 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrosynthesis Prediction with Conditional Graph Logic Network
Jan 06, 2020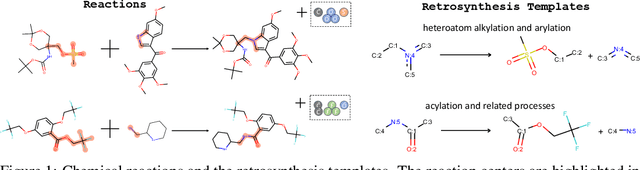
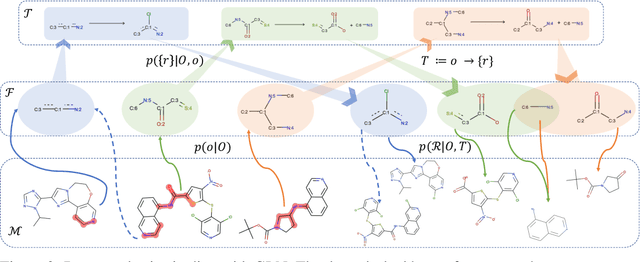
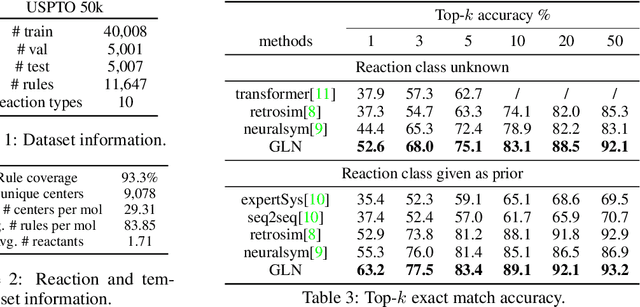
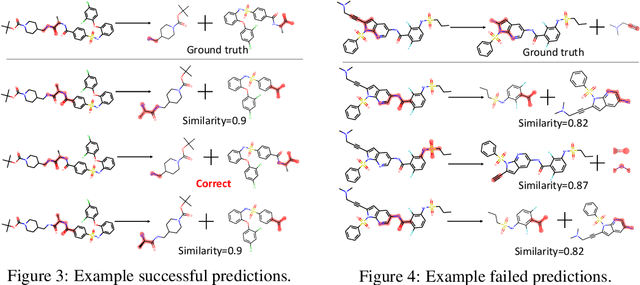
Retrosynthesis is one of the fundamental problems in organic chemistry. The task is to identify reactants that can be used to synthesize a specified product molecule. Recently, computer-aided retrosynthesis is finding renewed interest from both chemistry and computer science communities. Most existing approaches rely on template-based models that define subgraph matching rules, but whether or not a chemical reaction can proceed is not defined by hard decision rules. In this work, we propose a new approach to this task using the Conditional Graph Logic Network, a conditional graphical model built upon graph neural networks that learns when rules from reaction templates should be applied, implicitly considering whether the resulting reaction would be both chemically feasible and strategic. We also propose an efficient hierarchical sampling to alleviate the computation cost. While achieving a significant improvement of $8.1\%$ over current state-of-the-art methods on the benchmark dataset, our model also offers interpretations for the prediction.
Learning Transferable Graph Exploration
Oct 28, 2019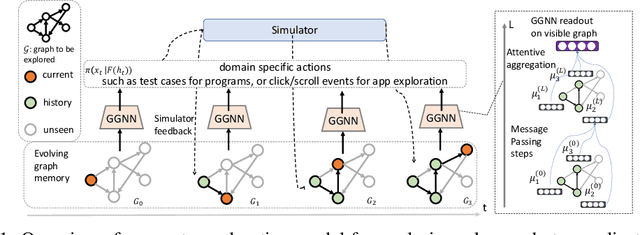
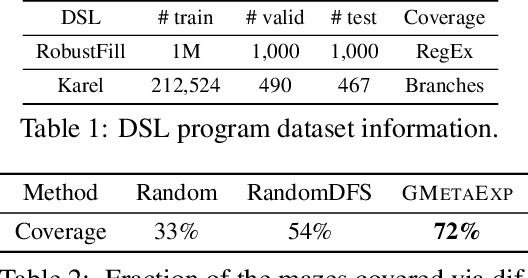


This paper considers the problem of efficient exploration of unseen environments, a key challenge in AI. We propose a `learning to explore' framework where we learn a policy from a distribution of environments. At test time, presented with an unseen environment from the same distribution, the policy aims to generalize the exploration strategy to visit the maximum number of unique states in a limited number of steps. We particularly focus on environments with graph-structured state-spaces that are encountered in many important real-world applications like software testing and map building. We formulate this task as a reinforcement learning problem where the `exploration' agent is rewarded for transitioning to previously unseen environment states and employ a graph-structured memory to encode the agent's past trajectory. Experimental results demonstrate that our approach is extremely effective for exploration of spatial maps; and when applied on the challenging problems of coverage-guided software-testing of domain-specific programs and real-world mobile applications, it outperforms methods that have been hand-engineered by human experts.
Cooperative neural networks (CoNN): Exploiting prior independence structure for improved classification
Jun 01, 2019
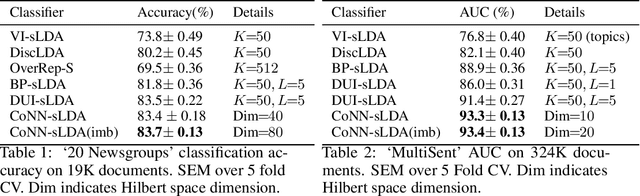
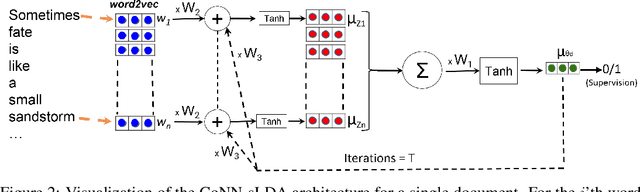
We propose a new approach, called cooperative neural networks (CoNN), which uses a set of cooperatively trained neural networks to capture latent representations that exploit prior given independence structure. The model is more flexible than traditional graphical models based on exponential family distributions, but incorporates more domain specific prior structure than traditional deep networks or variational autoencoders. The framework is very general and can be used to exploit the independence structure of any graphical model. We illustrate the technique by showing that we can transfer the independence structure of the popular Latent Dirichlet Allocation (LDA) model to a cooperative neural network, CoNN-sLDA. Empirical evaluation of CoNN-sLDA on supervised text classification tasks demonstrates that the theoretical advantages of prior independence structure can be realized in practice -we demonstrate a 23\% reduction in error on the challenging MultiSent data set compared to state-of-the-art.
Exponential Family Estimation via Adversarial Dynamics Embedding
Apr 27, 2019
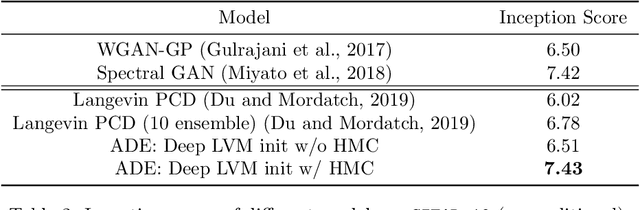
We present an efficient algorithm for maximum likelihood estimation (MLE) of the general exponential family, even in cases when the energy function is represented by a deep neural network. We consider the primal-dual view of the MLE for the kinectics augmented model, which naturally introduces an adversarial dual sampler. The sampler will be represented by a novel neural network architectures, dynamics embeddings, mimicking the dynamical-based samplers, e.g., Hamiltonian Monte-Carlo and its variants. The dynamics embedding parametrization inherits the flexibility from HMC, and provides tractable entropy estimation of the augmented model. Meanwhile, it couples the adversarial dual samplers with the primal model, reducing memory and sample complexity. We further show that several existing estimators, including contrastive divergence (Hinton, 2002), score matching (Hyv\"arinen, 2005), pseudo-likelihood (Besag, 1975), noise-contrastive estimation (Gutmann and Hyv\"arinen, 2010), non-local contrastive objectives (Vickrey et al., 2010), and minimum probability flow (Sohl-Dickstein et al., 2011), can be recast as the special cases of the proposed method with different prefixed dual samplers. Finally, we empirically demonstrate the superiority of the proposed estimator against existing state-of-the-art methods on synthetic and real-world benchmarks.
Meta Particle Flow for Sequential Bayesian Inference
Feb 02, 2019
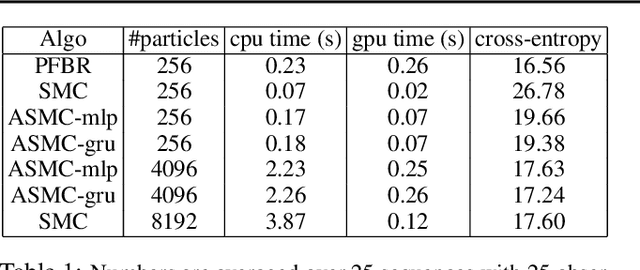

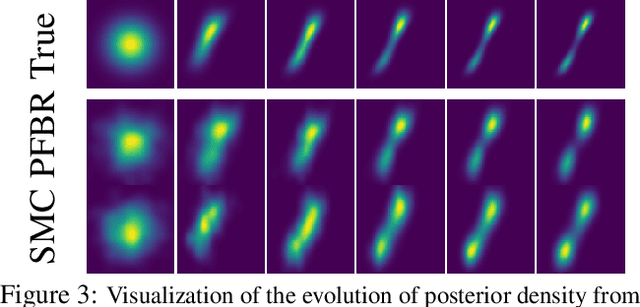
We present a particle flow realization of Bayes' rule, where an ODE-based neural operator is used to transport particles from a prior to its posterior after a new observation. We prove that such an ODE operator exists and its neural parameterization can be trained in a meta-learning framework, allowing this operator to reason about the effect of an individual observation on the posterior, and thus generalize across different priors, observations and to online Bayesian inference. We demonstrated the generalization ability of our particle flow Bayes operator in several canonical and high dimensional examples.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018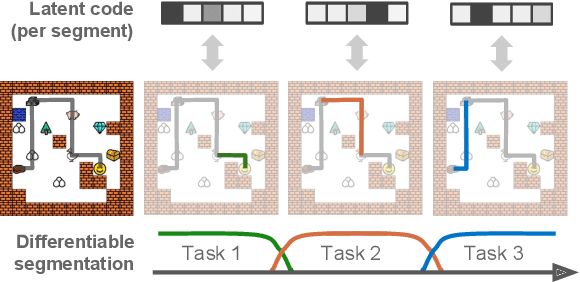
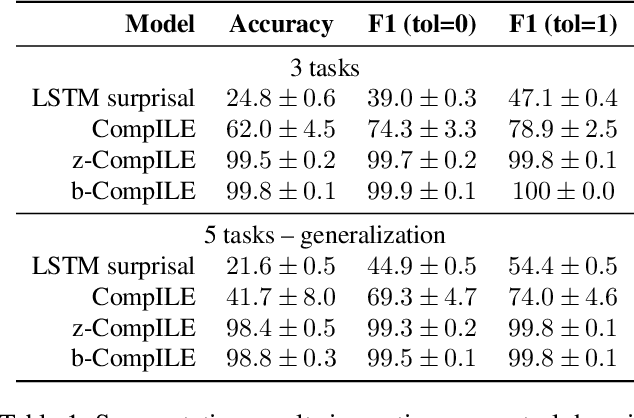
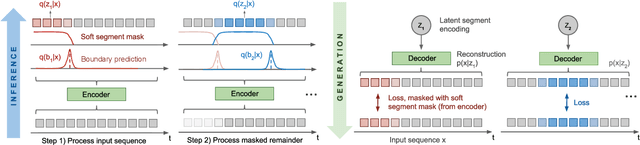
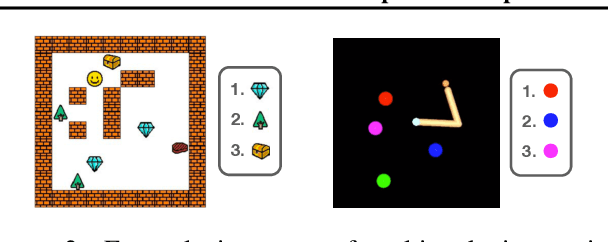
We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Kernel Exponential Family Estimation via Doubly Dual Embedding
Nov 06, 2018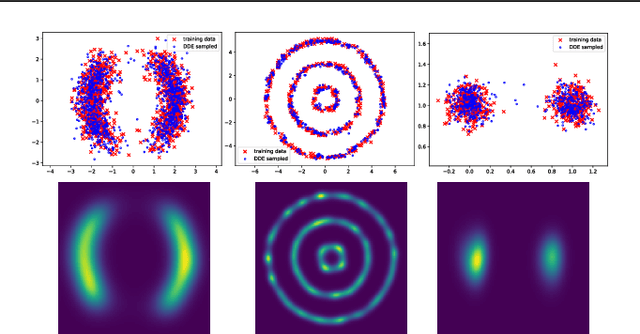
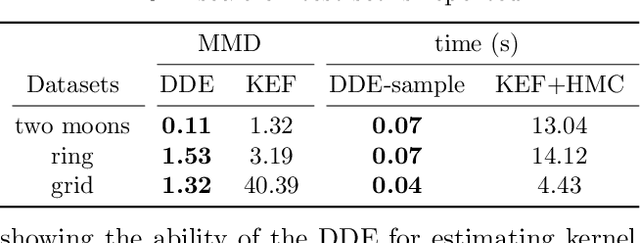
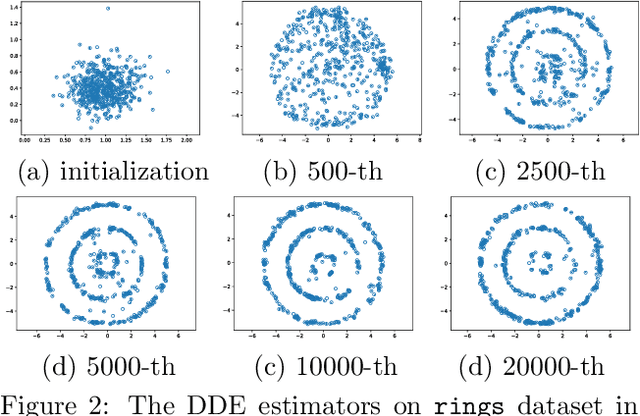
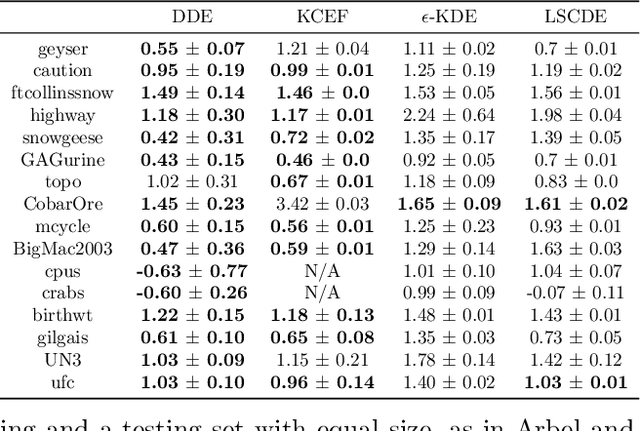
We investigate penalized maximum log-likelihood estimation for exponential family distributions whose natural parameter resides in a reproducing kernel Hilbert space. Key to our approach is a novel technique, doubly dual embedding, that avoids computation of the partition function. This technique also allows the development of a flexible sampling strategy that amortizes the cost of Monte-Carlo sampling in the inference stage. The resulting estimator can be easily generalized to kernel conditional exponential families. We furthermore establish a connection between infinite-dimensional exponential family estimation and MMD-GANs, revealing a new perspective for understanding GANs. Compared to current score matching based estimators, the proposed method improves both memory and time efficiency while enjoying stronger statistical properties, such as fully capturing smoothness in its statistical convergence rate while the score matching estimator appears to saturate. Finally, we show that the proposed estimator can empirically outperform state-of-the-art methods in both kernel exponential family estimation and its conditional extension.
Adversarial Attack on Graph Structured Data
Jun 06, 2018
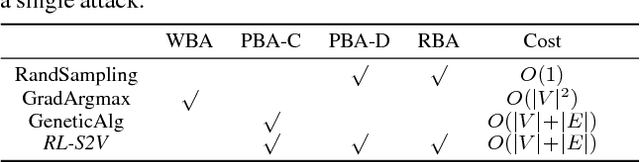
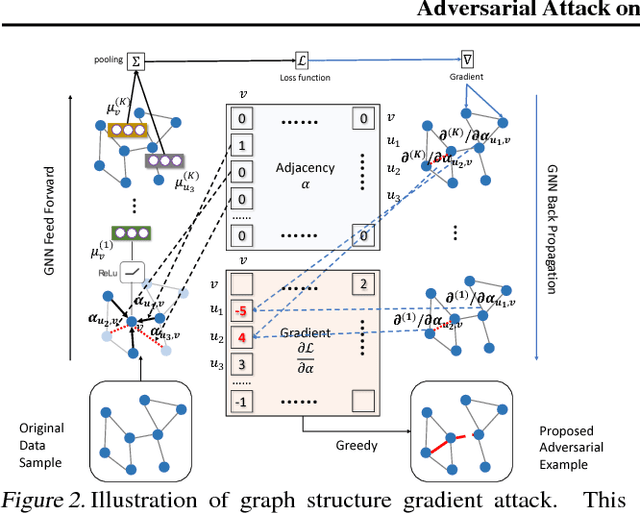
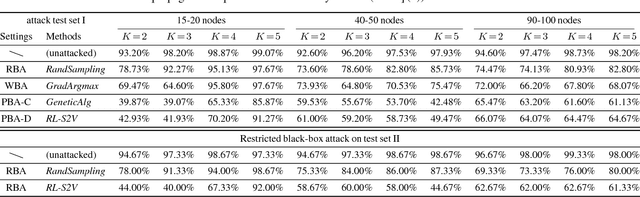
Deep learning on graph structures has shown exciting results in various applications. However, few attentions have been paid to the robustness of such models, in contrast to numerous research work for image or text adversarial attack and defense. In this paper, we focus on the adversarial attacks that fool the model by modifying the combinatorial structure of data. We first propose a reinforcement learning based attack method that learns the generalizable attack policy, while only requiring prediction labels from the target classifier. Also, variants of genetic algorithms and gradient methods are presented in the scenario where prediction confidence or gradients are available. We use both synthetic and real-world data to show that, a family of Graph Neural Network models are vulnerable to these attacks, in both graph-level and node-level classification tasks. We also show such attacks can be used to diagnose the learned classifiers.
KG^2: Learning to Reason Science Exam Questions with Contextual Knowledge Graph Embeddings
May 31, 2018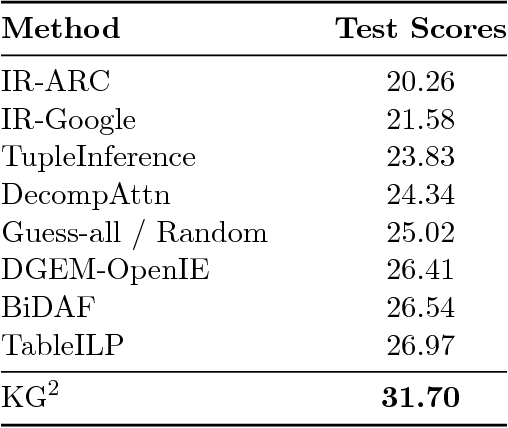
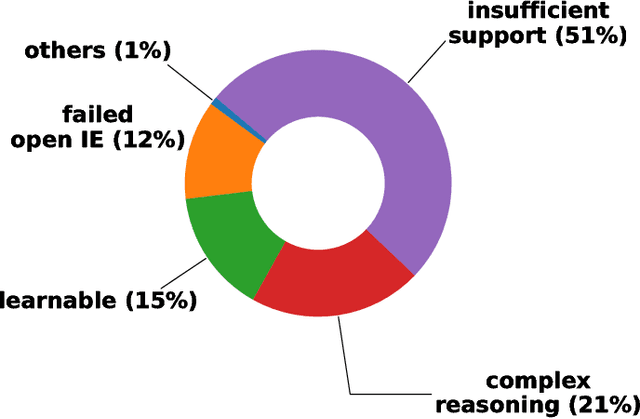
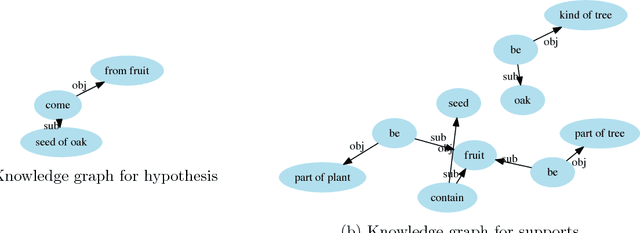
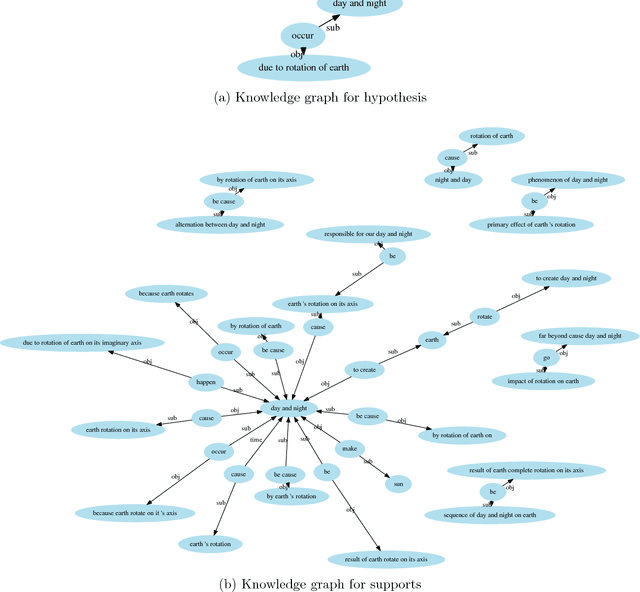
The AI2 Reasoning Challenge (ARC), a new benchmark dataset for question answering (QA) has been recently released. ARC only contains natural science questions authored for human exams, which are hard to answer and require advanced logic reasoning. On the ARC Challenge Set, existing state-of-the-art QA systems fail to significantly outperform random baseline, reflecting the difficult nature of this task. In this paper, we propose a novel framework for answering science exam questions, which mimics human solving process in an open-book exam. To address the reasoning challenge, we construct contextual knowledge graphs respectively for the question itself and supporting sentences. Our model learns to reason with neural embeddings of both knowledge graphs. Experiments on the ARC Challenge Set show that our model outperforms the previous state-of-the-art QA systems.
Syntax-Directed Variational Autoencoder for Structured Data
Feb 24, 2018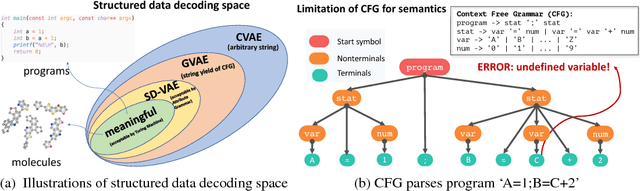
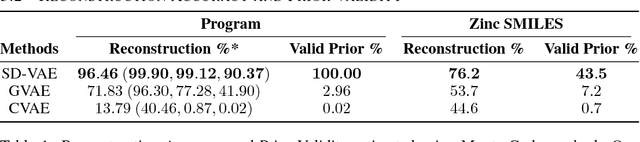
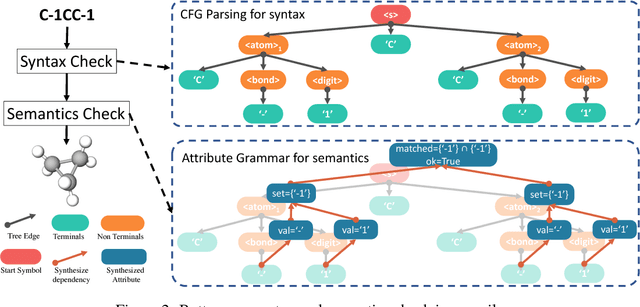
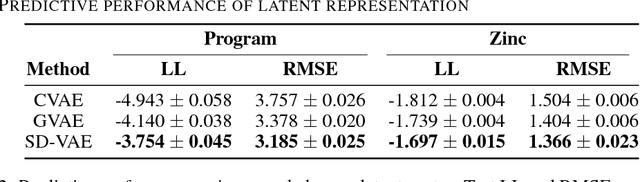
Deep generative models have been enjoying success in modeling continuous data. However it remains challenging to capture the representations for discrete structures with formal grammars and semantics, e.g., computer programs and molecular structures. How to generate both syntactically and semantically correct data still remains largely an open problem. Inspired by the theory of compiler where the syntax and semantics check is done via syntax-directed translation (SDT), we propose a novel syntax-directed variational autoencoder (SD-VAE) by introducing stochastic lazy attributes. This approach converts the offline SDT check into on-the-fly generated guidance for constraining the decoder. Comparing to the state-of-the-art methods, our approach enforces constraints on the output space so that the output will be not only syntactically valid, but also semantically reasonable. We evaluate the proposed model with applications in programming language and molecules, including reconstruction and program/molecule optimization. The results demonstrate the effectiveness in incorporating syntactic and semantic constraints in discrete generative models, which is significantly better than current state-of-the-art approaches.