 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Rec: Large Language Models for Multimodal Generative Recommendation with Causal Debiasing
Oct 02, 2025Contemporary generative recommendation systems face significant challenges in handling multimodal data, eliminating algorithmic biases, and providing transparent decision-making processes. This paper introduces an enhanced generative recommendation framework that addresses these limitations through five key innovations: multimodal fusion architecture, retrieval-augmented generation mechanisms, causal inference-based debiasing, explainable recommendation generation, and real-time adaptive learning capabilities. Our framework leverages advanced large language models as the backbone while incorporating specialized modules for cross-modal understanding, contextual knowledge integration, bias mitigation, explanation synthesis, and continuous model adaptation. Extensive experiments on three benchmark datasets (MovieLens-25M, Amazon-Electronics, Yelp-2023) demonstrate consistent improvements in recommendation accuracy, fairness, and diversity compared to existing approaches. The proposed framework achieves up to 2.3% improvement in NDCG@10 and 1.4% enhancement in diversity metrics while maintaining computational efficiency through optimized inference strategies.
AgentRec: Next-Generation LLM-Powered Multi-Agent Collaborative Recommendation with Adaptive Intelligence
Oct 02, 2025Interactive conversational recommender systems have gained significant attention for their ability to capture user preferences through natural language interactions. However, existing approaches face substantial challenges in handling dynamic user preferences, maintaining conversation coherence, and balancing multiple ranking objectives simultaneously. This paper introduces AgentRec, a next-generation LLM-powered multi-agent collaborative recommendation framework that addresses these limitations through hierarchical agent networks with adaptive intelligence. Our approach employs specialized LLM-powered agents for conversation understanding, preference modeling, context awareness, and dynamic ranking, coordinated through an adaptive weighting mechanism that learns from interaction patterns. We propose a three-tier learning strategy combining rapid response for simple queries, intelligent reasoning for complex preferences, and deep collaboration for challenging scenarios. Extensive experiments on three real-world datasets demonstrate that AgentRec achieves consistent improvements over state-of-the-art baselines, with 2.8\% enhancement in conversation success rate, 1.9\% improvement in recommendation accuracy (NDCG@10), and 3.2\% better conversation efficiency while maintaining comparable computational costs through intelligent agent coordination.
Exploring Solution Divergence and Its Effect on Large Language Model Problem Solving
Sep 26, 2025Large language models (LLMs) have been widely used for problem-solving tasks. Most recent work improves their performance through supervised fine-tuning (SFT) with labeled data or reinforcement learning (RL) from task feedback. In this paper, we study a new perspective: the divergence in solutions generated by LLMs for a single problem. We show that higher solution divergence is positively related to better problem-solving abilities across various models. Based on this finding, we propose solution divergence as a novel metric that can support both SFT and RL strategies. We test this idea on three representative problem domains and find that using solution divergence consistently improves success rates. These results suggest that solution divergence is a simple but effective tool for advancing LLM training and evaluation.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification
Jun 13, 2025



Recent advances in reinforcement learning (RL) with verifiable outcome rewards have significantly improved the reasoning capabilities of large language models (LLMs), especially when combined with multi-turn tool interactions. However, existing methods lack both meaningful verification signals from realistic environments and explicit optimization for verification, leading to unreliable self-verification. To address these limitations, we propose ReVeal, a multi-turn reinforcement learning framework that interleaves code generation with explicit self-verification and tool-based evaluation. ReVeal enables LLMs to autonomously generate test cases, invoke external tools for precise feedback, and improves performance via a customized RL algorithm with dense, per-turn rewards. As a result, ReVeal fosters the co-evolution of a model's generation and verification capabilities through RL training, expanding the reasoning boundaries of the base model, demonstrated by significant gains in Pass@k on LiveCodeBench. It also enables test-time scaling into deeper inference regimes, with code consistently evolving as the number of turns increases during inference, ultimately surpassing DeepSeek-R1-Zero-Qwen-32B. These findings highlight the promise of ReVeal as a scalable and effective paradigm for building more robust and autonomous AI agents.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Modeling and Performance Analysis for Semantic Communications Based on Empirical Results
Apr 29, 2025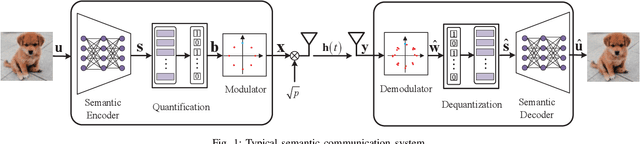
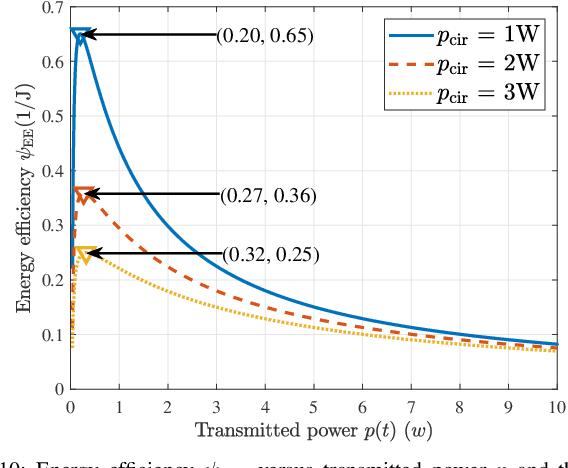
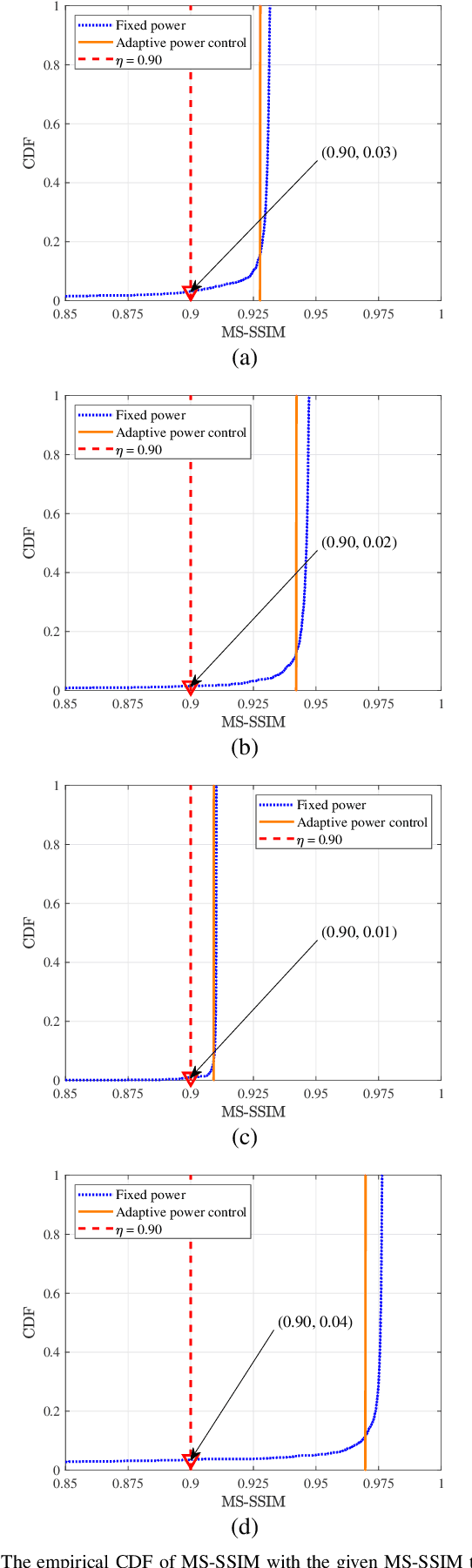
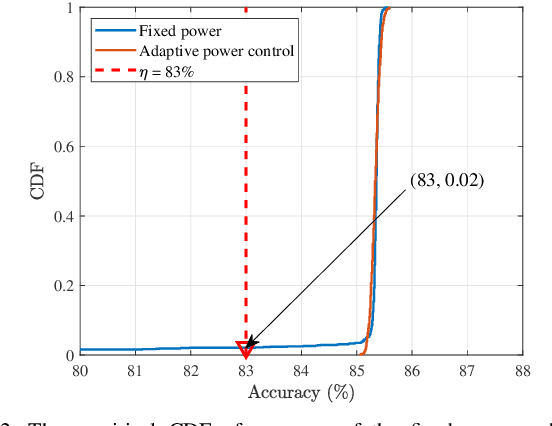
Due to the black-box characteristics of deep learning based semantic encoders and decoders, finding a tractable method for the performance analysis of semantic communications is a challenging problem. In this paper, we propose an Alpha-Beta-Gamma (ABG) formula to model the relationship between the end-to-end measurement and SNR, which can be applied for both image reconstruction tasks and inference tasks. Specifically, for image reconstruction tasks, the proposed ABG formula can well fit the commonly used DL networks, such as SCUNet, and Vision Transformer, for semantic encoding with the multi scale-structural similarity index measure (MS-SSIM) measurement. Furthermore, we find that the upper bound of the MS-SSIM depends on the number of quantized output bits of semantic encoders, and we also propose a closed-form expression to fit the relationship between the MS-SSIM and quantized output bits. To the best of our knowledge, this is the first theoretical expression between end-to-end performance metrics and SNR for semantic communications. Based on the proposed ABG formula, we investigate an adaptive power control scheme for semantic communications over random fading channels, which can effectively guarantee quality of service (QoS) for semantic communications, and then design the optimal power allocation scheme to maximize the energy efficiency of the semantic communication system. Furthermore, by exploiting the bisection algorithm, we develop the power allocation scheme to maximize the minimum QoS of multiple users for OFDMA downlink semantic communication Extensive simulations verify the effectiveness and superiority of the proposed ABG formula and power allocation schemes.
Enhancing LLM-Based Short Answer Grading with Retrieval-Augmented Generation
Apr 07, 2025



Short answer assessment is a vital component of science education, allowing evaluation of students' complex three-dimensional understanding. Large language models (LLMs) that possess human-like ability in linguistic tasks are increasingly popular in assisting human graders to reduce their workload. However, LLMs' limitations in domain knowledge restrict their understanding in task-specific requirements and hinder their ability to achieve satisfactory performance. Retrieval-augmented generation (RAG) emerges as a promising solution by enabling LLMs to access relevant domain-specific knowledge during assessment. In this work, we propose an adaptive RAG framework for automated grading that dynamically retrieves and incorporates domain-specific knowledge based on the question and student answer context. Our approach combines semantic search and curated educational sources to retrieve valuable reference materials. Experimental results in a science education dataset demonstrate that our system achieves an improvement in grading accuracy compared to baseline LLM approaches. The findings suggest that RAG-enhanced grading systems can serve as reliable support with efficient performance gains.
LLM-based Automated Grading with Human-in-the-Loop
Apr 07, 2025The rise of artificial intelligence (AI) technologies, particularly large language models (LLMs), has brought significant advancements to the field of education. Among various applications, automatic short answer grading (ASAG), which focuses on evaluating open-ended textual responses, has seen remarkable progress with the introduction of LLMs. These models not only enhance grading performance compared to traditional ASAG approaches but also move beyond simple comparisons with predefined "golden" answers, enabling more sophisticated grading scenarios, such as rubric-based evaluation. However, existing LLM-powered methods still face challenges in achieving human-level grading performance in rubric-based assessments due to their reliance on fully automated approaches. In this work, we explore the potential of LLMs in ASAG tasks by leveraging their interactive capabilities through a human-in-the-loop (HITL) approach. Our proposed framework, GradeHITL, utilizes the generative properties of LLMs to pose questions to human experts, incorporating their insights to refine grading rubrics dynamically. This adaptive process significantly improves grading accuracy, outperforming existing methods and bringing ASAG closer to human-level evaluation.
LLM-VPRF: Large Language Model Based Vector Pseudo Relevance Feedback
Apr 02, 2025Vector Pseudo Relevance Feedback (VPRF) has shown promising results in improving BERT-based dense retrieval systems through iterative refinement of query representations. This paper investigates the generalizability of VPRF to Large Language Model (LLM) based dense retrievers. We introduce LLM-VPRF and evaluate its effectiveness across multiple benchmark datasets, analyzing how different LLMs impact the feedback mechanism. Our results demonstrate that VPRF's benefits successfully extend to LLM architectures, establishing it as a robust technique for enhancing dense retrieval performance regardless of the underlying models. This work bridges the gap between VPRF with traditional BERT-based dense retrievers and modern LLMs, while providing insights into their future directions.