 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIGP: An LLM-Based Framework for Long-Term Value Alignment in E-Commerce Pricing
Jun 25, 2026Traditional dynamic pricing models in large-scale e-commerce suffer from limited interpretability, poor utilization of unstructured information, and misalignment with long-term business objectives such as cumulative Gross Merchandise Value (GMV), Return on Investment (ROI) and milestone achievement. We propose AIGP, a novel framework that leverages a Large Language Model (LLM) prompted with domain knowledge, structured data and textual context to make interpretable, knowledge-aware pricing decisions. For efficient deployment while maintaining high-quality outputs, we employ supervised fine-tuning for knowledge distillation. Central to AIGP is the Long-Term Value Estimator (LTVE), trained via offline reinforcement learning on historical data, which serves as a reward model to score candidate pricing actions and select preference pairs for Direct Preference Optimization (DPO), thereby aligning the pricing policy with long-term business objectives. Extensive offline evaluations and large-scale online A/B tests on Tao Factory demonstrate that AIGP achieves significant improvements: +13.21% in GMV, +7.59% in ROI, and +8.20% in milestone achievement rate over 14 days compared to the production baseline, while simultaneously providing interpretable and transparent pricing rationales.
Retrosynthetic Planning with Experience-Guided Monte Carlo Tree Search
Dec 11, 2021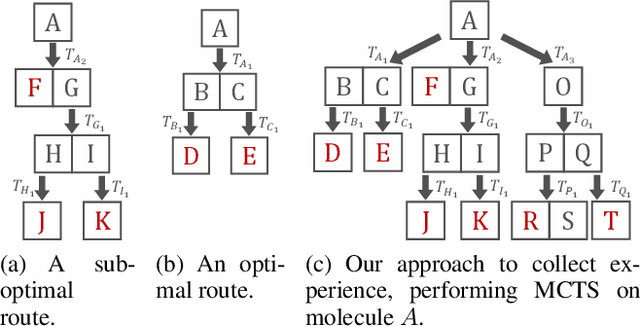
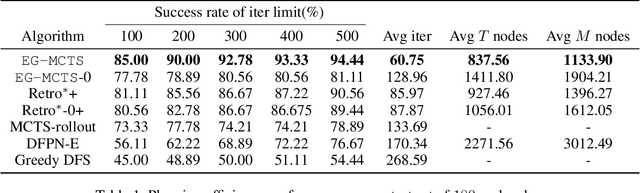
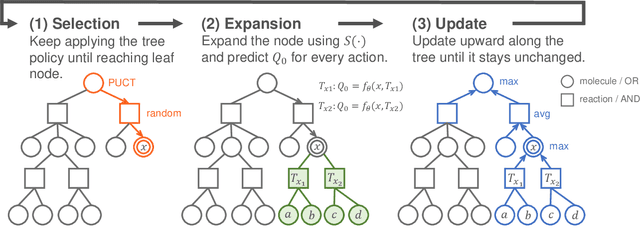
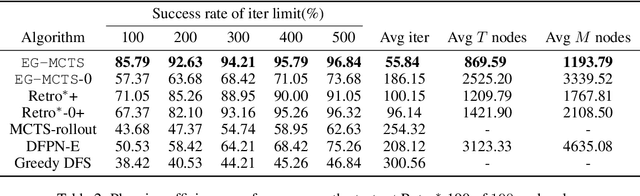
Retrosynthetic planning problem is to analyze a complex molecule and give a synthetic route using simple building blocks. The huge number of chemical reactions leads to a combinatorial explosion of possibilities, and even the experienced chemists could not select the most promising transformations. The current approaches rely on human-defined or machine-trained score functions which have limited chemical knowledge or use expensive estimation methods such as rollout to guide the search. In this paper, we propose {\tt MCTS}, a novel MCTS-based retrosynthetic planning approach, to deal with retrosynthetic planning problem. Instead of exploiting rollout, we build an Experience Guidance Network to learn knowledge from synthetic experiences during the search. Experiments on benchmark USPTO datasets show that, our {\tt MCTS} gains significant improvement over state-of-the-art approaches both in efficiency and effectiveness.