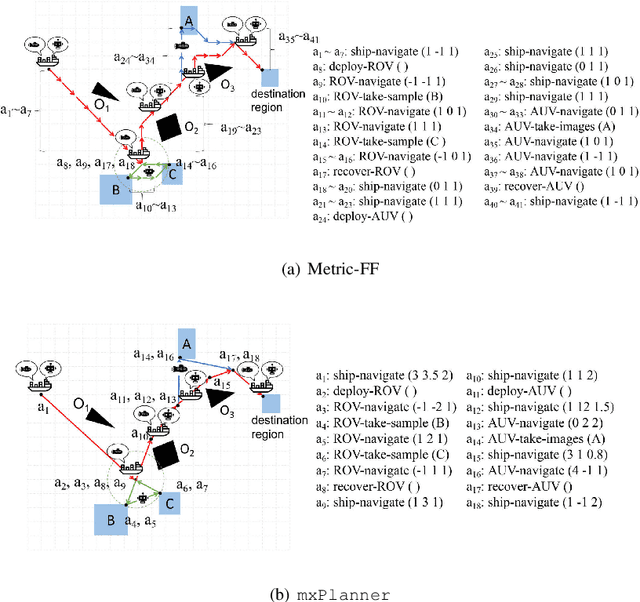
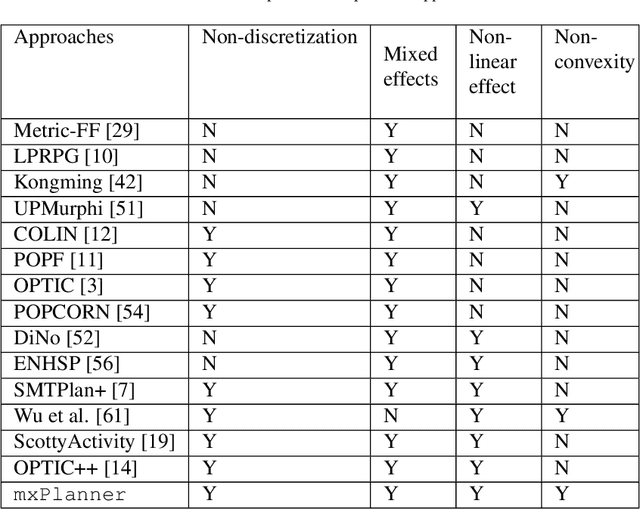


Dealing with planning problems with both discrete logical relations and continuous numeric changes in real-world dynamic environments is challenging. Existing numeric planning systems for the problem often discretize numeric variables or impose convex quadratic constraints on numeric variables, which harms the performance when solving the problem. In this paper, we propose a novel algorithm framework to solve the numeric planning problems mixed with discrete and continuous actions based on gradient descent. We cast the numeric planning with discrete and continuous actions as an optimization problem by integrating a heuristic function based on discrete effects. Specifically, we propose a gradient-based framework to simultaneously optimize continuous parameters and actions of candidate plans. The framework is combined with a heuristic module to estimate the best plan candidate to transit initial state to the goal based on relaxation. We repeatedly update numeric parameters and compute candidate plan until it converges to a valid plan to the planning problem. In the empirical study, we exhibit that our algorithm framework is both effective and efficient, especially when solving non-convex planning problems.
Learning Symbolic Rules for Interpretable Deep Reinforcement Learning
Mar 16, 2021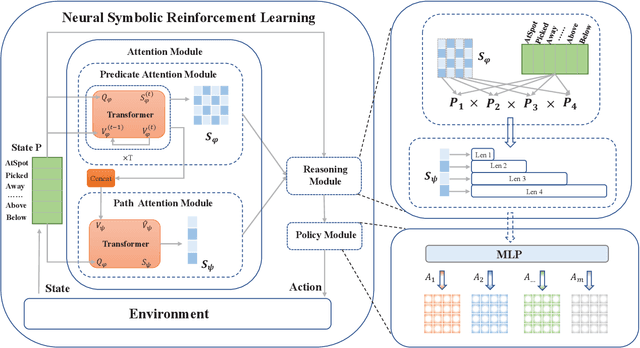

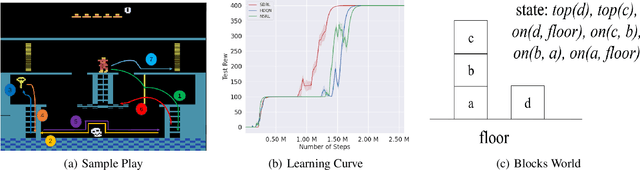
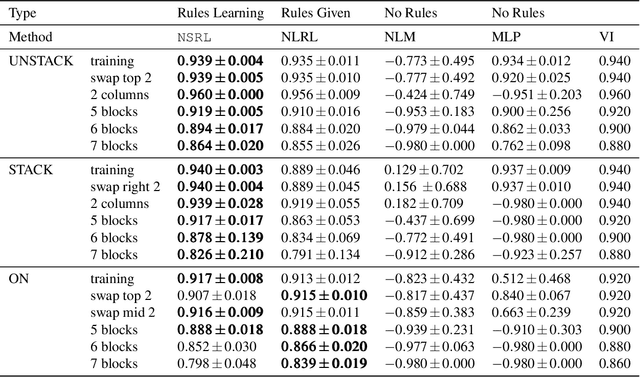
Recent progress in deep reinforcement learning (DRL) can be largely attributed to the use of neural networks. However, this black-box approach fails to explain the learned policy in a human understandable way. To address this challenge and improve the transparency, we propose a Neural Symbolic Reinforcement Learning framework by introducing symbolic logic into DRL. This framework features a fertilization of reasoning and learning modules, enabling end-to-end learning with prior symbolic knowledge. Moreover, interpretability is achieved by extracting the logical rules learned by the reasoning module in a symbolic rule space. The experimental results show that our framework has better interpretability, along with competing performance in comparison to state-of-the-art approaches.
Dual Graph Representation Learning
Feb 25, 2020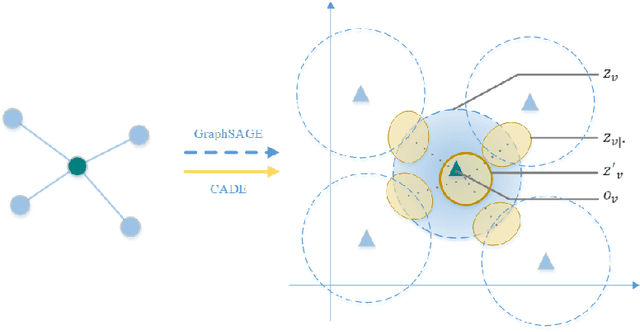
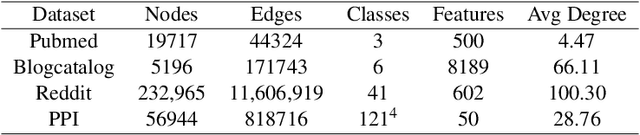
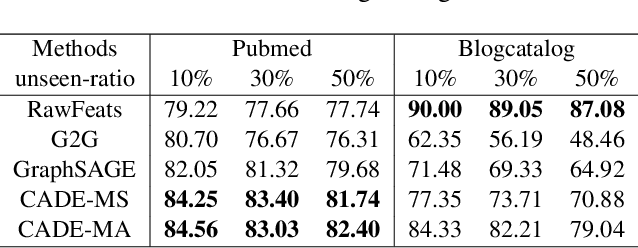
Graph representation learning embeds nodes in large graphs as low-dimensional vectors and is of great benefit to many downstream applications. Most embedding frameworks, however, are inherently transductive and unable to generalize to unseen nodes or learn representations across different graphs. Although inductive approaches can generalize to unseen nodes, they neglect different contexts of nodes and cannot learn node embeddings dually. In this paper, we present a context-aware unsupervised dual encoding framework, \textbf{CADE}, to generate representations of nodes by combining real-time neighborhoods with neighbor-attentioned representation, and preserving extra memory of known nodes. We exhibit that our approach is effective by comparing to state-of-the-art methods.